Die Informationspraxis war eine Zeitschrift für Bibliotheken, Informationseinrichtungen und vergleichbare Einrichtungen, welche von 2015 bis 2022 erschien. Sie war auf den deutschsprachigen Raum ausgerichtet (explizit stand hinter der Zeitschrift ein schweizerischer Verein, wenn auch der Grossteil der Redaktion in Deutschland arbeitete) und erschien – wie alle vergleichbaren Zeitschriften, die in dieser Zeit gegründet wurden – als reine Open Access Zeitschrift. Gleichzeitig versuchte sie, Abläufe zu verändern – die Redaktion wollte nicht einfach eine «weitere Zeitschrift» machen, sondern Neues ausprobieren. Das zeigte sich vor allem am Open Peer Review, bei dem Artikel in einer ersten Version im Blog des Zeitschrift publiziert wurden, dort offen kommentiert werden konnten, diese Kommentare gesammelt und an die Autor*innen zurückgemeldet wurden, welche darauf (und auf Kommentare der Redaktion) reagierten, bevor die endgültige Fassung des jeweiligen Artikels erschien. (In meiner Erfahrung als Autor gab es allerdings immer wenige Kommentare, ausserdem lernte die Redaktion, dass es manchmal wichtig ist, sich «dazwischenzuschalten», da einige Leute halt nicht wissen, wie man potentialorientiert kommentiert.) Als Redaktionssystem wurde OJS genutzt – das wird kurz weiter unten relevant werden.
Die Redaktion beendete die Zeitschrift mit einem ganz kurzen Hinweis auf der Homepage. Es gab keine abschliessenden Text. Soweit ich das sehe, hat auch niemand sonst einen Nachruf oder Ähnliches veröffentlicht, abgesehen von einigen Social Media Kommentaren, die Bedauern über das Ende ausdrückten. Auch dieser Text hier wird nicht darüber reflektieren, warum die Zeitschrift eingestellt wurde und was dies (vielleicht) über das Bibliothekswesen im DACH-Raum sagt. Ich denke, dass müsste jemand machen, die*der die ganze Zeit in der Redaktion gewesen ist. (Was möglich wäre: Die «Laufzeit» von acht Jahren, scheint mir, wäre eine gute Voraussetzung für so eine Reflexion. Lang genug, als das es Veränderungen gab, aber kurz genug, um diese Zeit vollständig zu Überblicken.)
Aber die Informationspraxis stellt auch eine Chance dar: Es gibt mit ihr eine «abgeschlossene» Sammlung an Texten aus dem Bibliothekswesen, relativ aktuell, ausgewählt und bearbeitet von einer fachspezifischen Redaktion. Es sind ausreichend viele Texte, um aus ihnen einige Statistiken abzuleiten und etwas Textmining zu betreiben. (Es sind nicht wirklich genug für komplexere Textmining-Modelle. Das wird weiter unten noch thematisiert werden.) Und das soll hier, anstatt eines Nachrufs, geliefert werden: Die Informationspraxis wird als Datensatz behandelt und einige statische Daten über sie dargestellt. (Die Nutzungs-/Abrufstatistiken sind nicht darunter – die liegen wohl im OJS selber und müssten von der ehemaligen Redaktion veröffentlicht werden. In der «Geschichte» der Zeitschrift ist das auch passiert (https://informationspraxis.de/2019/01/07/der-informationspraxis-lesebericht-2018/), aber nicht bei ihrem Ende.)
Aufgebaut ist der Beitrag wie folgt: im nächsten Abschnitt (1) wird kurz die «technische» Seite beschrieben – also, wie die Daten für diesen Beitrag hier gesammelt, aufbereitet und verarbeitet wurden. Wer das nicht unbedingt wissen will, kann den getrost überspringen. Anschliessend (2) werden einige Statistiken über die Zeitschrift selber dargestellt. Hier geht es dann vor allem um die Anzahl der Ausgaben oder die Zahl der Autor*innen. Dann geht es ans Textmining, also an die Frage, was sich auf statistische Weise aus den eigentlichen Beiträge herauslesen lässt. Unterteilt ist dies nochmal in einfache Statistiken (3) wie die Auszählung der Worte, die verwendet wurden und komplexere Statistiken (4), die etwas tiefer in die Materien gehen. Wie wohl zu erwarten wird dann in einem abschliessenden Abschnitt (5) versucht, einige Schlüsse zu ziehen und mögliche weitere Fragen aufzuzeigen. In einem kurzen Nachwort (6) gehe ich dann doch noch mal auf meine abschliessende Bewertung der Informationspraxis ein – wie im Abschnitt 2 sichtbar wird, war ich erstaunlicherweise einer der «Top-Autor*innen», was mich doch zu einem Kommentar drängt.
Alle Daten hier im Beitrag können heruntergeladen werden und stehen unter einer CC BY NC 4.0-Lizenz.
1. R, Datascrapping und spezialisierte Libraries – zur «technischen» Seite
Alle Daten und Statistiken, die weiter unten dargestellt werden, sind mit der Statistiksprache R produziert worden. (Verwendet wurde Version 4.2.2 in R-Studio Version 2023.09.01.) Die verwendeten Libraries waren auf die jeweils neueste Version geupdatet. Das ganze Projekt war auch ein Experiment dazu, was heute mit diesen recht einfachen Mitteln möglich ist. Das ganze nahm vielleicht drei Arbeitstage (verteilt über eine Woche in den Stunden «nebenher») in Anspruch. Deshalb war / ist auch vieles handgestrickt und nicht perfekt, sondern experimentell. Kolleg*innen in den Digital Humanities, die sich ständig mit Textmining und Ähnlichem beschäftigen, werden selbstverständlich viel schneller zu den gleichen Ergebnissen gelangen und dann auch zu viel differenzierten, besseren. Es sollte als Experiment verstanden werden, aber eines, dass sich auch von anderen Personen recht einfach reproduzieren lässt. (Ein Experiment, dass auch davon motiviert ist, dass ein Kollege aus der ehemaligen Redaktion der Informationspraxis oft davon gesprochen hat, wenn wir das paraphrasieren, «einmal was mit Data- und Textmining machen zu wollen». Da erschien es nur passend, dass an der Zeitschrift selber durchzuführen, nachdem sie eine «abgeschlossene Sammlung» wurde.)
Ermöglicht wurde dies durch zwei Fakten:
- Die Informationspraxis erschien, wie gesagt, kontinuierlich im Open Access (mit CC BY 4.0) und auf einem OJS. Das heisst, erstens sind die Daten strukturiert (weil sie aus dem OJS strukturiert ausgegeben werden, zumindest wenn dort nicht viel verändert wird – was die Informationspraxis nicht tat) und zweitens sind die Rechte geklärt: Die Texte dürfen für ein Text,ining verwendet werden.
- Datamining, auch auf der Basis von Artikeln und Zeitschriften, die auf einem OJS veröffentlicht wurden, stellen in gewisser Weise Standardaufgaben dar. Es gibt für sie schon etablierte Libraries (nicht nur, aber auch für R), die dafür einfach verwendet werden konnten. In unserem Fall waren dies ojsr (https://www.rdocumentation.org/packages/ojsr/versions/0.1.2) für das Einlesen der Metadaten von der Homepage, rvest (https://www.rdocumentation.org/packages/rvest/versions/1.0.3) für das Textscrapping der Volltexte und quanteda (https://quanteda.io), inklusive der «Unterpackages» für textstats, textplots und textmodels, für das Textmining.
Vorgegangen wurde nun, in gewisser Weise auch schon standardisiert, wie folgt:
- Zuerst wurden mithilfe von ojsr die gesamten Metadaten der Informationspraxis eingelesen. Das ist genau die Aufgabe, für welche dieses Paket geschrieben wurde. (Es funktioniert auch mit allen anderen Zeitschriften, die auf OJS gehostet werden, solange sie die grundlegende Metadatenstruktur beibehalten.) Insoweit war es direkt aus dem in der Beschreibung des Pakets gegebenen Beispiel umsetzbar.
- Ebenso direkt und einfach umsetzbar war das Scrapping der eigentliche Volltexte. Hierzu wurden die URLs, die in den Daten aus dem ersten Schritt enthalten waren, genutzt, um dann mit dem Paket rvest die gesamten HTML-Inhalte aller Artikel der Informationspraxis herunterzuladen und dann so umzuformatieren, dass sie weiterverarbeitet werden konnten.
- Anschliessend wurden die Daten zusammengeführt und, beispielsweise, die jedem Artikel beigegebene Unterzeile «Informationspraxis mitgestalten?Hier steht, wie’s geht!» gelöscht. Am Ende stand ein Datensatz, in welchem für jeden Artikel in einer Zeile Metadaten, eine eindeutige Kennung und – jeweils in einer Zelle – der gesamte Text stand. [Die eindeutige Kennung besteht aus einer durchlaufen Zahl und dem Beginn der bibliographischen Angaben. Die gesamten bibliographischen Angaben waren in den Graphiken nicht zu lesen. Am Ende dieses Artikels findet sich aber eine Tabelle, welche diese Kennung und die bibliographischen Angaben darstellt, sodass auch auf einzelne Artikel zurückgeschlossen werden kann.] Dieses Format – genauer: eine Tabelle mit Volltext und Identifier – war notwendig für die Weiterverarbeitung mit dem Paket quanteda.
- In einem ersten Schritt der Analyse wurde mit den reinen Metadaten gearbeitet. Es wurde in jeweils kleineren Datensätzen zusammengefasst, welche Autor*innen die Artikel der Informationspraxis hatten, wie viele Ausgaben es gab etc. Auch hiermit liess sich schon ein interessanter Überblick erarbeiten, welcher weiter unten in Abschnitt 2 dargestellt ist.
- Anschliessend wurde das Textmining durchgeführt. Für dieses gibt es eine ganze Anzahl von Paket in R. Gewählt wurde, weil ich schon von einigen früheren Versuchen ein wenig mit ihm vertraut war und weil es in der Literatur zum Textmining immer wieder erwähnt wird, das Paket quanteda. Dieses bietet Funktionen, um sehr einfach Textmining durchzuführen – doch wie immer bei solchen Paketen übernimmt es die Arbeit, nicht aber die konkrete Interpretation der Daten. Zuerst wurden die Daten in einen Corpus umgewandelt, mit dem dann weitergearbeitet werden konnte. Das ist der Teil, für den die Datenstruktur Identifier und Volltext notwendig war. (Diese werden in eine Struktur umgearbeitet, in denen der Text in einen Container liegt, der Identifier auf ihn verweist und dann die anderen Metadaten, die vielleicht auch in den Tabelle liegen – beispielsweise in unserem Fall die Erscheinungsjahre der Artikel – als Kategorien angelegt sind.) Und dann wurden die verschiedenen Möglichkeiten des Textminings, die quanteda bietet «durchgespielt». Nicht alle ergaben sinnvoll interpretierbare Daten und selbstverständlich kann man immer weiter hinter die Möglichkeiten, die das Paket bietet, steigen. Was hier in Abschnitt 3 präsentiert wird, sind die Ergebnisse, die im Laufe dieses Experiments erstellt wurde und präsentabel erschienen. (Aber der Quellcode ist auch am Ende des Beitrags als Datei eingefügt, so dass alle ihn nachvollziehen, selber «laufen lassen» und gerne auch erweitern / verändern dürfen.)
- Für die Darstellung der Daten und Plots hier wird in vielen Fällen das WordPress-Plugin wpDataTables (https://wpdatatables.com) verwendet. Die anderen Plots wurden direkt in R erstellt.
2. «Einfache» Statistiken
Im Laufe ihres Bestehens publizierte die Informationspraxis 83 Artikel – Editorials eingeschlossen – in vierzehn Ausgaben. (Dabei wurden Ausgaben ab einem bestimmten Zeitpunkt «laufend» publiziert, also alle Beiträge wurden publiziert, wenn sie fertig waren, aber alle halben Jahre wurden die Ausgaben «abgeschlossen».) Die Verteilung der Beiträge über die Jahre ergibt sich aus der folgenden Graphik.
Dabei zeigt sich, dass die Zahl der Beiträge über die Ausgaben ungleich verteilt war. Erstaunlich ist vielleicht, dass es keine Trend dahin gibt, dass in den späteren Ausgaben weniger Texte veröffentlicht wurden, als in den früheren. Die kürzeste Ausgabe (2/2019) mit einem Text erschien fast in der Mitte der «Laufzeit» der Zeitschrift.
Insgesamt wurden diese Beiträge von 176 Autor*innen verantwortet, oft in Teams. Allerdings publizierten die meisten nur einmal. Es gab ein gewisses «Kernteam»: Stellt man nur diejenigen Autor*innen da, die mindestens dreimal publizierten, zeigt sich dies direkt. Dabei muss man beachten, dass drei der «Hauptautor*innen» unter diesen acht direkt der Redaktion angehörten, also auch redaktionelle Beiträge verantworten. (Etwas überraschend (für mich) war ich der Autor mit den meisten Publikationen, der nicht aus dem Kreis der Redaktion stammt. Das war nicht so geplant.)
| index | meta_data_content | n |
|---|---|---|
| 1 | Christian Hauschke | 14 |
| 2 | Karsten Schuldt | 8 |
| 3 | Rudolf Mumenthaler | 7 |
| 4 | Gabriele Fahrenkrog | 6 |
| 5 | Graham Triggs | 3 |
| 6 | Grischa Fraumann | 3 |
| 7 | Lambert Heller | 3 |
| 8 | Tatiana Walther | 3 |
| 9 | Adrian Pohl | 2 |
| 10 | Armin Talke | 2 |
| 11 | Arvid Deppe | 2 |
| 12 | Bernhard Mittermaier | 2 |
| 13 | Christian Mathieu | 2 |
| 14 | Daniel Schunk | 2 |
| 15 | Dörte Böhner | 2 |
| 16 | Fabian Steeg | 2 |
| 17 | Felix Lohmeier | 2 |
| 18 | Nicole Eichenberger | 2 |
| 19 | Pascal Christoph | 2 |
| 20 | Ute Engelkenmeier | 2 |
| 21 | Alessandro Blasetti | 1 |
| 22 | Alexander Grossmann | 1 |
| 23 | Alexandra Jobmann | 1 |
| 24 | Alexandra Svantje Linhart | 1 |
| 25 | Aloys Krieg | 1 |
| 26 | Andrea Hofmann | 1 |
| 27 | Andreas Ledl | 1 |
| 28 | Anette Cordts | 1 |
| 29 | Angela Oehler | 1 |
| 30 | Anita Eppelin | 1 |
| 31 | Ann Christin Wild | 1 |
| 32 | Azra Bekiri | 1 |
| 33 | Barbara Grossmann | 1 |
| 34 | Barbara Heindl | 1 |
| 35 | Barbara Knorn | 1 |
| 36 | Beat Mattmann | 1 |
| 37 | Belinda Jopp | 1 |
| 38 | Berfu Erdogan | 1 |
| 39 | Bernard Bekavac | 1 |
| 40 | Bruno Wüthrich | 1 |
| 41 | Christian Erlinger | 1 |
| 42 | Christian Kaier | 1 |
| 43 | Christian Koller | 1 |
| 44 | Christian Schneevogt | 1 |
| 45 | Christian Wilke | 1 |
| 46 | Christina Riesenweber | 1 |
| 47 | Christina Schmitz | 1 |
| 48 | Christof Rodejohann | 1 |
| 49 | Christoph Hornung | 1 |
| 50 | Christopher Hanna Johnson | 1 |
| 51 | Claudia Frick | 1 |
| 52 | Colette Knight | 1 |
| 53 | Corinna Haas | 1 |
| 54 | Cristina Magder | 1 |
| 55 | Dagmar Schnittker | 1 |
| 56 | Daniel Brenn | 1 |
| 57 | Daniel Beucke | 1 |
| 58 | Daniel Fischer | 1 |
| 59 | Daniel Hürlimann | 1 |
| 60 | Daniel Nüst | 1 |
| 61 | Denise Sievers | 1 |
| 62 | Diana Hamasur | 1 |
| 63 | Dominic Göhring | 1 |
| 64 | Dominik Feldschnieders | 1 |
| 65 | Dorothea Strecker | 1 |
| 66 | Ebru Kurtar | 1 |
| 67 | Eckhart Arnold | 1 |
| 68 | Elena Liventsova | 1 |
| 69 | Elias Entrup | 1 |
| 70 | Elke Dittmer | 1 |
| 71 | Erich Grevelding | 1 |
| 72 | Fabian Gail | 1 |
| 73 | Frank Waldschmidt-Dietz | 1 |
| 74 | Franziska Altemeier | 1 |
| 75 | Gary Seitz | 1 |
| 76 | Gudrun Nelson-Busch | 1 |
| 77 | Heidi Meyer | 1 |
| 78 | Heinz-Jürgen Bove | 1 |
| 79 | Heribert Nacken | 1 |
| 80 | Hervé L’Hours | 1 |
| 81 | Ina Blümel | 1 |
| 82 | Indra Heinrich | 1 |
| 83 | Irene Barbers | 1 |
| 84 | Jakob Voß | 1 |
| 85 | Jan Jäger | 1 |
| 86 | Jana Hentschke | 1 |
| 87 | Jana Mersmann | 1 |
| 88 | Jennifer Wiegand | 1 |
| 89 | Jens Ambacher | 1 |
| 90 | Jens Bemme | 1 |
| 91 | Jens Kösters | 1 |
| 92 | Jin Chei | 1 |
| 93 | Joanna Einbock | 1 |
| 94 | Jochen Haug | 1 |
| 95 | Johannes Hafner | 1 |
| 96 | Jonas Wäber | 1 |
| 97 | Jürgen Enge | 1 |
| 98 | Katharina Schulz | 1 |
| 99 | Kim Peters | 1 |
| 100 | Laura Bode | 1 |
| 101 | Laura Isbanner | 1 |
| 102 | Lea Maria Ferguson | 1 |
| 103 | Leander Seige | 1 |
| 104 | Marcel Wrzesinski | 1 |
| 105 | Marco Humbel | 1 |
| 106 | Marina Unger | 1 |
| 107 | Mark Vetter | 1 |
| 108 | Markus Trapp | 1 |
| 109 | Markus Putnings | 1 |
| 110 | Markus Trapp | 1 |
| 111 | Martin Munke | 1 |
| 112 | Martin Wollschläger-Tigges | 1 |
| 113 | Márton Villányi | 1 |
| 114 | Matti Stöhr | 1 |
| 115 | Maxi Kindling | 1 |
| 116 | Melis Rufaioglu | 1 |
| 117 | Meltem Dincer | 1 |
| 118 | Michaela Voigt | 1 |
| 119 | Nadin Kroll | 1 |
| 120 | Nele Leiner | 1 |
| 121 | Nicolas Bach | 1 |
| 122 | Nicole Petri | 1 |
| 123 | Niels Taubert | 1 |
| 124 | Nina Schönfelder | 1 |
| 125 | Nina Weisweiler | 1 |
| 126 | Oliver Sievi | 1 |
| 127 | Pascal Ngoc Phu Tu | 1 |
| 128 | Paul Vierkant | 1 |
| 129 | Petra Kohorst | 1 |
| 130 | Petra Schön | 1 |
| 131 | Philipp Zumstein | 1 |
| 132 | Qazi Asim Ijaz Ahmad | 1 |
| 133 | Ralf Stockmann | 1 |
| 134 | Regina Retter | 1 |
| 135 | Remziye Yildirimer | 1 |
| 136 | Robert Zepf | 1 |
| 137 | Roberto Cozatl | 1 |
| 138 | Romy Stelter | 1 |
| 139 | Ronnie Vogt | 1 |
| 140 | Rouven Schabinger | 1 |
| 141 | Ruth Schaffer Wüthrich | 1 |
| 142 | Sabine Stummeyer | 1 |
| 143 | Sabine Thänert | 1 |
| 144 | Sabrina Zaugg | 1 |
| 145 | Salome Zehnder | 1 |
| 146 | Sandra Golda | 1 |
| 147 | Sarah Dellmann | 1 |
| 148 | Sebastian Meyer | 1 |
| 149 | Seta Štuhec | 1 |
| 150 | Sigrid Freudl | 1 |
| 151 | Simon Schultze | 1 |
| 152 | Sinan Meral | 1 |
| 153 | Sonja Rosenberger | 1 |
| 154 | Sonja Schulze | 1 |
| 155 | Sophie Schneider | 1 |
| 156 | Stefan Bielesch | 1 |
| 157 | Stefan Müller | 1 |
| 158 | Stefan Schmeja | 1 |
| 159 | Stefanie Hanneken | 1 |
| 160 | Stefanie Spiegelberg | 1 |
| 161 | Steffi Grimm | 1 |
| 162 | Steffi Schulz | 1 |
| 163 | Susann Özüyaman | 1 |
| 164 | Susanne Baudisch | 1 |
| 165 | Svantje Lilienthal | 1 |
| 166 | Sylvia Hulin | 1 |
| 167 | Tabea Lurk | 1 |
| 168 | Tamara Mansaray | 1 |
| 169 | Thomas Kahlisch | 1 |
| 170 | Thomas Mutschler | 1 |
| 171 | Tim Schumann | 1 |
| 172 | Tina Grahl | 1 |
| 173 | Tracy Hoffmann | 1 |
| 174 | Ulrike Kändler | 1 |
| 175 | Vrushali Wyssmann | 1 |
| 176 | Wolf Christoph Seifert | 1 |
Ohne Vergleich mit anderen Zeitschriften ist nicht klar, wie man diese Werte interpretieren soll. Aber es scheint, als wenn es nicht einfach war, Autor*innen zu mehr als einem Beitrag zu bewegen.
Die Beiträge wurden in der Informationspraxis in fünf verschiedenen Rubriken veröffentlicht: Fachbeiträge, Kurzberichte, Berichte / Kritik, Editorial und Preprints. Diese Kategorien sind in dem Metadaten hinterlegt und lassen sich deshalb auch darstellen.
Sichtbar wird hier, dass die Fachbeiträge fast 50% darstellten, die Informationspraxis also als Fachzeitschrift gelten kann. Gleichzeitig fällt auf, dass die Zeitschrift oft darauf verzichtete, ein eigenständiges Editorial zu publizieren. Im Gegensatz zu anderen Zeitschriften, die dies in jeder Ausgabe tun, passierte dies nur manchmal.
Alle Beiträge wurden mit Keywords ausgezeichnet, insgesamt 104. Allerdings helfen diese Keywords nicht dabei, Trends bei den Themen, über die publiziert wurde, zu identifizieren. Gerade einmal vier von ihnen wurden mehr als einmal benutzt.
| index | meta_data_content | n |
|---|---|---|
| 1 | Open Access | 5 |
| 2 | DFG | 2 |
| 3 | Digitalisierung | 2 |
| 4 | Open-Access-Transformation | 2 |
| 5 | #vBIB20 | 1 |
| 6 | #vBIB21 | 1 |
| 7 | 3D-Digitalisierung | 1 |
| 8 | Arbeitsthemen und -aufträge | 1 |
| 9 | Article Processing Charge | 1 |
| 10 | Bericht | 1 |
| 11 | Bewegungsbuch | 1 |
| 12 | Bibliotheks-IT | 1 |
| 13 | Bibliotheksnutzung | 1 |
| 14 | Bibliotheksstatistik | 1 |
| 15 | Book Sprint | 1 |
| 16 | Citizen Science | 1 |
| 17 | Community | 1 |
| 18 | Corona | 1 |
| 19 | Corona-Virus | 1 |
| 20 | COVID-19 | 1 |
| 21 | Datenkompetenz | 1 |
| 22 | Diamond Open Access | 1 |
| 23 | Digitalisierungsstrategie | 1 |
| 24 | eBooks | 1 |
| 25 | Elektronisches Publizieren | 1 |
| 26 | Erfahrungsbericht | 1 |
| 27 | Fachzeitschrift | 1 |
| 28 | FID | 1 |
| 29 | Fluide Bibliothek, Aufstellungssystematik, Dynamisches Bestandsmanagement | 1 |
| 30 | Forschungsdaten | 1 |
| 31 | Forschungsdatenrepositorien | 1 |
| 32 | Fortbildung | 1 |
| 33 | Geistes- und Sozialwissenschaften | 1 |
| 34 | Geschäftsmodell | 1 |
| 35 | grüner Weg | 1 |
| 36 | Hochschulbibliotheken | 1 |
| 37 | Hochschulbildung | 1 |
| 38 | Indikatoren | 1 |
| 39 | Informationskompetenz | 1 |
| 40 | Ingenieurwissenschaft | 1 |
| 41 | Interne Wissenschaftskommunikation | 1 |
| 42 | Kollaboration | 1 |
| 43 | Konferenz | 1 |
| 44 | Konferenzorganisation | 1 |
| 45 | Konferenzplanung | 1 |
| 46 | Landesbibliothek | 1 |
| 47 | Landeskunde | 1 |
| 48 | Linked Open Data | 1 |
| 49 | Living Handbook | 1 |
| 50 | Lockdown | 1 |
| 51 | Methoden | 1 |
| 52 | Metriken | 1 |
| 53 | Moderation | 1 |
| 54 | Netzwerkanalyse | 1 |
| 55 | Nutzerstudien | 1 |
| 56 | Öffentliche Bibliotheken | 1 |
| 57 | Open-Access-Beratung | 1 |
| 58 | Open-Access-Finanzierung | 1 |
| 59 | Open-Access-Publizieren | 1 |
| 60 | Open-Access-Zeitschriften | 1 |
| 61 | Open Access Monitoring | 1 |
| 62 | Open Access Publizieren | 1 |
| 63 | Open Access Transformation | 1 |
| 64 | Open Educational Resources (OER) | 1 |
| 65 | Open Journal Systems | 1 |
| 66 | Open Peer-Review | 1 |
| 67 | Open Science | 1 |
| 68 | Peer-Review | 1 |
| 69 | Präsentation | 1 |
| 70 | Predatory Journals | 1 |
| 71 | Preprint | 1 |
| 72 | Promovierende | 1 |
| 73 | Publikationsfonds | 1 |
| 74 | Publikationskompetenz | 1 |
| 75 | Qualitätssicherung | 1 |
| 76 | quality assurance | 1 |
| 77 | Recommender | 1 |
| 78 | Regionalbibliothek | 1 |
| 79 | Regionalbibliotheken | 1 |
| 80 | Repositorium | 1 |
| 81 | research data | 1 |
| 82 | research data repositories | 1 |
| 83 | Responsible metrics | 1 |
| 84 | Sachsen | 1 |
| 85 | Sachsen-Anhalt | 1 |
| 86 | Scholar-Led Journals | 1 |
| 87 | Scholarly Communication | 1 |
| 88 | Services | 1 |
| 89 | Social Media | 1 |
| 90 | Szientometrie | 1 |
| 91 | textuelle Materialität | 1 |
| 92 | Thüringer Universitäts- und Landesbibliothek Jena | 1 |
| 93 | Transformation | 1 |
| 94 | 1 | |
| 95 | Umfrage | 1 |
| 96 | Visualisierungen | 1 |
| 97 | VIVO, Forschungsinformationen, Forschungsinformationssystem | 1 |
| 98 | VIVO, Forschungsinformationen, Forschungsinformationssystem, Ausbildung, Ontologie, Linked Data | 1 |
| 99 | Weiterbildung | 1 |
| 100 | Wiki | 1 |
| 101 | Wissenschaftliches Publizieren | 1 |
| 102 | Workflowentwicklung | 1 |
| 103 | Zusammenarbeit | 1 |
| 104 | Zweitveröffentlichungsservice | 1 |
Wir müssen uns also, um mehr über die Inhalte zu erfahren (ohne gleich alle Beiträge zu lesen), dem Textmining – also praktisch der statistischen Auswertung der Wortverteilung – zuwenden.
3. Textmining – einfach
Für Textmining wird immer Text – in unserem Fall alle in der Zeitschrift erschienen Beiträge – als Datenbasis für statistische Auswertungen verwendet. Dafür ist es notwendig, sie in ein Format zu bringen, dass nur aus Text besteht. Dies funktioniert mittels des im Abschnitt (2) beschriebenen Weges aber schnell, fast schon erschreckende schnell: Die Informationspraxis war eine Zeitschrift, an der über acht Jahre lang von vielen Menschen gearbeitet wurde – aber in etwas weniger als 70 Sekunden sind alle diese Metadaten und Artikel heruntergeladen, umgewandelt und für die weitergehende Analyse aufbereitet.
Was damit möglich ist, ist aber erst einmal eine einfache Auswertung der Worte und Wortverbindungen, die in den Artikeln vorkommen. Die Idee dahinter ist, dass aus diesem Vorkommen unterschwellige Themen gelesen werden können – also beispielsweise inhaltliche Gemeinsamkeiten zwischen den Beiträgen, die einzelnen Autor*innen gar nicht auffallen. (Es hilft, dass alle Artikel hier in der gleichen Sprache – dem Deutschen, wenn auch mit leichten Varianten – publiziert wurden. Das macht es möglich, einfach die gleiche Statistik für alle Dokumente zu erstellen und diese zusammenzufassen.)
Zuerst können wir uns eine Liste anschauen, welche die Dokumente (also unsere Beiträge) und ihre statistischen Eigenschaften zusammen darstellt. In der ersten Spalte findet sich die ID der Artikel, in der zweiten die Anzahl der Zeichen, in der dritten die Zahl der Sätze (gezählt nach den Satzendzeichen), in der vierten die der Tokens (zusammenhängende Buchstabenfolgen, also oft Worte, aber auch Emoticons oder so.) und in den folgenden Spalten die jeweilige Zahl weiterer Zeichenketten.
| index | document | chars | sents | tokens | types | puncts | numbers | symbols | urls | tags | emojis |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [1] - Karsten Schuldt (202 | 42,070 | 298 | 6,932 | 1,420 | 1,019 | 233 | 25 | 27 | 0 | 0 |
| 2 | [2] - Stefan Schmeja, Ulri | 15,907 | 113 | 2,488 | 896 | 445 | 57 | 5 | 26 | 1 | 0 |
| 3 | [3] - Frank Waldschmidt-Di | 16,106 | 124 | 2,590 | 1,009 | 354 | 53 | 3 | 18 | 39 | 0 |
| 4 | [4] - Anette Cordts, Elias | 23,398 | 157 | 3,412 | 1,231 | 536 | 41 | 3 | 21 | 0 | 0 |
| 5 | [5] - Maxi Kindling, Dorot | 18,456 | 123 | 2,992 | 829 | 410 | 37 | 0 | 9 | 0 | 0 |
| 6 | [6] - Nicolas Bach (2022). | 38,517 | 233 | 5,847 | 1,779 | 670 | 60 | 19 | 44 | 0 | 0 |
| 7 | [7] - Tina Grahl (2021). S | 37,725 | 298 | 5,685 | 1,533 | 983 | 163 | 0 | 15 | 0 | 0 |
| 8 | [8] - Sarah Dellmann, Arvi | 43,978 | 323 | 6,827 | 1,969 | 1,266 | 151 | 1 | 27 | 1 | 0 |
| 9 | [9] - Berfu Erdogan, Chris | 17,405 | 101 | 2,484 | 930 | 289 | 29 | 0 | 11 | 0 | 0 |
| 10 | [10] - Grischa Fraumann, Ch | 17,265 | 118 | 2,702 | 1,007 | 616 | 62 | 5 | 19 | 0 | 0 |
| 11 | [11] - Christian Hauschke, | 20,680 | 175 | 3,028 | 1,143 | 555 | 82 | 7 | 41 | 0 | 0 |
| 12 | [12] - Jana Madlen Schütte | 13,186 | 76 | 1,794 | 669 | 281 | 34 | 0 | 17 | 0 | 0 |
| 13 | [13] - Thomas Mutschler (20 | 36,967 | 240 | 5,075 | 1,543 | 715 | 97 | 0 | 29 | 0 | 0 |
| 14 | [14] - Roberto Cozatl, Dani | 38,129 | 220 | 5,278 | 1,646 | 670 | 115 | 20 | 70 | 0 | 0 |
| 15 | [15] - Wolf Christoph Seife | 51,474 | 308 | 7,707 | 1,751 | 1,408 | 226 | 2 | 40 | 0 | 0 |
| 16 | [16] - Martin Munke, Daniel | 68,518 | 567 | 10,251 | 2,871 | 2,165 | 467 | 9 | 131 | 0 | 0 |
| 17 | [17] - Colette Knight, Tama | 30,556 | 204 | 4,535 | 1,403 | 654 | 65 | 0 | 32 | 0 | 0 |
| 18 | [18] - Markus Putnings (202 | 8,152 | 62 | 1,230 | 591 | 236 | 20 | 3 | 36 | 0 | 0 |
| 19 | [19] - Irene Barbers, Sonja | 54,159 | 381 | 7,756 | 2,210 | 1,086 | 552 | 23 | 104 | 0 | 0 |
| 20 | [20] - Stefanie Hanneken, A | 49,859 | 318 | 7,060 | 2,050 | 1,024 | 128 | 26 | 44 | 0 | 0 |
| 21 | [21] - Claudia Frick (2020) | 42,176 | 295 | 6,705 | 1,866 | 1,413 | 195 | 11 | 91 | 0 | 0 |
| 22 | [22] - Christina Riesenwebe | 8,084 | 65 | 1,297 | 483 | 181 | 12 | 1 | 5 | 0 | 0 |
| 23 | [23] - Franziska Altemeier, | 19,557 | 180 | 2,944 | 977 | 588 | 82 | 2 | 20 | 0 | 0 |
| 24 | [24] - Jana Hentschke, Sylv | 21,702 | 139 | 3,172 | 1,172 | 378 | 53 | 0 | 5 | 0 | 0 |
| 25 | [25] - Jens Bemme (2020). # | 29,603 | 180 | 4,314 | 1,442 | 831 | 79 | 2 | 78 | 10 | 0 |
| 26 | [26] - Stefanie Spiegelberg | 51,568 | 351 | 7,739 | 2,000 | 1,255 | 166 | 0 | 70 | 0 | 0 |
| 27 | [27] - Sophie Schneider (20 | 52,299 | 379 | 8,184 | 2,139 | 1,696 | 231 | 25 | 101 | 22 | 0 |
| 28 | [28] - Heinz-Jürgen Bove, J | 40,869 | 194 | 5,820 | 2,072 | 631 | 45 | 13 | 20 | 4 | 0 |
| 29 | [29] - Heinz-Jürgen Bove, J | 40,651 | 192 | 5,754 | 2,051 | 624 | 41 | 14 | 21 | 4 | 0 |
| 30 | [30] - Barbara Knorn, Erich | 9,314 | 68 | 1,312 | 554 | 191 | 25 | 0 | 9 | 0 | 0 |
| 31 | [31] - Karsten Schuldt (202 | 72,133 | 703 | 12,148 | 2,720 | 2,603 | 559 | 16 | 38 | 0 | 0 |
| 32 | [32] - Christian Mathieu (2 | 16,174 | 106 | 2,319 | 919 | 457 | 41 | 11 | 18 | 0 | 0 |
| 33 | [33] - Christian Hauschke ( | 43,448 | 455 | 7,200 | 2,239 | 1,666 | 304 | 5 | 74 | 0 | 0 |
| 34 | [34] - Alessandro Blasetti, | 95,594 | 633 | 13,598 | 3,098 | 2,381 | 331 | 22 | 128 | 1 | 0 |
| 35 | [35] - Fabian Steeg, Adrian | 25,852 | 147 | 3,844 | 1,207 | 628 | 34 | 15 | 59 | 0 | 0 |
| 36 | [36] - Nicole Eichenberger | 32,387 | 278 | 4,723 | 1,561 | 886 | 101 | 1 | 46 | 0 | 0 |
| 37 | [37] - Sabine Thänert, Mari | 21,651 | 143 | 3,057 | 1,074 | 450 | 84 | 1 | 85 | 0 | 0 |
| 38 | [38] - Christian Erlinger ( | 16,314 | 124 | 2,302 | 931 | 338 | 86 | 0 | 30 | 0 | 0 |
| 39 | [39] - Gabriele Fahrenkrog, | 27,207 | 154 | 3,763 | 1,174 | 495 | 81 | 3 | 39 | 0 | 0 |
| 40 | [40] - Christian Hauschke, | 20,719 | 142 | 2,929 | 1,066 | 465 | 42 | 1 | 30 | 0 | 0 |
| 41 | [41] - Joanna Einbock, Chri | 39,144 | 271 | 5,458 | 1,681 | 839 | 147 | 2 | 43 | 0 | 0 |
| 42 | [42] - Adrian Pohl, Fabian | 35,353 | 243 | 5,387 | 1,553 | 929 | 71 | 2 | 63 | 2 | 0 |
| 43 | [43] - Oliver Sievi, Andrea | 21,239 | 136 | 3,045 | 1,104 | 474 | 57 | 21 | 49 | 0 | 0 |
| 44 | [44] - Christian Hauschke, | 16,465 | 151 | 2,468 | 940 | 467 | 61 | 15 | 38 | 0 | 0 |
| 45 | [45] - Karsten Schuldt, Azr | 45,310 | 279 | 6,895 | 1,829 | 1,048 | 103 | 4 | 26 | 0 | 0 |
| 46 | [46] - Karsten Schuldt, Rud | 71,941 | 536 | 11,904 | 2,545 | 2,182 | 292 | 24 | 95 | 0 | 0 |
| 47 | [47] - Jakob Voß, Laura Bod | 19,123 | 139 | 2,837 | 1,011 | 407 | 85 | 9 | 34 | 0 | 0 |
| 48 | [48] - Nicole Eichenberger, | 23,449 | 140 | 3,852 | 1,047 | 459 | 49 | 0 | 28 | 0 | 0 |
| 49 | [49] - Jana Mersmann, Chris | 17,006 | 130 | 2,481 | 962 | 413 | 85 | 2 | 25 | 0 | 0 |
| 50 | [50] - Christian Wilke, Reg | 20,722 | 122 | 2,919 | 1,172 | 428 | 55 | 0 | 31 | 0 | 0 |
| 51 | [51] - Gabriele Fahrenkrog, | 10,127 | 65 | 1,367 | 634 | 175 | 12 | 0 | 7 | 0 | 0 |
| 52 | [52] - Eckhart Arnold, Stef | 65,296 | 376 | 10,122 | 2,487 | 1,616 | 107 | 9 | 121 | 0 | 0 |
| 53 | [53] - Salome Zehnder (2017 | 23,176 | 210 | 3,770 | 1,218 | 693 | 101 | 1 | 21 | 0 | 0 |
| 54 | [54] - Christian Koller (20 | 41,107 | 261 | 5,913 | 1,956 | 959 | 189 | 43 | 74 | 0 | 0 |
| 55 | [55] - Marco Humbel (2017). | 39,265 | 390 | 6,087 | 1,595 | 1,137 | 223 | 2 | 83 | 0 | 0 |
| 56 | [56] - Tabea Lurk, Jürgen E | 36,607 | 310 | 5,634 | 1,950 | 1,318 | 130 | 13 | 96 | 0 | 0 |
| 57 | [57] - Christian Kaier (201 | 28,694 | 204 | 4,087 | 1,332 | 776 | 100 | 4 | 28 | 0 | 0 |
| 58 | [58] - Márton Villányi (201 | 22,219 | 160 | 3,200 | 1,132 | 393 | 35 | 0 | 22 | 0 | 0 |
| 59 | [59] - Daniel Hürlimann, Al | 15,622 | 108 | 2,388 | 1,009 | 338 | 61 | 0 | 14 | 0 | 0 |
| 60 | [60] - Fabian Gail, Mark Ve | 66,758 | 427 | 9,837 | 2,663 | 1,331 | 115 | 2 | 51 | 0 | 0 |
| 61 | [61] - Christian Hauschke ( | 15,065 | 121 | 2,489 | 920 | 581 | 93 | 28 | 50 | 33 | 0 |
| 62 | [62] - Beat Mattmann (2016) | 24,222 | 169 | 3,619 | 1,328 | 637 | 86 | 1 | 32 | 0 | 0 |
| 63 | [63] - Karsten Schuldt (201 | 46,834 | 383 | 7,354 | 1,738 | 1,222 | 172 | 11 | 54 | 0 | 0 |
| 64 | [64] - Daniel Beucke, Arvid | 22,286 | 134 | 3,288 | 1,246 | 476 | 63 | 8 | 24 | 1 | 0 |
| 65 | [65] - Armin Talke (2016). | 17,614 | 105 | 2,580 | 969 | 356 | 40 | 2 | 17 | 0 | 0 |
| 66 | [66] - Dörte Böhner, Gabrie | 5,899 | 63 | 952 | 383 | 243 | 50 | 0 | 14 | 0 | 0 |
| 67 | [67] - Tim Schumann (2016). | 47,566 | 354 | 7,147 | 2,000 | 1,098 | 222 | 9 | 55 | 0 | 0 |
| 68 | [68] - Gabriele Fahrenkrog | 43,916 | 290 | 6,645 | 1,831 | 1,154 | 170 | 4 | 59 | 1 | 0 |
| 69 | [69] - Simon Schultze (2016 | 28,601 | 356 | 4,927 | 1,381 | 1,200 | 232 | 2 | 38 | 0 | 0 |
| 70 | [70] - Gary Seitz, Barbara | 14,816 | 116 | 2,272 | 829 | 376 | 84 | 1 | 21 | 0 | 0 |
| 71 | [71] - Andrea Hofmann, Chri | 12,391 | 115 | 1,912 | 788 | 340 | 61 | 3 | 16 | 0 | 0 |
| 72 | [72] - Martin Wollschläger- | 49,660 | 335 | 7,278 | 1,929 | 1,374 | 221 | 0 | 93 | 0 | 0 |
| 73 | [73] - Corinna Haas, Rudolf | 91,557 | 554 | 15,119 | 3,201 | 2,963 | 365 | 3 | 51 | 0 | 0 |
| 74 | [74] - Rudolf Mumenthaler, | 22,974 | 138 | 3,146 | 1,130 | 418 | 79 | 1 | 27 | 0 | 0 |
| 75 | [75] - Christian Hauschke, | 20,485 | 160 | 3,365 | 1,134 | 779 | 86 | 47 | 69 | 0 | 0 |
| 76 | [76] - Jens Ambacher, Gabri | 36,286 | 235 | 5,724 | 1,512 | 855 | 48 | 0 | 34 | 0 | 0 |
| 77 | [77] - Dörte Böhner, Gabrie | 5,967 | 39 | 907 | 452 | 105 | 2 | 0 | 0 | 0 | 0 |
| 78 | [78] - Rudolf Mumenthaler, | 29,193 | 188 | 4,190 | 1,249 | 583 | 47 | 0 | 25 | 0 | 0 |
| 79 | [79] - Susanne Baudisch, El | 148,307 | 921 | 22,126 | 4,585 | 3,772 | 687 | 11 | 240 | 0 | 0 |
| 80 | [80] - Alexandra Svantje Li | 33,637 | 298 | 5,224 | 1,407 | 861 | 201 | 0 | 43 | 0 | 0 |
| 81 | [81] - Bernhard Mittermaier | 77,525 | 455 | 11,945 | 2,817 | 1,899 | 481 | 42 | 158 | 0 | 0 |
| 82 | [82] - Ute Engelkenmeier (2 | 17,345 | 135 | 2,705 | 1,125 | 431 | 58 | 0 | 19 | 0 | 0 |
| 83 | [83] - Markus Trapp (2015). | 16,420 | 103 | 2,609 | 941 | 347 | 48 | 0 | 17 | 0 | 0 |
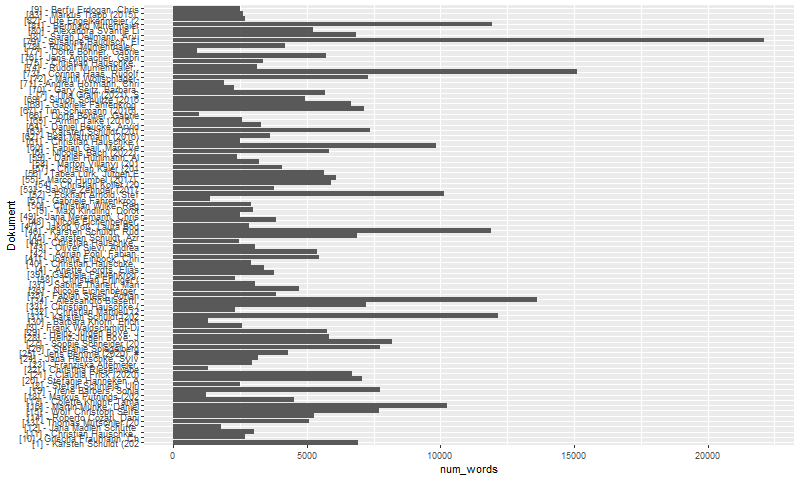
Wir sehen hier beispielsweise, dass es sehr unterschiedliche lange Beiträge gab; etwas, dass in Zeitschriften mit klaren Vorgaben für Artikel – im Bibliothekswesen vor allem die auch gedruckt erscheinenden praxisorientierten Zeitschriften – nicht vorkommen würde. Gleichzeitig zeigt sich, dass die Autor*innen auf #Tags und Emoticons verzichteten sowie andere Zeichen, als Text, nur sparsam einsetzten.
Die unterschiedliche Länge der Texte lässt sich auch (eingermassen) aus der folgenden Darstellung dieser Daten ablesen.
In einer weiteren Tabelle lässt sich ablesen, welche Worte am meisten verwendet wurden. Bei solchen Analysen finden sich – obgleich «Stoppwörter» standardmässig, also auch hier, aus diesen Statistiken entfernt werden – immer viele «Allgemeinworte». Relevant ist, die betreffenden, einen Korpus kennzeichnenden Worte herauszufiltern. Allgemeinworte in dieser Liste sind beispielsweise «dass», «wurde», «wurden». (In einem weiteren Schritt kann man diese Worte trunkieren – also auf ihren Wortstamm zurückführen, hier «wurde» und «wurden» auf «wurd». Aber das bedarf dann, die Ergebnisse noch mehr zu überprüfen, um herauszufinden, was richtig trunkiert wurden und was nicht. Etwas, das in diesem Experiment nicht getan wurde.)
Für uns interessant sind Wort wie «bibliotheken» (1244-mal), «open» (1172-mal), «bibliothek» (756-mal), «access» (614-mal), «daten» (404-mal), «library» (360-mal), «data» (344-mal), «information» (331-mal), «online» (317-mal), «informationen» (264-mal), «menschen» (263-mal) oder «zugriff» (261-mal). Die Informationspraxis stammte aus dem Bibliothekswesen und dies war offenbar in den Artikeln, die bei ihr erschienen, auch prägend. Es wurde über Bibliotheken oder über Themen, die das Bibliothekswesen interessieren (Open Access, Information, Online, Menschen), geschrieben. (Erstaunlich ist, dass «archiv» nur 50-mal, «archive» 29-mal genannt wurde, allerdings auch noch eine Anzahl an Zusammensetzungen mit «Archiv».)
Wir können uns aus dieser Liste wieder Unterlisten ausgeben lassen und zum Beispiel schauen, ob, zum Beispiel, «Bibliothek» und «Information» rein als Begriff genutzt wurden oder in Zusammensetzungen.
Das scheint vielleicht etwas nach Spielerei (wir lernen halt, dass es zwar Zusammensetzungen gab, daneben die Begriffe allerdings grösstenteils «rein» verwendet wurden), aber sichtbar ist im zweiten Plot auch, dass der Zeitschriftenname selber recht oft verwendet wurde. (168-mal, wie die unterliegende Datentabelle zeigt.)
Für eine weitere Tabelle können wir uns den «collocations» (Kollokationen – was keine hilfreiche Übersetzung ist; es sind jeweils zwei zusammen stehende Worte), die gewisse allgemein verwendete Begrifflichkeiten anzeigen. Hier zeigt sich unter anderem, dass «Open Access» tatsächlich recht offen in den Beiträgen der Informationspraxis vorkam (566-mal).
4. Text Mining – (etwas) komplexer
Das quanteda Paket ermöglicht viele weitere Analysen. Das, was wir bislang gezeigt haben, ist eher nur ein Anfang. (Allerdings: Damit es sinnvoll ist, ist für viele Funktionen – ganz abgesehen davon, dass sie eine weitere Lernkurve bedeuten würden, für die bei diesem «Experiment» keine Zeit zur Verfügung stand – ein grösserer Datensatz notwendig.) Wir können aber zumindest zwei dieser Analysen durchführen.
Zuerst Keyword in Context (KWIC)-Tabellen. (Das erinnert Bibliothekar*innen vielleicht an ihren Katalogisierungsunterricht, wenn sie den noch hatten. Aber es ist etwas anderes.) In diesen Tabellen werden die jeweils gewählten Worte im Zusammenhang dargestellt. Die Länge des Zusammenhangs lässt sich selbstverständlich anpassen, aber hier haben wir die Standardeinstellung verwendet, die da heisst: je fünf Token vor und nach dem gesuchten Wort. In der erste Tabelle hier wird dies für «bibliothek» gezeigt. In dieser findet sich für jedes Vorkommen jeweils der Kontext, welcher das Wort umrahmt, zudem der Verweis auf den eigentlichen Text und eine Zeichenangabe, wo genau sich dieser Kontext vorkommt. Die Idee hinter diesen Tabelle ist es, jetzt einen Überblick darüber zu haben, was regelmässig im Zusammenhang mit dem gewählten Wort geschrieben wird. (In vielen Einleitungen zum Textmining wird dies anhand von politischen Reden vorgeführt, da ist dann sichtbar, was im Zusammenhang mit «umstrittenen» Begriffen gesagt wurde.)
| docname | from | to | pre | keyword | post | pattern |
|---|---|---|---|---|---|---|
| [1] - Karsten Schuldt (202 | 49 | 49 | dies auch für die Öffentlichen | Bibliotheken | in der Schweiz , Österreich | bibliothek* |
| [1] - Karsten Schuldt (202 | 62 | 62 | gilt , werden die betreffenden | Bibliotheksstatistiken | , soweit möglich , mit | bibliothek* |
| [1] - Karsten Schuldt (202 | 86 | 86 | COVID-19 Pandemie für die Öffentlichen | Bibliotheken | dieser drei Länder auch herausfordernd | bibliothek* |
| [1] - Karsten Schuldt (202 | 123 | 123 | zu Zuwächsen . COVID-19 , | Bibliotheksnutzung | , Bibliotheksstatistik , Öffentliche Bibliotheken | bibliothek* |
| [1] - Karsten Schuldt (202 | 125 | 125 | . COVID-19 , Bibliotheksnutzung , | Bibliotheksstatistik | , Öffentliche Bibliotheken An article | bibliothek* |
| [1] - Karsten Schuldt (202 | 128 | 128 | Bibliotheksnutzung , Bibliotheksstatistik , Öffentliche | Bibliotheken | An article , which explores | bibliothek* |
| [1] - Karsten Schuldt (202 | 301 | 301 | in welche die britischen Öffentlichen | Bibliotheken | durch die COVID-19 Pandemie geraten | bibliothek* |
| [1] - Karsten Schuldt (202 | 381 | 381 | eine allgemeine Krise von Öffentlichen | Bibliotheken | aufzeigen – oder vielleicht nur | bibliothek* |
| [1] - Karsten Schuldt (202 | 411 | 411 | deutschen , österreichischen und schweizerischen | Bibliotheksstatistik | durch . 1 ( Für | bibliothek* |
| [1] - Karsten Schuldt (202 | 747 | 747 | führen erstaunlicherweise keine Zahlen für | Bibliotheksbesuche | an . Diese sind ansonsten | bibliothek* |
| [1] - Karsten Schuldt (202 | 764 | 764 | es um die Arbeit von | Bibliotheken | geht und zudem einer , | bibliothek* |
| [1] - Karsten Schuldt (202 | 815 | 815 | , sich auch in den | Bibliotheken | im DACH-Raum zeigte . Für | bibliothek* |
| [1] - Karsten Schuldt (202 | 909 | 909 | Für eine vollständige Übersicht zu | Bibliotheken | im DACH-Raum wären Daten aus | bibliothek* |
| [1] - Karsten Schuldt (202 | 940 | 940 | auch bei den drei vorliegenden | Bibliotheksstatistiken | einige Einschränkungen zu beachten . | bibliothek* |
| [1] - Karsten Schuldt (202 | 959 | 959 | dann zur Verfügung gestellte deutsche | Bibliotheksstatistik | ist die umfangreichste und am | bibliothek* |
| [1] - Karsten Schuldt (202 | 975 | 975 | ) Sie umfasst die Öffentlichen | Bibliotheken | Deutschlands sowie die Wissenschaftlichen Bibliotheken | bibliothek* |
| [1] - Karsten Schuldt (202 | 980 | 980 | Bibliotheken Deutschlands sowie die Wissenschaftlichen | Bibliotheken | aus Deutschland und Österreich . | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,001 | 1,001 | nach Kriterien wie den gewünschten | Bibliothekstypen | , Jahren oder einzelnen Variablen | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,029 | 1,029 | dass eine ganze Anzahl von | Bibliotheken | für verschiedene Variablen keine Werte | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,117 | 1,117 | verstehen . 3 Die schweizerische | Bibliotheksstatik | wird vom Bundesamt für Statistik | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,144 | 1,144 | Diese Daten stehen für verschiedene | Bibliothekstypen | ( und bis 2019 auch | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,152 | 1,152 | bis 2019 auch für unterschiedliche | Bibliotheksgrössen | ) und noch einmal in | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,212 | 1,212 | . Zuvor wurden nicht alle | Bibliotheken | erfasst . Es fehlten solche | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,252 | 1,252 | diesen eine ganze Anzahl von | Bibliotheken | , die nicht für alle | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,275 | 1,275 | Eine wichtigere Einschränkung der schweizerischen | Bibliotheksstatik | im Bezug auf die hier | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,356 | 1,356 | . Die Daten der Österreichischen | Bibliotheksstatistik | werden , wie gesagt , | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,390 | 1,390 | auch bei den beiden anderen | Bibliotheksstatistiken | sind diese mit Vorsicht zu | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,438 | 1,438 | Auch meldeten nur sehr wenige | Bibliotheken | Daten zur “ Ausleihe ” | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,461 | 1,461 | Medien in den meisten dieser | Bibliotheken | durch zentrale Lizenzen für die | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,498 | 1,498 | 5 Für diese Statistiken erfassen | Bibliotheken | selbstständig ihre jeweiligen Daten und | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,530 | 1,530 | wohl davon ausgehen , dass | Bibliotheken | hier versuchen , ehrliche Antworten | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,547 | 1,547 | kann dies nicht . Die | Bibliotheksstatistiken | und damit auch Auswertungen wie | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,581 | 1,581 | möglich war , versucht die | Bibliotheken | nicht mitzubetrachten , die gleichzeitig | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,588 | 1,588 | mitzubetrachten , die gleichzeitig mehreren | Bibliothekstypen | angehören , also zum Beispiel | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,616 | 1,616 | schwierig zu bestimmen , welche | Bibliotheksnutzungen | sich auf welchen Bereich der | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,623 | 1,623 | auf welchen Bereich der jeweiligen | Bibliotheken | bezogen . Weiterhin ist zu | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,764 | 1,764 | österreichische und 7045 deutsche Öffentliche | Bibliotheken | . Anschliessend wurden die Fragen | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,919 | 1,919 | verwendet , also Daten von | Bibliotheken | , welche solche jeweils für | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,931 | 1,931 | drei Jahre angegeben hatten . | Bibliotheken | , welche beispielsweise erstmals für | bibliothek* |
| [1] - Karsten Schuldt (202 | 1,955 | 1,955 | beachtet , genauso wie solche | Bibliotheken | , die aus unterschiedlichen Gründen | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,010 | 2,010 | Angaben für die Besuche von | Bibliotheken | vorlagen und zu vermuten ist | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,098 | 2,098 | Ort – beispielsweise Neueröffnungen von | Bibliothek | – oder eventuell auch Datenfehler | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,496 | 2,496 | . Bei der Umstellung der | Bibliotheksstatistik | für die Daten ab 2020 | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,648 | 2,648 | Grossbritannien gab es für die | Bibliotheken | in den drei Ländern relativ | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,675 | 2,675 | Zeit , die von den | Bibliotheken | recht gut gemeistert wurden . | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,710 | 2,710 | sich am meisten auf Öffentliche | Bibliotheken | in Deutschland auswirkten , dann | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,725 | 2,725 | in Österreich und das die | Bibliotheken | in der Schweiz während der | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,790 | 2,790 | hier jeweils die Anzahl der | Bibliotheken | , bei denen sich eine | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,828 | 2,828 | . Während in Grossbritannien alle | Bibliotheken | eine Reduktion dieser Ausleihen berichteten | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,860 | 2,860 | sich sehr wohl immer auch | Bibliotheken | , die im Jahr 2020 | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,886 | 2,886 | zum Beispiel knapp 4400 Öffentliche | Bibliotheken | in Deutschland ( von rund | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,923 | 2,923 | ist der grösste Teil der | Bibliotheken | . Aber gleichzeitig ist dies | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,938 | 2,938 | Grossbritannien , wo die meisten | Bibliotheken | zwischen 61 % und 96 | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,969 | 2,969 | etwas mehr als 800 deutsche | Bibliotheken | 2020 bis zu 50 % | bibliothek* |
| [1] - Karsten Schuldt (202 | 2,988 | 2,988 | % -100 % und einige | Bibliotheken | sogar noch grössere Steigerungen meldeten | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,045 | 3,045 | In Österreich berichteten die meisten | Bibliotheken | von einem im Vergleich zu | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,064 | 3,064 | In der Schweiz konnten mehr | Bibliotheken | über eine Steigerung der Ausleihe | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,092 | 3,092 | Grenzen . Der Grossteil der | Bibliotheken | findet sich in der Bandbreite | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,120 | 3,120 | die Hälfte der allgemein öffentlichen | Bibliotheken | in der Schweiz 2020 die | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,189 | 3,189 | einmal einzugrenzen : Viele Öffentliche | Bibliotheken | lieferten keine kontinuierlichen Daten , | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,215 | 3,215 | Nicht klar ist , ob | Bibliotheken | stattdessen über regionale Konsortien für | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,235 | 3,235 | die betreffenden Werte für ihre | Bibliothek | dann aber ( entgegen der | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,313 | 3,313 | : Der grösste Teil der | Bibliotheken | berichtete von einer Steigerung von | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,338 | 3,338 | auch eine bemerkbare Minderheit von | Bibliotheken | , deren Daten eine Reduktion | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,385 | 3,385 | 10 Aber die meisten dieser | Bibliotheken | mit einem Rückgang dieser “ | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,412 | 3,412 | Daten zeigte sich in einigen | Bibliotheken | eine Reduktion solcher “ Ausleihen | bibliothek* |
| [1] - Karsten Schuldt (202 | 3,423 | 3,423 | ” . Die meisten britischem | Bibliotheken | berichteten aber über eine Steigerung | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,006 | 4,006 | . Zudem gab es auch | Bibliotheken | , welche mehr physische Bücher | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,055 | 4,055 | dass es auch in Deutschland | Bibliotheken | gab , die 2020 insgesamt | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,068 | 4,068 | . Aber doch weit mehr | Bibliotheken | , die eine kleine Steigerung | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,130 | 4,130 | ist , ob es für | Bibliotheken | überhaupt effizient ist , Lizenzen | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,204 | 4,204 | Lizenzkosten 2018 und 2020 der | Bibliotheken | , die dazu Angaben machten | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,227 | 4,227 | lässt sich sehen , dass | Bibliotheken | 2020 zumeist mehr Geld für | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,248 | 4,248 | beiden Ländern für die meisten | Bibliotheken | bis zu 50 % beträgt | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,274 | 4,274 | % -50 % ( 27 | Bibliotheken | ) , 50 % -100 | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,283 | 4,283 | % -100 % ( 28 | Bibliotheken | ) und 100 % -150 | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,292 | 4,292 | % -150 % ( 29 | Bibliotheken | ) streckte . Auffällig ist | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,304 | 4,304 | , dass die Zahl der | Bibliotheken | , welche einen Rückgang meldeten | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,336 | 4,336 | wie schon dargestellt , die | Bibliotheken | in der Schweiz und Deutschland | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,381 | 4,381 | zu verstehen , ob die | Bibliotheken | Geld effektiv für Lizenzen ausgeben | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,399 | 4,399 | der Zeit sinken , wenn | Bibliotheken | mit zunehmender Erfahrung eher die | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,615 | 4,615 | eine sehr kleine Anzahl von | Bibliotheken | . ) Die Zahlen sind | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,635 | 4,635 | Medienformen weiter höher . Deutsche | Bibliotheken | scheinen also grundsätzlich mit der | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,705 | 4,705 | nicht die Entwicklung der konkreten | Bibliotheksbesuche | . Gründe dafür geben sie | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,812 | 4,812 | wieder , dass die schweizerischen | Bibliotheken | die etwas besseren Zahlen erreichten | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,920 | 4,920 | vor allem die Besuche in | Bibliotheken | waren – im Gegensatz zu | bibliothek* |
| [1] - Karsten Schuldt (202 | 4,963 | 4,963 | dass die Situation für Öffentliche | Bibliotheken | zumindest im ersten Jahr der | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,095 | 5,095 | Was sichtbar wurde und für | Bibliotheken | in Zukunft relevant sein sollte | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,120 | 5,120 | obgleich die Besuche in den | Bibliotheken | massiv zurückgingen . Dies steht | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,129 | 5,129 | Dies steht entgegen der im | Bibliothekswesen | verbreiteten Vorstellung , dass der | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,136 | 5,136 | Vorstellung , dass der Raum | Bibliothek | eine immer grössere Bedeutung im | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,190 | 5,190 | die vor allem Medien aus | Bibliotheken | nutzen und den Personen , | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,201 | 5,201 | die vor allem den Raum | Bibliothek | nutzen , um zwei verschiedene | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,248 | 5,248 | mit Fragen zum Raum der | Bibliothek | geschieht . Der Unterschied der | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,291 | 5,291 | einer anhaltenden Krise des britischen | Bibliothekswesens | geschrieben , die vor allem | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,332 | 5,332 | Daten mit denen aus den | Bibliotheksstatistiken | anderer Länder zu vergleichen . | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,372 | 5,372 | DACH-Raum als auch Grossbritannien unterschiedlichen | Bibliothekskultur | wie beispielsweise Frankreich , Spanien | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,433 | 5,433 | entgegen steht allerdings , dass | Bibliotheksstatistiken | offenbar in jedem Land anders | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,477 | 5,477 | sollen . Zudem sind die | Bibliotheksstatistiken | und ihre Begleitdokumente – also | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,606 | 5,606 | schweizerischen , österreichischen und deutschen | Bibliotheksstatistiken | für die Jahr 2018 bis | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,617 | 5,617 | 2020 zeigte , dass Öffentlichen | Bibliotheken | durch die COVID-19 Pandemie nicht | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,658 | 5,658 | sollte Teil des Selbstbildes von | Bibliotheken | werden – nämlich , das | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,686 | 5,686 | , um die Daten der | Bibliotheksstatik | – die , wie dargestellt | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,771 | 5,771 | Definitionen der Variablen der Schweizerischen | Bibliothekenstatistik | : Grunddaten und Basisvariablen . | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,796 | 5,796 | Definitionen der Variablen der Schweizerischen | Bibliothekenstatistik | : Kurzfragebogen und Zusatzfragen . | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,822 | 5,822 | ? Die Situation der britischen | Bibliotheken | im Nachhall der Finanzkrise . | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,831 | 5,831 | Finanzkrise . 027.7 Zeitschrift für | Bibliothekskultur | 6 , 1 , 15-24 | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,853 | 5,853 | Über die unterschätzten Analogien von | Bibliothek | und öffentlichem Raum . Bibliothek | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,858 | 5,858 | Bibliothek und öffentlichem Raum . | Bibliothek | Forschung und Praxis 45 , | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,918 | 5,918 | Wohnzimmer : Ein Projekt zu | Bibliotheken | und Begegnungen im öffentlichen Raum | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,928 | 5,928 | Raum . BuB . Forum | Bibliothek | und Information 73 , 1 | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,961 | 5,961 | Martin 2021 . Statistik öffentlicher | Bibliotheken | : Österreichs Bibliotheken in der | bibliothek* |
| [1] - Karsten Schuldt (202 | 5,964 | 5,964 | Statistik öffentlicher Bibliotheken : Österreichs | Bibliotheken | in der Corona Pandemie . | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,008 | 6,008 | den britischen Public Libraries vergleichbare | Bibliothekstyp | wird in den Ländern des | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,032 | 6,032 | : In Deutschland als Öffentliche | Bibliothek | , in der Schweiz und | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,042 | 6,042 | und Liechtenstein als allgemein öffentliche | Bibliothek | und in Österreich teilweise als | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,053 | 6,053 | Bücherei und teilweise als öffentliche | Bibliothek | . In diesem Text wird | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,321 | 6,321 | von E-Books aus allgemein öffentlichen | Bibliotheken | 2018-2019 gibt . ↩ Der | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,354 | 6,354 | variable Auswertung ” der Deutschen | Bibliotheksstatistik | mit den in dieser Studie | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,371 | 6,371 | Jahre 2018-2020 für alle Öffentlichen | Bibliotheken | , die betreffenden Datenblätter der | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,378 | 6,378 | die betreffenden Datenblätter der schweizerischen | Bibliotheksstatistik | sowie die schon im gewünschten | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,391 | 6,391 | Verfügung gestellten Daten der Österreichischen | Bibliotheksstatistik | . Die Daten für die | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,413 | 6,413 | je eine für allgemein öffentliche | Bibliotheken | in Gemeinden mit mehr oder | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,441 | 6,441 | einfach möglich , weil alle | Bibliotheken | eine eindeutige ID besitzen , | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,467 | 6,467 | _inquiry = 115 . ↩ | Bibliotheken | im DACH-Raum – nicht nur | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,521 | 6,521 | sein , dass dies den | Bibliotheken | im DACH-Raum gegenüber jenen in | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,673 | 6,673 | 100 Prozent . Einige dieser | Bibliotheken | könnten auch zum Zeitpunkt des | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,686 | 6,686 | Daten für 2020 in die | Bibliotheksstatistik | keine Angaben zu dieser Variable | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,767 | 6,767 | sehr unerwarteten Ergebnisse in einzelnen | Bibliotheken | , eventuell aber auch Datenfehler | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,784 | 6,784 | Qualität der Daten in den | Bibliotheksstatistiken | des DACH-Raumes hilfreich . ↩ | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,832 | 6,832 | diesen Preisveränderung von für Öffentliche | Bibliotheken | sinnvollen Lizenzen einzubeziehen . ↩ | bibliothek* |
| [1] - Karsten Schuldt (202 | 6,850 | 6,850 | . Es gibt in den | Bibliotheksstatistiken | im DACH-Raum zum Beispiel auch | bibliothek* |
| [2] - Stefan Schmeja, Ulri | 1,151 | 1,151 | den TU9-Bibliotheken gemeinsam mit Schweizer | Bibliotheken | eine Umfrage zur Erfassung des | bibliothek* |
| [3] - Frank Waldschmidt-Di | 39 | 39 | die Beine , welche den | Bibliothekartag | in vielerlei Hinsicht ergänzte . | bibliothek* |
| [3] - Frank Waldschmidt-Di | 102 | 102 | event that complemented the “ | Bibliothekartag | ” in many ways . | bibliothek* |
| [3] - Frank Waldschmidt-Di | 295 | 295 | digitale Konferenz vom Berufsverband Information | Bibliothek | ( BIB ) und der | bibliothek* |
| [3] - Frank Waldschmidt-Di | 547 | 547 | Vergleich der #vBIB mit dem | Bibliothekartag | ( Bibtag ) ist natürlich | bibliothek* |
| [3] - Frank Waldschmidt-Di | 624 | 624 | Kundinnen und Kunden in den | Bibliotheken | vor Ort übertragen lässt . | bibliothek* |
| [3] - Frank Waldschmidt-Di | 641 | 641 | #vBIB20 diesmal nicht anstelle des | Bibliothekartages | statt , sondern ergänzend dazu | bibliothek* |
| [3] - Frank Waldschmidt-Di | 666 | 666 | nach meinem Vortrag auf dem | Bibliothekartag | zum Thema „ YouTube in | bibliothek* |
| [3] - Frank Waldschmidt-Di | 672 | 672 | zum Thema „ YouTube in | Bibliotheken | “ . Den hatte ich | bibliothek* |
| [3] - Frank Waldschmidt-Di | 872 | 872 | 2021 gab es gleich zwei | bibliothekarische | Mega-Events , den Bibliothekartag hybrid | bibliothek* |
| [3] - Frank Waldschmidt-Di | 876 | 876 | zwei bibliothekarische Mega-Events , den | Bibliothekartag | hybrid und die #vBIB rein | bibliothek* |
| [3] - Frank Waldschmidt-Di | 1,156 | 1,156 | zugleich in vorbildlicher Weise dem | bibliothekarischen | Auftrag nach , Wissen zu | bibliothek* |
| [3] - Frank Waldschmidt-Di | 1,188 | 1,188 | geplante Vortrag zu YouTube in | Bibliotheken | zog kurzerhand zur #vBIB um | bibliothek* |
| [3] - Frank Waldschmidt-Di | 1,211 | 1,211 | der Aus- und Weiterbildung in | Bibliotheken | “ und bei der #vBIB21 | bibliothek* |
| [3] - Frank Waldschmidt-Di | 1,228 | 1,228 | das Graswurzel-Netzwerk “ Tutorials in | Bibliotheken | ” in den Mittelpunkt . | bibliothek* |
| [3] - Frank Waldschmidt-Di | 1,420 | 1,420 | of Practice “ Agilität in | Bibliotheken | ” . Auch bei einer | bibliothek* |
| [3] - Frank Waldschmidt-Di | 1,803 | 1,803 | und den Kontakt in der | Bibliothekscommunity | aufrechtzuerhalten . Eine hilfreiche Möglichkeit | bibliothek* |
| [3] - Frank Waldschmidt-Di | 2,038 | 2,038 | auch für die Mitschnitte beim | Bibliothekartag | , wenn sie - was | bibliothek* |
| [3] - Frank Waldschmidt-Di | 2,145 | 2,145 | des Netzwerks “ Tutorials in | Bibliotheken | ” Gebrauch gemacht . Zu | bibliothek* |
| [3] - Frank Waldschmidt-Di | 2,267 | 2,267 | Weiterbildung und eine Ergänzung zum | Bibliothekartag | , der sich vor allem | bibliothek* |
| [4] - Anette Cordts, Elias | 863 | 863 | einem technischen Partner wie einer | Bibliothek | oder einem Fachinformationszentrum oder die | bibliothek* |
| [4] - Anette Cordts, Elias | 1,533 | 1,533 | , die sich vorrangig an | Bibliotheken | richten . Diese werden eine | bibliothek* |
| [4] - Anette Cordts, Elias | 1,635 | 1,635 | Open-Access-Zeitschriften und -Buchreihen durch wissenschaftliche | Bibliotheken | stellt eine Alternative zum dominanten | bibliothek* |
| [4] - Anette Cordts, Elias | 1,752 | 1,752 | sogenannte Pledgingphase , während der | Bibliotheken | und andere Akteur * innen | bibliothek* |
| [4] - Anette Cordts, Elias | 2,132 | 2,132 | ein Großteil der Teilnehmenden im | Bibliothekskontext | und in der Publikationsinfrastruktur verortet | bibliothek* |
| [6] - Nicolas Bach (2022). | 12 | 12 | April 2022 fand an der | Bibliothek | der TH Wildau der erste | bibliothek* |
| [6] - Nicolas Bach (2022). | 18 | 18 | der TH Wildau der erste | bibliothekarische | Book Sprint Deutschlands statt , | bibliothek* |
| [6] - Nicolas Bach (2022). | 38 | 38 | nachnutzbare Handbuch „ IT in | Bibliotheken | “ hervorging . Organisiert durch | bibliothek* |
| [6] - Nicolas Bach (2022). | 47 | 47 | Organisiert durch und für die | Bibliotheks-Community | , gefördert vom Open-Access-Publikationsfonds des | bibliothek* |
| [6] - Nicolas Bach (2022). | 122 | 122 | Sprint , Living Handbook , | Bibliotheks-IT | , Open Access Publizieren , | bibliothek* |
| [6] - Nicolas Bach (2022). | 292 | 292 | betitelte Handbuch “ IT in | Bibliotheken | ” wurde 2021 von Frank | bibliothek* |
| [6] - Nicolas Bach (2022). | 314 | 314 | Initiator des dort angesiedelten Master-Studiengangs | Bibliotheksinformatik | , und Anne Christensen , | bibliothek* |
| [6] - Nicolas Bach (2022). | 352 | 352 | auch offenes Handbuch für die | Bibliotheks-IT | existierte und sich das ändern | bibliothek* |
| [6] - Nicolas Bach (2022). | 386 | 386 | , dass im Geflecht der | Bibliotheks-IT | insbesondere dem Bibliotheksmanagementsystem ( BMS | bibliothek* |
| [6] - Nicolas Bach (2022). | 389 | 389 | Geflecht der Bibliotheks-IT insbesondere dem | Bibliotheksmanagementsystem | ( BMS ) eine zentrale | bibliothek* |
| [6] - Nicolas Bach (2022). | 419 | 419 | “ Einsatz von KI-Methoden in | Bibliotheken | ” ( Seeliger u . | bibliothek* |
| [6] - Nicolas Bach (2022). | 551 | 551 | der multiplen Themen aus der | Bibliotheks-IT | für das Handbuch mehrere Sprints | bibliothek* |
| [6] - Nicolas Bach (2022). | 830 | 830 | innen aus sämtlichen Sparten von | Bibliotheken | einzubinden , um die vielfältigen | bibliothek* |
| [6] - Nicolas Bach (2022). | 838 | 838 | um die vielfältigen Betrachtungsweisen der | Bibliotheks-IT | abzubilden ( Förderung von Sharing | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,047 | 1,047 | Expert * innen aus der | Bibliotheks-IT | angefragt , die gemeinsame Terminfindung | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,206 | 1,206 | Entscheider * innen in allen | Bibliothekssparten | sowie Studierende und Lehrende . | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,266 | 1,266 | ein Standardwerk zu IT in | Bibliotheken | noch fehlt und weil ein | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,349 | 1,349 | erstaunlich guten Ergebnissen . Im | Bibliotheksbereich | feiert der Book Sprint seine | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,369 | 1,369 | Übernachtung werden erstattet . Die | Bibliothek | der TH Wildau bietet einen | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,459 | 1,459 | mit 250.000 Einwohnern . Die | Bibliothek | besteht aus einer Zentrale und | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,499 | 1,499 | mit 500.000 Medieneinheiten . Die | Bibliothek | gehört einem Bibliotheksverbund an . | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,502 | 1,502 | . Die Bibliothek gehört einem | Bibliotheksverbund | an . Die Bibliothek plant | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,506 | 1,506 | einem Bibliotheksverbund an . Die | Bibliothek | plant einen Neubau , der | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,542 | 1,542 | Universitätsbibliothek . Sie hat keine | bibliothekarische | Vorbildung . Alicia Meyer : | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,550 | 1,550 | Alicia Meyer : Alicia studiert | Bibliotheksmanagement | und plant eine Masterarbeit , | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,582 | 1,582 | ist nebenberuflich Lehrbeauftragter für einen | bibliothekarischen | Studiengang . Die interne Kommunikation | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,650 | 1,650 | und der Präsentation auf dem | Bibliothekskongress | abzuarbeiten . Nach außen hin | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,756 | 1,756 | der Bezug zu dem Thema | Bibliotheks-IT | . Die überwiegende Mehrheit stammte | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,766 | 1,766 | stammte aus dem Umfeld wissenschaftlicher | Bibliotheken | und konnte auf langjährige Berufserfahrung | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,776 | 1,776 | Berufserfahrung zurückblicken . Aus öffentlichen | Bibliotheken | war hingegen nur eine Person | bibliothek* |
| [6] - Nicolas Bach (2022). | 1,789 | 1,789 | ebenso vonseiten der Studierenden des | Bibliothekswesens | . Mit letztendlich nur drei | bibliothek* |
| [6] - Nicolas Bach (2022). | 2,068 | 2,068 | Kemner-Heek , Leiterin der Abteilung | Bibliotheksmanagementsysteme | beim GBV , und Marshall | bibliothek* |
| [6] - Nicolas Bach (2022). | 2,080 | 2,080 | , weltweit bekannter Consultant für | Bibliothekstechnologie | , erklärten sich bereit , | bibliothek* |
| [6] - Nicolas Bach (2022). | 3,184 | 3,184 | und der Vorstellung auf dem | Bibliothekskongress | 2022 aus . Die technische | bibliothek* |
| [6] - Nicolas Bach (2022). | 3,678 | 3,678 | im Rahmen des 8 . | Bibliothekskongresses | 2022 in Leipzig durch die | bibliothek* |
| [6] - Nicolas Bach (2022). | 3,785 | 3,785 | als studentischer Mitarbeiter in der | Bibliotheks-IT | einer großen Wissenschaftsorganisation Beiträge zu | bibliothek* |
| [6] - Nicolas Bach (2022). | 3,791 | 3,791 | einer großen Wissenschaftsorganisation Beiträge zu | Bibliotheksmanagement- | und Discovery-Systemen für das Handbuch | bibliothek* |
| [6] - Nicolas Bach (2022). | 3,801 | 3,801 | Handbuch “ Erfolgreiches Management von | Bibliotheken | und Informationseinrichtungen ” ( EMBI | bibliothek* |
| [6] - Nicolas Bach (2022). | 3,825 | 3,825 | Darstellung für vorwiegend Führungskräfte in | Bibliotheken | brachte dabei aber mit sich | bibliothek* |
| [6] - Nicolas Bach (2022). | 3,928 | 3,928 | dem Handbuch “ IT in | Bibliotheken | ” nun die Gelegenheit , | bibliothek* |
| [6] - Nicolas Bach (2022). | 3,997 | 3,997 | Weg , das Wissen der | Bibliotheks-IT | in Buchform zu transportieren . | bibliothek* |
| [6] - Nicolas Bach (2022). | 4,363 | 4,363 | Oberbegriffe wie “ Begriff ‚ | Bibliothekssystem | ‘ ” , “ Datenschutz | bibliothek* |
| [6] - Nicolas Bach (2022). | 4,401 | 4,401 | Rolle unserer Zielgruppe aus dem | Bibliothekswesen | ( siehe Personas in Abschnitt | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,002 | 5,002 | und Software Engineer bei einem | Bibliothekssoftwaredienstleister | , per Video zusammenschaltete , | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,028 | 5,028 | Sprints platzierte ich im DACH | Bibliothekswesen | Discord-Kanal Ankündigungen und informierte per | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,037 | 5,037 | informierte per E-Mail meine der | Bibliotheks-IT | nahestehenden Professoren über das Projekt | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,075 | 5,075 | als vergleichsweiser Neuling in der | Bibliotheks-IT | trotzdem alle der weiteren Anwesenden | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,215 | 5,215 | Sprint zum Handbuch IT in | Bibliothek | war für mich die bisher | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,246 | 5,246 | die ich bisher für das | Bibliothekswesen | zurückgelegt habe . Entsprechend empfand | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,591 | 5,591 | von uns geschriebenen Kapitel zu | Bibliotheksmanagementsystemen | erhielten . Im Nachhinein hat | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,654 | 5,654 | legen für ein Standardwerk der | Bibliotheks-IT | , bei dem jede * | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,695 | 5,695 | , für den vermutlich ersten | bibliothekarischen | Book Sprint in Deutschland nach | bibliothek* |
| [6] - Nicolas Bach (2022). | 5,757 | 5,757 | erfolgversprechenden Einsatz von KI in | Bibliotheken | . b.i.t.online 24 , 2 | bibliothek* |
| [7] - Tina Grahl (2021). S | 10 | 10 | GRAHL In einer Befragung der | Bibliothek | der TH Aschaffenburg wurde das | bibliothek* |
| [7] - Tina Grahl (2021). S | 451 | 451 | Hochschule Bayern 2020b ) . | Bibliotheken | an HAWs sollten daher Promovierende | bibliothek* |
| [7] - Tina Grahl (2021). S | 782 | 782 | wurde im Rahmen des Studiengangs | Bibliotheks- | und Informationswissenschaft ( MALIS ) | bibliothek* |
| [7] - Tina Grahl (2021). S | 1,568 | 1,568 | bestehenden Kurs- und Beratungsangeboten der | Bibliothek | wurde mit einer Likert-Skala mit | bibliothek* |
| [7] - Tina Grahl (2021). S | 1,855 | 1,855 | ( 8 ) , der | Bibliothekskatalog | ( 7 ) und Suchmaschinen | bibliothek* |
| [7] - Tina Grahl (2021). S | 3,147 | 3,147 | Informationen auf der Webseite der | Bibliothek | ( 5 ) . Es | bibliothek* |
| [7] - Tina Grahl (2021). S | 4,351 | 4,351 | Ergebnisse der zuvor durch die | Bibliotheksmitarbeiter | * in durchgeführte Plagiatsprüfung besprochen | bibliothek* |
| [7] - Tina Grahl (2021). S | 5,306 | 5,306 | Ein Leitfaden zur Didaktik von | Bibliothekskursen | . Berlin : De Gruyter | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 728 | 728 | Repositorium KOBRA , Kasseler Online | Bibliothek | Repository und Archiv , ( | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 914 | 914 | unstrittig ( vgl . Deutscher | Bibliotheksverband | 2020 ) . Mit Ausbruch | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 928 | 928 | der damit einhergehenden Schließung der | Bibliotheksstandorte | wurde die Relevanz für den | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 985 | 985 | Umfrage zu Lizenzierungsentscheidungen an wissenschaftlichen | Bibliotheken | und Regionalbibliotheken in Deutschland gaben | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 1,600 | 1,600 | Fachreferent * innen an die | Bibliotheksbeauftragten | und weitere Kontakte im Fachbereich | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 2,348 | 2,348 | Segment der Zweitveröffentlichungen , die | Bibliotheken | ohne weitere Rückfrage vornehmen dürfen | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 2,805 | 2,805 | Interesse an den auf der | Bibliothekskommissionssitzung | im November 2020 präsentierten Zwischenergebnissen | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 3,639 | 3,639 | es sich nicht um ein | bibliothekarisches | Binnenthema der Literaturversorgung handelt , | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 5,438 | 5,438 | Wissenschaftler * innen gibt der | Bibliothek | wertvolle Einsichten in die Publikationskultur | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 6,229 | 6,229 | zu Berlin veröffentlicht https://edoc.hu-berlin.de/. Deutscher | Bibliotheksverband | ( 2020 ) : Bericht | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 6,238 | 6,238 | : Bericht zur Lage der | Bibliotheken | : Fakten und Zahlen 2020–2021 | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 6,395 | 6,395 | aus der Universitätsbibliothek Kassel . | Bibliotheksdienst | 54 ( 12 ) , | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 6,562 | 6,562 | Erbe und zeitgemäße Informationsinfrastrukturen : | Bibliotheken | am Anfang des 21 . | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 6,626 | 6,626 | . O-Bib . Das Offene | Bibliotheksjournal | , 5 ( 4 ) | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 6,690 | 6,690 | Universitätsbibliothek , Landesbibliothek und Murhardsche | Bibliothek | der Stadt Kassel ( 2020 | bibliothek* |
| [8] - Sarah Dellmann, Arvi | 6,795 | 6,795 | : O-Bib . Das Offene | Bibliotheksjournal | 8 ( 1 ) , | bibliothek* |
| [9] - Berfu Erdogan, Chris | 461 | 461 | – Wissenschaftliche Universalbibliotheken des Deutschen | Bibliotheksverbandes | ( dbv ) sowie die | bibliothek* |
| [9] - Berfu Erdogan, Chris | 1,001 | 1,001 | durch die beteiligten Projekte und | Bibliotheken | stets dokumentiert werden . Die | bibliothek* |
| [10] - Grischa Fraumann, Ch | 511 | 511 | Handreichungen , die im Bereich | Bibliotheks- | und Informationswissenschaften veröffentlicht wurden , | bibliothek* |
| [11] - Christian Hauschke, | 2,991 | 2,991 | . O-bib . Das offene | Bibliotheksjournal | , 8 ( 1 ) | bibliothek* |
| [12] - Jana Madlen Schütte | 43 | 43 | Regionalbibliotheken zum Strategiepapier „ Wissenschaftliche | Bibliotheken | 2025 “ haben sie sich | bibliothek* |
| [12] - Jana Madlen Schütte | 56 | 56 | der Open-Access-Transformation bekannt . Die | Bibliotheken | beginnen aktuell damit , Publikationsservices | bibliothek* |
| [12] - Jana Madlen Schütte | 477 | 477 | gelenkt werden : Auf dem | Bibliothekartag | 2019 haben Anne May und | bibliothek* |
| [12] - Jana Madlen Schütte | 490 | 490 | von der Gottfried Wilhelm Leibniz | Bibliothek | ( GWLB ) in Hannover | bibliothek* |
| [12] - Jana Madlen Schütte | 551 | 551 | diese als Anknüpfungspunkte für andere | Bibliotheken | dieses Typs an ( May | bibliothek* |
| [12] - Jana Madlen Schütte | 579 | 579 | , die Gottfried Wilhelm Leibniz | Bibliothek | in Hannover und die Herzog | bibliothek* |
| [12] - Jana Madlen Schütte | 586 | 586 | Hannover und die Herzog August | Bibliothek | in Wolfenbüttel , im Rahmen | bibliothek* |
| [12] - Jana Madlen Schütte | 655 | 655 | Regionalbibliotheken zum Strategiepapier „ Wissenschaftliche | Bibliotheken | 2025 “ , die ebenfalls | bibliothek* |
| [12] - Jana Madlen Schütte | 1,058 | 1,058 | Forschungsbibliotheken bzw . diejenigen Öffentlichen | Bibliotheken | mit regionalem Charakter hier Entwicklungspotential | bibliothek* |
| [12] - Jana Madlen Schütte | 1,113 | 1,113 | Stellenwertes des Themas für den | Bibliothekstyp | und die eigene Einrichtung ist | bibliothek* |
| [12] - Jana Madlen Schütte | 1,619 | 1,619 | Regionalbibliotheken zum Strategiepapier „ Wissenschaftliche | Bibliotheken | 2025 " ( WB2025 ) | bibliothek* |
| [12] - Jana Madlen Schütte | 1,660 | 1,660 | am Beispiel der GWLB . | Bibliothekartag | 2019 [ Präsentationsfolien ] . | bibliothek* |
| [13] - Thomas Mutschler (20 | 250 | 250 | justiert , sondern auch die | Bibliothekswelt | grundlegend verändert . An zahlreichen | bibliothek* |
| [13] - Thomas Mutschler (20 | 258 | 258 | . An zahlreichen Standorten sind | Bibliotheken | nicht nur Servicepartner für die | bibliothek* |
| [13] - Thomas Mutschler (20 | 364 | 364 | der Sektion 4 des Deutschen | Bibliotheksverbands | ( AG Regionalbibliotheken ) wurde | bibliothek* |
| [13] - Thomas Mutschler (20 | 531 | 531 | AG Regionalbibliotheken zum Strategiepapier Wissenschaftliche | Bibliotheken | 2025 , welches ebenfalls ein | bibliothek* |
| [13] - Thomas Mutschler (20 | 983 | 983 | ) . Gleichzeitig wurden die | Bibliotheken | dazu aufgefordert , beim Aufbau | bibliothek* |
| [13] - Thomas Mutschler (20 | 1,004 | 1,004 | … ) werden die wissenschaftlichen | Bibliotheken | in Thüringen ihre Leistungen in | bibliothek* |
| [13] - Thomas Mutschler (20 | 1,061 | 1,061 | . Mitarbeiter * innen der | Bibliothek | schufen in Kooperation mit dem | bibliothek* |
| [13] - Thomas Mutschler (20 | 1,094 | 1,094 | sogenannten Hochschulschriftenservers . Die Digitale | Bibliothek | Thüringen ( https://www.db-thueringen.de ) war | bibliothek* |
| [13] - Thomas Mutschler (20 | 1,163 | 1,163 | Publizieren und den Aufbau digitaler | Bibliotheken | " fördern ( § 38 | bibliothek* |
| [13] - Thomas Mutschler (20 | 1,185 | 1,185 | Jahr 2001 hat die Digitale | Bibliothek | Thüringen mehrere Relaunches und Zertifizierungen | bibliothek* |
| [13] - Thomas Mutschler (20 | 1,272 | 1,272 | am Reichtum der in Thüringer | Bibliotheken | , Archiven und Museen verwahrten | bibliothek* |
| [13] - Thomas Mutschler (20 | 1,383 | 1,383 | da sie neben der Digitalen | Bibliothek | Thüringen einen zentralen Baustein innerhalb | bibliothek* |
| [13] - Thomas Mutschler (20 | 1,716 | 1,716 | sowohl in die Deutsche Digitale | Bibliothek | ( https://www.deutsche-digitale-bibliothek.de ) als auch | bibliothek* |
| [13] - Thomas Mutschler (20 | 2,091 | 2,091 | gestellt wurde und von der | Bibliothek | gemanagt wird . Auf der | bibliothek* |
| [13] - Thomas Mutschler (20 | 2,329 | 2,329 | ) in den Suchindex der | Bibliothek | . Der begonnene Ausbau der | bibliothek* |
| [13] - Thomas Mutschler (20 | 2,488 | 2,488 | Kontext des elektronischen Publizierens umfasst | bibliothekarische | Dienste und Beratungsangebote . Open | bibliothek* |
| [13] - Thomas Mutschler (20 | 2,839 | 2,839 | auch Werke sieht sich die | Bibliothek | als Servicepartner sowohl für die | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,034 | 3,034 | Landesbibliothek Jena zudem in den | Bibliotheksverbünden | zur Verfügung . Digitalisierte Quellen | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,062 | 3,062 | auch für die Organisation der | bibliothekarischen | Arbeitsprozesse mit sich – ein | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,091 | 3,091 | sowie in anderen Bereichen der | Bibliothek | machten sich mit den neuen | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,209 | 3,209 | die eigene Einrichtung . Die | Bibliothek | verifiziert nicht nur , wer | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,302 | 3,302 | beschränkt sich die Rolle der | Bibliotheken | im digitalen Zeitalter längst nicht | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,318 | 3,318 | Informations- und Literaturversorgung , sondern | Bibliotheken | sind heutzutage mehr denn je | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,411 | 3,411 | Auch auf die Organisation der | bibliothekarischen | Arbeitsprozesse hat die Open Access-Transformation | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,551 | 3,551 | Geschäftsmodelle stehen , ist für | Bibliotheken | mit ausschließlich regionalem Versorgungsauftrag nicht | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,585 | 3,585 | sofern dies aus Lizenzverträgen der | Bibliotheken | abgeleitet wird . Hinzu kommt | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,780 | 3,780 | ihre Publikationsinfrastruktur , sondern auch | bibliothekarisches | und wissenschaftliches Knowhow zur Verfügung | bibliothek* |
| [13] - Thomas Mutschler (20 | 3,808 | 3,808 | können , die Repositorien der | Bibliotheken | als primäre Publikationsplattformen zu nutzen | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,147 | 4,147 | für Einrichtungen im Mittelfeld der | Bibliotheksskala | nicht zu unterschätzen . Eine | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,425 | 4,425 | Regionalbibliotheken zum Strategiepapier „ Wissenschaftliche | Bibliotheken | 2025 " ( WB2025 ) | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,518 | 4,518 | Forschungsprojekte und digitale Editionen . | Bibliotheksdienst | 55 ( 1 ) . | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,545 | 4,545 | stärker . Die neue Digitale | Bibliothek | Thüringen ( DBT ) als | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,580 | 4,580 | der Siegeszug des Open Access | Bibliotheken | arbeitslos ? : 7 . | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,623 | 4,623 | 2013 ) : Thüringen . | Bibliotheksdienst | , 47 ( 8-9 ) | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,650 | 4,650 | der Kulturgutdigitalisierung in Thüringen . | Bibliotheksdienst | , 51 ( 3-4 ) | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,698 | 4,698 | . O-bib . Das offene | Bibliotheksjournal | , 7 ( 4 ) | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,764 | 4,764 | : Digitale Archive und virtuelle | Bibliotheken | auf der Basis von MyCoRe | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,870 | 4,870 | in Regionalbibliotheken . Zeitschrift für | Bibliothekswesen | und Bibliographie . Sonderbände , | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,902 | 4,902 | in Regionalbibliotheken . Zeitschrift für | Bibliothekswesen | und Bibliographie . Sonderbände , | bibliothek* |
| [13] - Thomas Mutschler (20 | 4,941 | 4,941 | seine Nachbarländer . Zeitschrift für | Bibliothekswesen | und Bibliographie . Sonderbände , | bibliothek* |
| [13] - Thomas Mutschler (20 | 5,052 | 5,052 | die Hochschulbibliotheken . Zeitschrift für | Bibliothekswesen | und Bibliographie , 63 ( | bibliothek* |
| [14] - Roberto Cozatl, Dani | 69 | 69 | , wie das Neudenken bestimmter | bibliothekarischer | Rollen und Strukturen , die | bibliothek* |
| [14] - Roberto Cozatl, Dani | 651 | 651 | Mitgliedern der oben genannten wissenschaftlichen | Bibliotheken | gebildet . Eines der Hauptziele | bibliothek* |
| [14] - Roberto Cozatl, Dani | 670 | 670 | seiner Mitglieder in Bezug auf | bibliothekarische | und publikationswissenschaftliche Angelegenheiten zu begleiten | bibliothek* |
| [14] - Roberto Cozatl, Dani | 722 | 722 | infrastrukturellen Entwicklungen ermöglichen es der | Bibliothek | , sich als Förderer des | bibliothek* |
| [14] - Roberto Cozatl, Dani | 936 | 936 | nur auf der Ebene der | Bibliotheken | als Einrichtungen mit einer wichtigen | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,357 | 1,357 | sollen , ist für die | Bibliotheken | des Landes die Erarbeitung von | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,413 | 1,413 | Publikation zu verknüpfen . Das | Bibliotheksservice-Zentrum | Baden-Württemberg ( BSZ ) und | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,460 | 1,460 | Strukturen Die kritische Rolle wissenschaftlicher | Bibliotheken | in der Open-Access-Transformation ist seit | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,523 | 1,523 | einer solchen Transformation identifiziert . | Bibliotheken | sollten , mit ihrer Erfahrung | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,595 | 1,595 | Herausforderungen bestehen darin , dass | Bibliotheken | sich weiterentwickeln , neue Rollen | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,618 | 1,618 | erfolgreich zu sein . Auf | bibliotheksinterner | Ebene wurden für die Unterstützung | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,793 | 1,793 | Umstrukturierung in der Organisation der | Bibliothek | vorgenommen , um den neuen | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,808 | 1,808 | Anforderungen an die Geschäftsgänge der | Bibliothek | Rechnung zu tragen . Konkret | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,826 | 1,826 | welche in den Geschäftsgängen der | Bibliothek | mit der Bearbeitung von Publikationsfonds | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,877 | 1,877 | in den entsprechenden Fachabteilungen der | Bibliothek | . Ziel ist , das | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,893 | 1,893 | Arbeitsabläufe zu integrieren und durch | Bibliotheksmitarbeiter | * innen routinemäßig zu unterstützen | bibliothek* |
| [14] - Roberto Cozatl, Dani | 1,986 | 1,986 | Leben gerufen , das den | Bibliotheksmitarbeiter | * innen gezieltes Feedback geben | bibliothek* |
| [14] - Roberto Cozatl, Dani | 2,159 | 2,159 | und dynamische Zusammenarbeit zwischen den | Bibliotheken | des Landes erreicht . Die | bibliothek* |
| [14] - Roberto Cozatl, Dani | 2,252 | 2,252 | ULB aber auch in anderen | Bibliotheken | des Landes , wie z | bibliothek* |
| [14] - Roberto Cozatl, Dani | 2,868 | 2,868 | Saale ) hat und deren | Bibliothek | als kleinere wissenschaftliche Bibliothek des | bibliothek* |
| [14] - Roberto Cozatl, Dani | 2,872 | 2,872 | deren Bibliothek als kleinere wissenschaftliche | Bibliothek | des Landes Sachsen-Anhalt in verschiedenen | bibliothek* |
| [14] - Roberto Cozatl, Dani | 2,878 | 2,878 | des Landes Sachsen-Anhalt in verschiedenen | bibliothekarischen | Services ( Bibliothekssystemverwaltung ) durch | bibliothek* |
| [14] - Roberto Cozatl, Dani | 2,881 | 2,881 | in verschiedenen bibliothekarischen Services ( | Bibliothekssystemverwaltung | ) durch die ULB Sachsen-Anhalt | bibliothek* |
| [14] - Roberto Cozatl, Dani | 3,443 | 3,443 | Regionalmuseen , Archive und kleinerer | Bibliotheken | einem breiteren Publikum darstellen . | bibliothek* |
| [14] - Roberto Cozatl, Dani | 3,956 | 3,956 | Abteilungen / Teams innerhalb der | Bibliotheken | müssen neu durchdacht werden . | bibliothek* |
| [14] - Roberto Cozatl, Dani | 4,716 | 4,716 | . Open Science und die | Bibliothek | – Aktionsfelder und Berufsbild . | bibliothek* |
| [14] - Roberto Cozatl, Dani | 4,726 | 4,726 | . Mitteilungen der Vereinigung Österreichischer | Bibliothekarinnen | und Bibliothekare Vol 72 , | bibliothek* |
| [14] - Roberto Cozatl, Dani | 4,728 | 4,728 | der Vereinigung Österreichischer Bibliothekarinnen und | Bibliothekare | Vol 72 , No . | bibliothek* |
| [14] - Roberto Cozatl, Dani | 4,781 | 4,781 | ihre Bedeutung für die wissenschaftlichen | Bibliotheken | : Eine Analyse von Positionspapieren | bibliothek* |
| [14] - Roberto Cozatl, Dani | 4,826 | 4,826 | . Neue Aufgaben für wissenschaftliche | Bibliotheken | : Das Beispiel Open Science | bibliothek* |
| [14] - Roberto Cozatl, Dani | 4,838 | 4,838 | . o-bib . Das offene | Bibliotheksjournal | / herausgegeben vom VDB Vol | bibliothek* |
| [14] - Roberto Cozatl, Dani | 5,076 | 5,076 | ↩ Eine Liste der teilnehmenden | Bibliotheken | kann über den Link abgerufen | bibliothek* |
| [15] - Wolf Christoph Seife | 48 | 48 | Positionierung zum Strategiepapier ‚ Wissenschaftliche | Bibliotheken | 2025 festgehaltenen strategischen Überlegungen der | bibliothek* |
| [15] - Wolf Christoph Seife | 143 | 143 | Positionierung zum Strategiepapier “ Wissenschaftliche | Bibliotheken | 2025 ” ) , this | bibliothek* |
| [15] - Wolf Christoph Seife | 241 | 241 | im Serviceportfolio der ihnen zugehörigen | Bibliotheken | nieder . Die Förderung eines | bibliothek* |
| [15] - Wolf Christoph Seife | 320 | 320 | den 2018 im Papier Wissenschaftliche | Bibliotheken | 2025 vorgezeichneten Entwicklungsfeldern für wissenschaftliche | bibliothek* |
| [15] - Wolf Christoph Seife | 326 | 326 | 2025 vorgezeichneten Entwicklungsfeldern für wissenschaftliche | Bibliotheken | wird das Feld ‚ Open | bibliothek* |
| [15] - Wolf Christoph Seife | 348 | 348 | gesetzt ( vgl . Deutscher | Bibliotheksverband | e.V . 2018 ) . | bibliothek* |
| [15] - Wolf Christoph Seife | 358 | 358 | . Bei der Positionsbestimmung von | Bibliotheken | in diesem Aufgabengebiet sollte der | bibliothek* |
| [15] - Wolf Christoph Seife | 438 | 438 | Positionierung zum Strategiepapier ‚ Wissenschaftliche | Bibliotheken | 2025 ’ ( Jendral u.a | bibliothek* |
| [15] - Wolf Christoph Seife | 664 | 664 | den Direktionen der Herzog August | Bibliothek | Wolfenbüttel und der Gottfried Wilhelm | bibliothek* |
| [15] - Wolf Christoph Seife | 671 | 671 | und der Gottfried Wilhelm Leibniz | Bibliothek | Hannover entwickelt und von Mai | bibliothek* |
| [15] - Wolf Christoph Seife | 735 | 735 | Repräsentativität für das heterogene regionale | Bibliothekswesen | ausgewählten Bibliotheksgruppe ) . Der | bibliothek* |
| [15] - Wolf Christoph Seife | 737 | 737 | das heterogene regionale Bibliothekswesen ausgewählten | Bibliotheksgruppe | ) . Der vorliegende Beitrag | bibliothek* |
| [15] - Wolf Christoph Seife | 802 | 802 | der ausgeprägten regionalen und nationalen | bibliotheksplanerischen | Aktivitäten der 60er und 70er | bibliothek* |
| [15] - Wolf Christoph Seife | 850 | 850 | anderen unter diesem Label gefassten | Bibliotheken | . So vordergründig klar die | bibliothek* |
| [15] - Wolf Christoph Seife | 876 | 876 | 78–80 zu den Regelungen im | Bibliotheksplan | 1973 ) gefasste Funktion der | bibliothek* |
| [15] - Wolf Christoph Seife | 882 | 882 | 1973 ) gefasste Funktion der | Bibliotheken | räumlich – eben regional – | bibliothek* |
| [15] - Wolf Christoph Seife | 911 | 911 | geben zuweilen die Bezeichnungen der | Bibliotheken | , in denen die Herkunft | bibliothek* |
| [15] - Wolf Christoph Seife | 1,023 | 1,023 | , sich im Zuge der | bibliothekspolitischen | Überlegungen der 60er Jahre herausschält | bibliothek* |
| [15] - Wolf Christoph Seife | 1,040 | 1,040 | und derjenigen der kommunalen wissenschaftlichen | Bibliotheken | adaptiert wird , die 1971 | bibliothek* |
| [15] - Wolf Christoph Seife | 1,090 | 1,090 | als fürstliche Büchersammlungen oder als | Bibliotheken | des städtischen Rates – entstanden | bibliothek* |
| [15] - Wolf Christoph Seife | 1,220 | 1,220 | die sich entlang der maßgeblichen | bibliothekspolitischen | Pläne der 60er und 70er | bibliothek* |
| [15] - Wolf Christoph Seife | 1,609 | 1,609 | Überlegungen des dbv ( Deutscher | Bibliotheksverband | e.V . 2018 ) auf | bibliothek* |
| [15] - Wolf Christoph Seife | 1,885 | 1,885 | zur näheren Typisierung der teilnehmenden | Bibliotheken | erhoben : die Bestandsgröße , | bibliothek* |
| [15] - Wolf Christoph Seife | 1,912 | 1,912 | Forschungsbibliothek , Universitätsbibliothek , öffentliche | Bibliothek | ( s.u . , 4.1 | bibliothek* |
| [15] - Wolf Christoph Seife | 1,980 | 1,980 | widmeten sich dem Engagement der | Bibliotheken | im Bereich des kulturellen Erbes | bibliothek* |
| [15] - Wolf Christoph Seife | 2,109 | 2,109 | deckten das ganze Spektrum der | Bibliothekstypen | ab . Unter diesen war | bibliothek* |
| [15] - Wolf Christoph Seife | 2,144 | 2,144 | 35 % ) der teilnehmenden | Bibliotheken | waren Universitätsbibliotheken , die zugleich | bibliothek* |
| [15] - Wolf Christoph Seife | 2,175 | 2,175 | sich dem Typ ‚ Öffentliche | Bibliothek | mit regionalem Schwerpunkt ’ zu | bibliothek* |
| [15] - Wolf Christoph Seife | 2,202 | 2,202 | Bestandseinheiten . Zwei der teilnehmenden | Bibliotheken | befinden sich in Österreich , | bibliothek* |
| [15] - Wolf Christoph Seife | 2,222 | 2,222 | Welchem Typ würden Sie ihre | Bibliothek | zuordnen ? ( Werte gerundet | bibliothek* |
| [15] - Wolf Christoph Seife | 2,377 | 2,377 | , die zwischen den einzelnen | Bibliothekstypen | bestehen . Aus der Gesamtgruppe | bibliothek* |
| [15] - Wolf Christoph Seife | 2,745 | 2,745 | in allen vier befragten öffentlichen | Bibliotheken | werden Mitarbeiter * innen zum | bibliothek* |
| [15] - Wolf Christoph Seife | 2,769 | 2,769 | bereits deutliche Entwicklungsunterschiede zwischen den | Bibliothekstypen | suggerieren , lässt sich mit | bibliothek* |
| [15] - Wolf Christoph Seife | 2,832 | 2,832 | Nutzbarmachung unter offenen Lizenzen erfüllen | Bibliotheken | eine ihrer zentralen Funktionen und | bibliothek* |
| [15] - Wolf Christoph Seife | 2,880 | 2,880 | die Entwicklungsdifferenzen zwischen den einzelnen | Bibliothekstypen | sich kaum niederschlagen . Insgesamt | bibliothek* |
| [15] - Wolf Christoph Seife | 2,898 | 2,898 | 34 an der Umfrage beteiligten | Bibliotheken | an , Objekte des kulturellen | bibliothek* |
| [15] - Wolf Christoph Seife | 3,697 | 3,697 | und immerhin eine der öffentlichen | Bibliotheken | erschließen derzeit wissenschaftliche Open-Access-Publikationen , | bibliothek* |
| [15] - Wolf Christoph Seife | 3,822 | 3,822 | 50 % ) der öffentlichen | Bibliotheken | archiviert und zugänglich gemacht ( | bibliothek* |
| [15] - Wolf Christoph Seife | 3,867 | 3,867 | und zwar über alle drei | Bibliothekstypen | hinweg . Abb . 6 | bibliothek* |
| [15] - Wolf Christoph Seife | 4,051 | 4,051 | und Forschungsbibliotheken sowie der öffentlichen | Bibliotheken | andererseits ) Entwicklungsunterschiede deutlich . | bibliothek* |
| [15] - Wolf Christoph Seife | 4,251 | 4,251 | . Dass in den öffentlichen | Bibliotheken | die Entwicklungen im Bereich Open | bibliothek* |
| [15] - Wolf Christoph Seife | 4,313 | 4,313 | Ergebnisse auf Seiten der öffentlichen | Bibliotheken | hier ( wie in der | bibliothek* |
| [15] - Wolf Christoph Seife | 4,338 | 4,338 | die Gruppe mit vier zugehörigen | Bibliotheken | sehr klein ist . Abb | bibliothek* |
| [15] - Wolf Christoph Seife | 4,613 | 4,613 | einer OJS-Installation gerade in kleineren | Bibliotheken | zu viele Ressourcen binden würde | bibliothek* |
| [15] - Wolf Christoph Seife | 4,862 | 4,862 | Bedürfnisse derjenigen ( kleineren ) | Bibliotheken | , die nicht über einen | bibliothek* |
| [15] - Wolf Christoph Seife | 4,931 | 4,931 | Landesbibliotheken einerseits und den öffentlichen | Bibliotheken | andererseits . Das gerade in | bibliothek* |
| [15] - Wolf Christoph Seife | 5,153 | 5,153 | Forschungsbibliotheken und die wenigen öffentlichen | Bibliotheken | , die regionalbibliothekarische Aufgaben übernehmen | bibliothek* |
| [15] - Wolf Christoph Seife | 5,370 | 5,370 | wir einige Grundangaben zu Ihrer | Bibliothek | , die unter anderem dazu | bibliothek* |
| [15] - Wolf Christoph Seife | 5,398 | 5,398 | Sie bitten den Namen Ihrer | Bibliothek | ! 2 . Welchem Typ | bibliothek* |
| [15] - Wolf Christoph Seife | 5,407 | 5,407 | Welchem Typ würden Sie ihre | Bibliothek | zuordnen ( Mehrfachnennungen möglich ) | bibliothek* |
| [15] - Wolf Christoph Seife | 5,434 | 5,434 | Landesbibliothek oder Forschungsbibliothek / Öffentliche | Bibliothek | mit regionalbibliothekarischen Aufgaben / Anderer | bibliothek* |
| [15] - Wolf Christoph Seife | 5,452 | 5,452 | welchem Bundesland befindet sich Ihre | Bibliothek | ? Bitte wählen Sie nur | bibliothek* |
| [15] - Wolf Christoph Seife | 5,497 | 5,497 | Schleswig-Holstein / Thüringen / Meine | Bibliothek | befindet sich in Österreich / | bibliothek* |
| [15] - Wolf Christoph Seife | 5,504 | 5,504 | sich in Österreich / Meine | Bibliothek | befindet sich in der Schweiz | bibliothek* |
| [15] - Wolf Christoph Seife | 7,273 | 7,273 | am 23.3.2021 . https://www.dfg.de/foerderung/programme/infrastruktur/lis/lis_foerderangebote/open_access_publikationskosten/index.html Deutscher | Bibliotheksverband | e.V . ( 2018 ) | bibliothek* |
| [15] - Wolf Christoph Seife | 7,281 | 7,281 | ( 2018 ) : Wissenschaftliche | Bibliotheken | 2025 : beschlossen von der | bibliothek* |
| [15] - Wolf Christoph Seife | 7,295 | 7,295 | Wissenschaftliche Universalbibliotheken " im Deutschen | Bibliotheksverband | e.V . ( dbv ) | bibliothek* |
| [15] - Wolf Christoph Seife | 7,330 | 7,330 | , Kooperationen , Reorganisationen . | Bibliotheksdienst | 48 ( 7 ) , | bibliothek* |
| [15] - Wolf Christoph Seife | 7,366 | 7,366 | Regionalbibliotheken zum Strategiepapier „ Wissenschaftliche | Bibliotheken | 2025 " ( WB2025 ) | bibliothek* |
| [15] - Wolf Christoph Seife | 7,387 | 7,387 | 1980 ) : Das wissenschaftliche | Bibliothekswesen | in der Bundesrepublik Deutschland : | bibliothek* |
| [15] - Wolf Christoph Seife | 7,396 | 7,396 | Deutschland : I : Die | Bibliotheken | / Aufgaben und Strukturen . | bibliothek* |
| [15] - Wolf Christoph Seife | 7,417 | 7,417 | : Klostermann . ( Das | Bibliothekswesen | in Einzeldarstellungen , 1 ) | bibliothek* |
| [15] - Wolf Christoph Seife | 7,438 | 7,438 | : Wissenschaft , Verlage und | Bibliotheken | in der digitalen Transformation des | bibliothek* |
| [15] - Wolf Christoph Seife | 7,446 | 7,446 | digitalen Transformation des Publikationswesens . | Bibliothek | Forschung und Praxis 42 ( | bibliothek* |
| [15] - Wolf Christoph Seife | 7,479 | 7,479 | ( 1999 ) : Das | Bibliothekswesen | der Bundesrepublik Deutschland : Ein | bibliothek* |
| [15] - Wolf Christoph Seife | 7,595 | 7,595 | liegt in der Vergangenheit . | Bibliothek | Forschung und Praxis 37 ( | bibliothek* |
| [15] - Wolf Christoph Seife | 7,651 | 7,651 | Klostermann . ( Zeitschrift für | Bibliothekswesen | und Bibliographie / Sonderhefte , | bibliothek* |
| [16] - Martin Munke, Daniel | 226 | 226 | auf das Positionspapier „ Wissenschaftliche | Bibliotheken | 2025 " der Sektion 4 | bibliothek* |
| [16] - Martin Munke, Daniel | 234 | 234 | der Sektion 4 im Deutschen | Bibliotheksverband | e.V . ( dbv ) | bibliothek* |
| [16] - Martin Munke, Daniel | 260 | 260 | Entwicklung und das Engagement solcher | Bibliotheken | . Es sollen u . | bibliothek* |
| [16] - Martin Munke, Daniel | 325 | 325 | sowie “ kleinere Einrichtungen ( | Bibliotheken | , Archive , historische Vereine | bibliothek* |
| [16] - Martin Munke, Daniel | 432 | 432 | Koordinierungs- und Dienstleistungsfunktionen für die | Bibliotheken | im Freistaat Sachsen , nicht | bibliothek* |
| [16] - Martin Munke, Daniel | 636 | 636 | mit diesem Aufgabenbereich großer wissenschaftlicher | Bibliotheken | verbunden . Gleichwohl sind sie | bibliothek* |
| [16] - Martin Munke, Daniel | 808 | 808 | der Sächsischen Landesbibliothek mit der | Bibliothek | der Technischen Universität Dresden begründet | bibliothek* |
| [16] - Martin Munke, Daniel | 871 | 871 | . durch den Ankauf der | Bibliotheken | Heinrich Graf von Brühls ( | bibliothek* |
| [16] - Martin Munke, Daniel | 938 | 938 | ) , der die Kurfürstliche | Bibliothek | seit 1787 leitete . In | bibliothek* |
| [16] - Martin Munke, Daniel | 989 | 989 | Publica ’ ( Kurfürstliche Öffentliche | Bibliothek | ) , ab 1806 dann | bibliothek* |
| [16] - Martin Munke, Daniel | 998 | 998 | 1806 dann als Königliche Öffentliche | Bibliothek | . Bedeutende Erweiterungen erfuhr der | bibliothek* |
| [16] - Martin Munke, Daniel | 1,224 | 1,224 | eng mit der Königlichen Öffentlichen | Bibliothek | bzw . ab 1917 ( | bibliothek* |
| [16] - Martin Munke, Daniel | 1,289 | 1,289 | – seit 1869 an der | Bibliothek | beschäftigt , seit 1896 als | bibliothek* |
| [16] - Martin Munke, Daniel | 1,334 | 1,334 | erfolgten diese in Verantwortung der | Bibliothek | . In den Werken von | bibliothek* |
| [16] - Martin Munke, Daniel | 1,374 | 1,374 | deren Manuskript ebenfalls an der | Bibliothek | erarbeitet werden sollte . Das | bibliothek* |
| [16] - Martin Munke, Daniel | 1,516 | 1,516 | in das Verbundsystem des Südwestdeutschen | Bibliotheksverbunds | ( SWB ) . Bereits | bibliothek* |
| [16] - Martin Munke, Daniel | 1,864 | 1,864 | Kulturgut aus wissenschaftlichen und öffentlichen | Bibliotheken | sowie aus weiteren Kultur- und | bibliothek* |
| [16] - Martin Munke, Daniel | 2,269 | 2,269 | nehmen weitere wissenschaftliche und öffentliche | Bibliotheken | und Archive , auch in | bibliothek* |
| [16] - Martin Munke, Daniel | 2,879 | 2,879 | auf weitere relevante Titel im | Bibliotheksbestand | , die Abgabe bisher nicht | bibliothek* |
| [16] - Martin Munke, Daniel | 2,889 | 2,889 | nicht vorhandener Veröffentlichungen an die | Bibliothek | sowie zusätzliche Forschungsarbeiten zum Thema | bibliothek* |
| [16] - Martin Munke, Daniel | 5,208 | 5,208 | bei diesen Beispielen unterstützt die | Bibliothek | auch Neugründungen von frei zugänglichen | bibliothek* |
| [16] - Martin Munke, Daniel | 5,531 | 5,531 | mehr die institutionelle Bedeutung von | Bibliotheken | für die infrastrukturellen Voraussetzungen von | bibliothek* |
| [16] - Martin Munke, Daniel | 5,580 | 5,580 | . Open Access als wichtige | Bibliotheksstrategie | weiter verfolgend , setzt die | bibliothek* |
| [16] - Martin Munke, Daniel | 5,694 | 5,694 | Heimatschutz ’ befindet sich die | Bibliothek | in fortgesetzten Gesprächen , im | bibliothek* |
| [16] - Martin Munke, Daniel | 5,884 | 5,884 | Zeitschriften ein erklärtes Ziel der | Bibliothek | . Eine Open Access-Veröffentlichung dieser | bibliothek* |
| [16] - Martin Munke, Daniel | 5,943 | 5,943 | . Im Hintergrund arbeiteten die | Bibliotheksmitarbeiter9 | an der Überführung der betreffenden | bibliothek* |
| [16] - Martin Munke, Daniel | 6,072 | 6,072 | SLUBArchivs entsprechen . Auf der | bibliothekseigenen | Homepage wird neben umfangreichem Informationsmaterial | bibliothek* |
| [16] - Martin Munke, Daniel | 6,562 | 6,562 | Hinsichtlich der Dokumentbearbeitung in der | Bibliothek | handelt es sich hierbei jedoch | bibliothek* |
| [16] - Martin Munke, Daniel | 6,787 | 6,787 | auf die traditionellen Aufgaben der | Bibliothek | als Landes- und Staatsbibliothek zurückführen | bibliothek* |
| [16] - Martin Munke, Daniel | 6,884 | 6,884 | und Gesellschaft " schreibt die | Bibliothek | das Bekenntnis zu Open Science | bibliothek* |
| [16] - Martin Munke, Daniel | 7,735 | 7,735 | BIS - das Magazin der | Bibliotheken | in Sachsen 1 , 3 | bibliothek* |
| [16] - Martin Munke, Daniel | 7,767 | 7,767 | Sächsischer Akademie der Wissenschaften und | Bibliotheken | . In BIS - das | bibliothek* |
| [16] - Martin Munke, Daniel | 7,775 | 7,775 | BIS - das Magazin der | Bibliotheken | in Sachsen 2 , 2 | bibliothek* |
| [16] - Martin Munke, Daniel | 7,826 | 7,826 | zu Berlin , Institut für | Bibliotheks- | und Informationswissenschaft . Bemme , | bibliothek* |
| [16] - Martin Munke, Daniel | 7,851 | 7,851 | für kuratorische Praktiken in Wissenschaftlichen | Bibliotheken | . Werner , Klaus Ulrich | bibliothek* |
| [16] - Martin Munke, Daniel | 7,862 | 7,862 | ( Hg . ) . | Bibliotheken | als Orte kuratorischer Praxis ( | bibliothek* |
| [16] - Martin Munke, Daniel | 7,868 | 7,868 | als Orte kuratorischer Praxis ( | Bibliotheks- | und Informationspraxis , 67 ) | bibliothek* |
| [16] - Martin Munke, Daniel | 7,921 | 7,921 | . In BuB . Forum | Bibliothek | und Information 68 , 7 | bibliothek* |
| [16] - Martin Munke, Daniel | 8,203 | 8,203 | ( Hg . ) . | Bibliothek | der Zukunft – Zukunft der | bibliothek* |
| [16] - Martin Munke, Daniel | 8,209 | 8,209 | der Zukunft – Zukunft der | Bibliothek | . Festschrift für Elmar Mittler | bibliothek* |
| [16] - Martin Munke, Daniel | 8,445 | 8,445 | . Ein Praxisbericht . In | Bibliothek | . Forschung & Praxis 44 | bibliothek* |
| [16] - Martin Munke, Daniel | 8,483 | 8,483 | zum Fachinformationsdienst Kunst . In | Bibliothek | . Forschung & Praxis 38 | bibliothek* |
| [16] - Martin Munke, Daniel | 8,513 | 8,513 | BIS - das Magazin der | Bibliotheken | in Sachsen 6 , 1 | bibliothek* |
| [16] - Martin Munke, Daniel | 8,605 | 8,605 | die Schweiz ( Zeitschrift für | Bibliothekswesen | und Bibliographie . Sonderbände 78 | bibliothek* |
| [16] - Martin Munke, Daniel | 8,874 | 8,874 | BIS - das Magazin der | Bibliotheken | in Sachsen 2 , 4 | bibliothek* |
| [16] - Martin Munke, Daniel | 9,075 | 9,075 | seine Nachbarländer ( Zeitschrift für | Bibliothekswesen | und Bibliographie . Sonderbände , | bibliothek* |
| [16] - Martin Munke, Daniel | 9,120 | 9,120 | BIS - das Magazin der | Bibliotheken | in Sachsen 5 , 3 | bibliothek* |
| [16] - Martin Munke, Daniel | 9,278 | 9,278 | der SLUB Dresden . In | Bibliotheksdienst | , 52 , 2 , | bibliothek* |
| [16] - Martin Munke, Daniel | 9,365 | 9,365 | Chancen und Herausforderungen für wissenschaftliche | Bibliotheken | . In Bredemeier Willi u | bibliothek* |
| [16] - Martin Munke, Daniel | 9,379 | 9,379 | ( Hg . ) . | Bibliotheken | : Wegweiser in die Zukunft | bibliothek* |
| [16] - Martin Munke, Daniel | 9,395 | 9,395 | Berlin : Simon Verlag für | Bibliothekswissen | [ im Erscheinen ] . | bibliothek* |
| [16] - Martin Munke, Daniel | 9,540 | 9,540 | . Vernetzte Beiträge von wissenschaftlichen | Bibliotheken | und Wiki-Communitys für eine digitale | bibliothek* |
| [18] - Markus Putnings (202 | 11 | 11 | Im Lockdown können nicht alle | Bibliotheksangestellten | ihre Tätigkeiten in Telearbeit ausführen | bibliothek* |
| [18] - Markus Putnings (202 | 242 | 242 | Gesundheit und Pflege mussten wissenschaftliche | Bibliotheken | in Bayern 2020 wegen der | bibliothek* |
| [18] - Markus Putnings (202 | 366 | 366 | Eure Aufgaben ? ” auf | Bibliothekarisch.de | . Mutmaßlich gibt es daneben | bibliothek* |
| [18] - Markus Putnings (202 | 412 | 412 | eine Sammlung mit Fortbildungsangeboten von | bibliothekarischen | Themen bis hin zu Sprachkursen | bibliothek* |
| [18] - Markus Putnings (202 | 665 | 665 | . In der Kommunikation wissenschaftlicher | Bibliotheken | ist noch ein breites Spektrum | bibliothek* |
| [18] - Markus Putnings (202 | 704 | 704 | der frei zugängliche Marketing-Baukasten auf | bibliotheksportal.de | dienen . Neben möglichen analytischen | bibliothek* |
| [18] - Markus Putnings (202 | 852 | 852 | jedoch leicht über ein Screening | bibliothekarischer | Fachzeitschriften und Fortbildungsportale bzw . | bibliothek* |
| [18] - Markus Putnings (202 | 867 | 867 | . Fort- und Weiterbildung auf | bibliotheksportal.de | ) einholen . Das konkrete | bibliothek* |
| [18] - Markus Putnings (202 | 948 | 948 | sogar als Artikel in einer | bibliothekarischen | Fachzeitschrift . Zudem muss berücksichtigt | bibliothek* |
| [18] - Markus Putnings (202 | 1,006 | 1,006 | Stabi bleibt geöffnet ! : | Bibliotheksarbeit | an der Staats- und Universitätsbibliothek | bibliothek* |
| [18] - Markus Putnings (202 | 1,021 | 1,021 | Corona . BuB : Forum | Bibliothek | und Information 72 ( 5 | bibliothek* |
| [18] - Markus Putnings (202 | 1,048 | 1,048 | Elke 2006 . Zugang zu | Bibliotheken | für Menschen mit Behinderungen : | bibliothek* |
| [18] - Markus Putnings (202 | 1,087 | 1,087 | . Welche IT-Kenntnisse benötigen werdende | Bibliothekare | ? : Studie zu geforderten | bibliothek* |
| [18] - Markus Putnings (202 | 1,095 | 1,095 | Studie zu geforderten IT-Kenntnissen in | Bibliotheken | verschiedener Typen und Größen . | bibliothek* |
| [18] - Markus Putnings (202 | 1,153 | 1,153 | gibt die Informationsseite des Deutschen | Bibliotheksverbands | e.V . ↩ Die Art | bibliothek* |
| [18] - Markus Putnings (202 | 1,204 | 1,204 | ” als positiver Beitrag der | Bibliotheken | zu den Dimensionen Soziales , | bibliothek* |
| [19] - Irene Barbers, Sonja | 5,563 | 5,563 | einer genaueren Betrachtung . Im | bibliothekarischen | Alltag scheint diesbezüglich ein hohes | bibliothek* |
| [19] - Irene Barbers, Sonja | 5,842 | 5,842 | Open Access-Publikationen vollständig über die | Bibliothek | abzuwickeln , was vielfach noch | bibliothek* |
| [19] - Irene Barbers, Sonja | 5,858 | 5,858 | die zentrale Rechnungsbearbeitung in der | Bibliothek | als One-Stop-Shop verringert sich der | bibliothek* |
| [19] - Irene Barbers, Sonja | 5,873 | 5,873 | * innen , wobei die | Bibliothek | als Nebeneffekt einen umfänglichen Überblick | bibliothek* |
| [19] - Irene Barbers, Sonja | 6,127 | 6,127 | Publikationsgebühren und ihre Rolle in | Bibliotheken | . Jülich . URL : | bibliothek* |
| [20] - Stefanie Hanneken, A | 67 | 67 | für Verlage als auch für | Bibliotheken | gleichermaßen tragbar , transparent und | bibliothek* |
| [20] - Stefanie Hanneken, A | 787 | 787 | verschiedene , koexistente Modelle wie | Bibliotheks-Crowdfunding | , partnerschaftliche Unterstützung , Fakultäts- | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,049 | 1,049 | dazu führt , dass die | Bibliotheken | sich kaum an solchen Initiativen | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,103 | 1,103 | von einem international besetzten , | bibliothekarischen | Titelauswahlkomitee ausgewählt . Die Beteiligung | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,110 | 1,110 | ausgewählt . Die Beteiligung von | Bibliotheken | aus Deutschland an solchen Programmen | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,207 | 1,207 | größten Teil akademische und wissenschaftliche | Bibliotheken | , die über ein ansprechendes | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,270 | 1,270 | . Dafür werden Elemente eines | Bibliotheksförderungs- | , eines kollaborativen / kooperativen | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,292 | 1,292 | für den Verlag und die | Bibliotheken | gleichermaßen tragbaren , transparenten und | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,347 | 1,347 | berücksichtigt werden müssen . Wissenschaftliche | Bibliotheken | haben verschiedene Möglichkeiten der Beschaffung | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,395 | 1,395 | Springer-Verlages die bisher verbreitetsten und | Bibliotheken | mit dieser Form der Erwerbung | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,417 | 1,417 | auch auf diesem Modell . | Bibliotheken | „ kaufen " die Frontlist | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,536 | 1,536 | erwerben , ermöglichen die teilnehmenden | Bibliotheken | über eine Gebühr im Crowdfunding-Modell | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,556 | 1,556 | Verlages . Die Erwerbungsmittel der | Bibliotheken | fließen so in die Finanzierung | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,577 | 1,577 | kostenpflichtiger eBooks für eine einzelne | Bibliothek | . Die Produktionskosten sowie die | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,608 | 1,608 | / AutorInnenzuschuss sowie durch die | Bibliotheken | finanziert . 8 Dafür legt | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,769 | 1,769 | die notwendigen Mittel unter den | Bibliotheken | einsammelt , bis die Gesamtsumme | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,846 | 1,846 | Unlatched durch die Beteiligung von | Bibliotheken | eingesammelt ( sogenannte SponsorInnen ) | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,856 | 1,856 | ) . Alternativ konnten die | Bibliotheken | sich auch über einen der | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,863 | 1,863 | auch über einen der etablierten | Bibliothekslieferanten | ( Dietmar Dreyer , Missing | bibliothek* |
| [20] - Stefanie Hanneken, A | 1,911 | 1,911 | den Vorteil , dass die | Bibliotheken | auf bekannte Bezugswege zurückgreifen können | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,026 | 2,026 | in die finanzielle Beteiligung der | Bibliotheken | zu bringen , wurde eine | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,235 | 2,235 | aus der Frontlist für ihren | Bibliotheksbestand | . Der FID und die | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,350 | 2,350 | Anreize für die Beteiligung der | Bibliotheken | an der Finanzierung und verringern | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,551 | 2,551 | Pollux und 45 beteiligten wissenschaftlichen | Bibliotheken | die Publikation der 20 Open-Access-eBooks | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,702 | 2,702 | eine Übersicht aller Beteiligten wissenschaftlichen | Bibliotheken | ( transcript 2019 ) . | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,731 | 2,731 | des FIDs Pollux , welche | Bibliotheken | eine finanzielle Beteiligung zugesagt haben | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,760 | 2,760 | . Dadurch kann jede mitfinanzierende | Bibliothek | und jede / r Interessierte | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,831 | 2,831 | Diese Qualitätsstandards zeigen den interessierten | Bibliotheken | , AutorInnen und LeserInnen , | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,929 | 2,929 | beteiligten Akteuren ( AutorInnen , | Bibliotheken | , Verlage , Intermediäre und | bibliothek* |
| [20] - Stefanie Hanneken, A | 2,998 | 2,998 | . Außerdem erhalten finanziell beteiligte | Bibliotheken | exklusive Benefits , sodass die | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,067 | 3,067 | unnötig und das Risiko für | Bibliotheken | , nur schlecht nachgefragte Titel | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,120 | 3,120 | . Es transformiert eBooks und | Bibliotheksetats | von den bisherigen Erwerbungsmodellen zu | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,137 | 3,137 | beiden Komponenten zu verändern . | Bibliotheken | erhalten das „ gleiche " | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,259 | 3,259 | , wenn sich ausreichend viele | Bibliotheken | und andere Förderer dauerhaft beteiligen | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,299 | 3,299 | Titelmenge zu klein . Manche | Bibliotheken | beklagten weiterhin , dass sie | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,435 | 3,435 | vollständig auf den Erwerbungsbudgets der | Bibliotheken | basiert . Sollten Verlage einen | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,451 | 3,451 | Verkäufe der Closed-Access-Titel außerhalb der | Bibliotheken | erzielen , werden sie darauf | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,462 | 3,462 | nicht ( ohne Gegenleistung der | Bibliotheken | ) verzichten wollen . Hinzu | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,474 | 3,474 | , dass solche Titel für | Bibliotheken | möglicherweise kaum oder gar nicht | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,490 | 3,490 | kann dazu führen , dass | Bibliotheken | mehr für eine Open-Access-Version des | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,597 | 3,597 | gestartet , um AutorInnen , | Bibliotheken | , Verlage , Händler , | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,674 | 3,674 | , der Sichtbarkeit der mitfinanzierenden | Bibliotheken | in diesem Kontext durch das | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,694 | 3,694 | Open-Access-Publikationsprozess und die Verortung der | Bibliotheken | in dem Netzwerk aus AutorInnen | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,812 | 3,812 | mit . Die Bindung der | Bibliotheksbudgets | durch Big Deals im Zeitschriftenbereich | bibliothek* |
| [20] - Stefanie Hanneken, A | 3,869 | 3,869 | Zurzeit liegt der Fokus der | Bibliotheken | und Forschungsförderer außerdem mehr auf | bibliothek* |
| [20] - Stefanie Hanneken, A | 4,119 | 4,119 | Förderer , Mindestanzahl an mitfinanzierenden | Bibliotheken | , Höhe der Book Processing | bibliothek* |
| [20] - Stefanie Hanneken, A | 4,233 | 4,233 | im Frühjahr 2019 angeschriebenen 44 | Bibliotheken | plus FID ( ohne Harvard | bibliothek* |
| [20] - Stefanie Hanneken, A | 4,812 | 4,812 | wurde von den AutorInnen , | Bibliotheken | und weiteren Verlagen mit Interesse | bibliothek* |
| [20] - Stefanie Hanneken, A | 5,787 | 5,787 | mehr als doppelt so viel | Bibliotheken | wie benötigt hat gezeigt , | bibliothek* |
| [20] - Stefanie Hanneken, A | 5,848 | 5,848 | . Die direkte Beteiligung von | Bibliotheken | und Forschungseinrichtungen sowie Hochschulen an | bibliothek* |
| [20] - Stefanie Hanneken, A | 5,906 | 5,906 | für AutorInnen , Verlage und | Bibliotheken | gleichermaßen zu nutzen . Mit | bibliothek* |
| [20] - Stefanie Hanneken, A | 5,927 | 5,927 | sowie der finanziellen Beteiligung durch | Bibliotheken | ergeben sich für alle Akteure | bibliothek* |
| [20] - Stefanie Hanneken, A | 5,969 | 5,969 | Beteiligten mit sich bringt sowie | Bibliotheken | und Verlagen in neuer partnerschaftlicher | bibliothek* |
| [20] - Stefanie Hanneken, A | 6,269 | 6,269 | : O-Bib . Das Offene | Bibliotheksjournal | 5 , 4 , 101-112 | bibliothek* |
| [20] - Stefanie Hanneken, A | 6,743 | 6,743 | der Kosten aus Sicht der | Bibliotheken | und der AutorInnen findet sich | bibliothek* |
| [20] - Stefanie Hanneken, A | 6,832 | 6,832 | ist ein Förderprogramm für wissenschaftliche | Bibliotheken | der Deutschen Forschungsgemeinschaft , das | bibliothek* |
| [21] - Claudia Frick (2020) | 4,814 | 4,814 | ihre Nutzung . Gießener Elektronische | Bibliothek | . Gießen : Universitätsbibliothek Gießen | bibliothek* |
| [23] - Franziska Altemeier, | 2,605 | 2,605 | Forschungsinformations-Manager . 107 . Deutscher | Bibliothekartag | in Berlin 2018 . https://opus4.kobv.de/opus4-bib-info/frontdoor/index/index/docId/3296 | bibliothek* |
| [25] - Jens Bemme (2020). # | 329 | 329 | 2020 auf der Startseite unserer | Bibliothek | . Erste Arbeiten an diesem | bibliothek* |
| [25] - Jens Bemme (2020). # | 745 | 745 | pflegen kann , für unsere | bibliothekarische | Arbeit mit Saxorum.de elementar . | bibliothek* |
| [25] - Jens Bemme (2020). # | 1,039 | 1,039 | - über die Bestandsentwicklung einer | Bibliothek | hinaus und aufbauen auf dem | bibliothek* |
| [25] - Jens Bemme (2020). # | 1,059 | 1,059 | für Nutzer- wie auch für | Bibliotheksmitarbeiter | * innen . Etwaige Beratungsbedarfe | bibliothek* |
| [25] - Jens Bemme (2020). # | 1,751 | 1,751 | Johann Joachim Winckelmann in der | Bibliothek | von Bünau’s in Nöthnitz , | bibliothek* |
| [25] - Jens Bemme (2020). # | 1,833 | 1,833 | Wikipedia-Artikel wurde für den Dresdner | Bibliothekar | Johann Michael Francke ( 1717-1775 | bibliothek* |
| [25] - Jens Bemme (2020). # | 2,601 | 2,601 | historischer Texte und Wikidata als | Bibliothekskatalog | dieser Quellensammlung wächst ein strukturierter | bibliothek* |
| [25] - Jens Bemme (2020). # | 2,947 | 2,947 | die 1Lib1Ref-Wikimedia-Aktionen , bei denen | Bibliotheksmitarbeiterinnen | und -mitarbeiter mit Quellenbelegen die | bibliothek* |
| [25] - Jens Bemme (2020). # | 3,764 | 3,764 | Kreise der Gelehrten in der | Bibliothek | des Schlosses Nöthnitz [ online | bibliothek* |
| [26] - Stefanie Spiegelberg | 49 | 49 | Universitätsbibliothek zu erhalten . Fluide | Bibliothek | , Aufstellungssystematik , Dynamisches Bestandsmanagement | bibliothek* |
| [26] - Stefanie Spiegelberg | 113 | 113 | management 1 Einleitung 2 Fluide | Bibliothek | - Einführung und Hintergrund 2.1 | bibliothek* |
| [26] - Stefanie Spiegelberg | 124 | 124 | Begriffsklärung 2.2 Technik der fluiden | Bibliothek | 2.2.1 RFID-Technologie 2.2.2 Smart Shelves | bibliothek* |
| [26] - Stefanie Spiegelberg | 142 | 142 | oder ASRS ? 4 Fluide | Bibliothek | in der Praxis – Voraussetzungen | bibliothek* |
| [26] - Stefanie Spiegelberg | 255 | 255 | der vorhandene Platz in der | Bibliothek | optimal genutzt werden kann . | bibliothek* |
| [26] - Stefanie Spiegelberg | 274 | 274 | Universitätsbibliotheken besitzen laut der deutschen | Bibliotheksstatistik | neben einer steigenden Anzahl digitaler | bibliothek* |
| [26] - Stefanie Spiegelberg | 311 | 311 | Das Bedürfnis nach mit der | Bibliothek | verbundenem Arbeits- und Lernraum erzeugt | bibliothek* |
| [26] - Stefanie Spiegelberg | 332 | 332 | Verknappung von Raum in der | Bibliothek | , sodass Medien und Bibliotheksnutzende | bibliothek* |
| [26] - Stefanie Spiegelberg | 337 | 337 | Bibliothek , sodass Medien und | Bibliotheksnutzende | um diesen Raum konkurrieren . | bibliothek* |
| [26] - Stefanie Spiegelberg | 455 | 455 | Bücherwelt angekommen , wie einige | Bibliotheken | im In- und Ausland beweisen | bibliothek* |
| [26] - Stefanie Spiegelberg | 612 | 612 | sich die Recherche in den | Bibliotheksbeständen | ? Wie wirkt sich ein | bibliothek* |
| [26] - Stefanie Spiegelberg | 668 | 668 | virtuell über Discovery Systeme oder | Bibliothekskataloge | statt . Dies wiederum verändert | bibliothek* |
| [26] - Stefanie Spiegelberg | 697 | 697 | die Arbeitsbereiche und -aufgaben der | Bibliotheksmitarbeitenden | . Fluid , dynamisch , | bibliothek* |
| [26] - Stefanie Spiegelberg | 723 | 723 | keinen festen Standort innerhalb der | Bibliothek | mehr besitzen . Fluide Bibliothekskonzepte | bibliothek* |
| [26] - Stefanie Spiegelberg | 728 | 728 | Bibliothek mehr besitzen . Fluide | Bibliothekskonzepte | sind in der Praxis noch | bibliothek* |
| [26] - Stefanie Spiegelberg | 907 | 907 | geliefert . Bei der fluiden | Bibliothek | - im Gegensatz zur komplett | bibliothek* |
| [26] - Stefanie Spiegelberg | 914 | 914 | im Gegensatz zur komplett automatisierten | Bibliothek | mit ASRS - ist eine | bibliothek* |
| [26] - Stefanie Spiegelberg | 937 | 937 | Abgegrenzt werden von der fluiden | Bibliothek | muss auch die hybride Bibliothek | bibliothek* |
| [26] - Stefanie Spiegelberg | 942 | 942 | Bibliothek muss auch die hybride | Bibliothek | . Im Gegensatz zur fluiden | bibliothek* |
| [26] - Stefanie Spiegelberg | 948 | 948 | . Im Gegensatz zur fluiden | Bibliothek | bietet die hybride Bibliothek physische | bibliothek* |
| [26] - Stefanie Spiegelberg | 952 | 952 | fluiden Bibliothek bietet die hybride | Bibliothek | physische und digitale Angebote , | bibliothek* |
| [26] - Stefanie Spiegelberg | 979 | 979 | . Das Charakteristische der fluiden | Bibliothek | ist jedoch gerade die Verschränkung | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,041 | 1,041 | , stehen virtueller und physischer | Bibliotheksraum | nicht mehr nur nebeneinander , | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,123 | 1,123 | für das Konzept der fluiden | Bibliothek | unverzichtbar . Da die Aufstellung | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,227 | 1,227 | . Um Prozesse in der | Bibliothek | zu automatisieren , wird meist | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,247 | 1,247 | für die Umsetzung einer fluiden | Bibliothek | Anfangsinvestitionen in die entsprechende Technik | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,363 | 1,363 | 6f . ) . Im | Bibliotheksbereich | ist für den Einsatz von | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,460 | 1,460 | Rückgabe . Da die fluide | Bibliothek | - im Gegensatz zur ASRS-gesteuerten | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,466 | 1,466 | - im Gegensatz zur ASRS-gesteuerten | Bibliothek | - auf den Trend setzt | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,518 | 1,518 | . ) . In der | Bibliothek | des Sitterwerk in St . | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,665 | 1,665 | Inventurroboter eingesetzt . An der | Bibliothek | des Max-Planck-Instituts in Luxemburg wurde | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,788 | 1,788 | Jahren sind international immer wieder | Bibliotheken | auf vollautomatisierte Speichermagazine umgestiegen , | bibliothek* |
| [26] - Stefanie Spiegelberg | 1,993 | 1,993 | innen sich frei in der | Bibliothek | bewegen und selbstständig Bücher entnehmen | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,015 | 2,015 | Automatisierungskonzept nicht , wenn eine | Bibliothek | eine e-only Strategie bei der | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,048 | 2,048 | aktuellen Literatur zum Thema fluide | Bibliothek | werden - teils auf theoretischer | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,097 | 2,097 | Bestandsaufstellung auf viele Bereiche der | Bibliothek | - organisatorisch wie auch räumlich | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,146 | 2,146 | mittels eines Testlaufs an der | Bibliothek | des MPI Luxemburg gezeigt werden | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,213 | 2,213 | einer fluiden Aufstellung können Roboter | Bibliotheken | bei der Inventur ihrer Bestände | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,240 | 2,240 | in ihrem Artikel zu RFID-basierten | Bibliothekstechnologien | aus , dass Bibliothekare neben | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,244 | 2,244 | RFID-basierten Bibliothekstechnologien aus , dass | Bibliothekare | neben ihrer Tätigkeit als Verwalter | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,272 | 2,272 | Robotern übernommen werden könnten . | Bibliothekar | * innen könnten sich dadurch | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,358 | 2,358 | nennt die Möglichkeit der fluiden | Bibliothek | , häufig entliehene Bücher gesondert | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,379 | 2,379 | könnten so zentral in der | Bibliothek | aufgestellt werden . Wenn immer | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,413 | 2,413 | mit der Zeit . Das | Bibliothekspersonal | müsse also regelmäßig ( orientiert | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,534 | 2,534 | , eingestellt werden . Moderne | Bibliotheken | sind Lernort , Besprechungsraum und | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,680 | 2,680 | findet momentan bereits in der | Bibliothek | des Sitterwerks statt und hat | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,738 | 2,738 | die Nutzer * innen der | Bibliothek | ihre Recherchen , thematischen Zusammenstellungen | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,752 | 2,752 | anderen teilen und dadurch die | Bibliothek | ein Stück weit zu ihrer | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,777 | 2,777 | , die zuvor nur dem | Bibliothekspersonal | vorbehalten war , ist daher | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,873 | 2,873 | physischer Medien im Raum der | Bibliothek | “ ( ebd . : | bibliothek* |
| [26] - Stefanie Spiegelberg | 2,931 | 2,931 | " als Teil der fluiden | Bibliothek | , sodass die " systematische | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,084 | 3,084 | Interdisziplinarität der Forschung auch im | Bibliotheksbestand | sichtbar . Durch den Einsatz | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,156 | 3,156 | ausschließlich virtuelle Orientierung in der | Bibliothek | würde also nicht vorrangig eine | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,231 | 3,231 | immer nur die durch die | Bibliothek | erstellten Zusammenhänge gefunden werden . | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,355 | 3,355 | physische Medien thematisch innerhalb der | Bibliothek | zusammenstellen , ist laut Früh | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,587 | 3,587 | flexibel und kurzfristig von den | Bibliothekar | * innen zu Themen , | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,658 | 3,658 | den Nutzer * innen die | Bibliothek | ein Stück weit zu ihrer | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,677 | 3,677 | Einfluss auf die Präsentationsformen der | Bibliothek | erlangen ( vgl . Kern | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,887 | 3,887 | Schnelldreher im vorderen Bereich der | Bibliothek | sammeln , könnte daher theoretisch | bibliothek* |
| [26] - Stefanie Spiegelberg | 3,902 | 3,902 | Wie soll in einer fluiden | Bibliothek | mit Semesterapparaten , Sammlungen und | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,068 | 4,068 | dauerhaft feste Bestandteile in der | Bibliothek | bilden . Sammlungen sind oft | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,082 | 4,082 | Reputation und das Selbstverständnis einer | Bibliothek | . Sollen sie auch weiterhin | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,171 | 4,171 | ebenfalls einen abgetrennten Bereich der | Bibliothek | nicht verlassen dürften . Es | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,209 | 4,209 | Zeitschriften stellen Einheiten in der | Bibliothek | dar , bei denen es | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,247 | 4,247 | Bei allen drei der genannten | Bibliothekselemente | - Semesterapparate , Sammlungen und | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,282 | 4,282 | als feste Elemente in der | Bibliothek | zu positionieren . Dies könnte | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,354 | 4,354 | * innen und Personal der | Bibliothek | sowie die Bibliothek als Ort | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,357 | 4,357 | Personal der Bibliothek sowie die | Bibliothek | als Ort bedeutet . Die | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,376 | 4,376 | gehalten und auch in der | Bibliothek | sind digitale Dienste bereits ein | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,437 | 4,437 | geachtet werden , dass die | Bibliothek | weiterhin als ein Ort wahrgenommen | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,483 | 4,483 | des Einsatzes von Automatisierungstechniken sollten | Bibliotheksleitungen | daher ihre Gestaltungsspielräume im Sinne | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,501 | 4,501 | in welche Richtung sie die | Bibliothek | in der digitalen Gesellschaft weiterentwickeln | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,616 | 4,616 | 22 ) . Auch in | Bibliothekskreisen | heißt es oft , dass | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,629 | 4,629 | , niedrigqualifizierte Tätigkeiten in der | Bibliothek | verschwinden werden , dafür aber | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,686 | 4,686 | als durch die Automatisierung der | Bibliothek | wegfallen , bleibt spekulativ . | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,735 | 4,735 | höher qualifizierten Tätigkeiten in der | Bibliothek | verringern . Schon jetzt wählt | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,766 | 4,766 | die anzuschaffende Literatur für die | Bibliothek | aus , sondern die Anzahl | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,900 | 4,900 | und Entscheidungen zukünftig in der | Bibliothek | spielen sollen . Obwohl insbesondere | bibliothek* |
| [26] - Stefanie Spiegelberg | 4,907 | 4,907 | sollen . Obwohl insbesondere große | Bibliotheken | bereits jetzt schon einen hohen | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,120 | 5,120 | sogar eine problematische Nutzung der | Bibliothek | dar . Systematisch im Regal | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,134 | 5,134 | immer nur einen durch die | Bibliothek | ausgewählten Ausschnitt der passenden Literatur | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,230 | 5,230 | gedruckten in die ‚ elektronische | Bibliothekswelt | ’ zu wechseln . Durch | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,261 | 5,261 | gemacht werden , die es | Bibliotheksnutzer | * innen ermöglichen , sich | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,322 | 5,322 | . Während früher von den | Bibliotheksnutzer | * innen erwartet wurde , | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,342 | 5,342 | einzuarbeiten , orientieren sich heutige | Bibliotheks-Discovery | Systeme an den Recherchegewohnheiten der | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,372 | 5,372 | Erfahrungen beim Recherchieren in der | Bibliothek | machen und so die Vorteile | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,379 | 5,379 | und so die Vorteile der | Bibliothek | selbst entdecken . Da liegt | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,433 | 5,433 | nicht mehr nur als ’ | bibliothekarische | Geheimsprache ’ genutzt werden , | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,504 | 5,504 | für die Nutzung in der | Bibliothek | denkbar : Virtuelle Systematik als | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,925 | 5,925 | ein umso wichtigerer Teil der | Bibliotheksaufgaben | sein . In der vorliegenden | bibliothek* |
| [26] - Stefanie Spiegelberg | 5,977 | 5,977 | es sich bei einer fluiden | Bibliothek | handelt . Diese ist dadurch | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,015 | 6,015 | der physische und der digitale | Bibliotheksraum | , da es keine Trennung | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,033 | 6,033 | . Mittels publizierter Erfahrungen anderer | Bibliotheken | konnte eine Vielzahl verschiedener Auswirkungen | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,092 | 6,092 | , wie dies bei einer | Bibliothek | nach dem Vorbild eines ASRS-Konzeptes | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,127 | 6,127 | an der Ordnung innerhalb der | Bibliothek | beteiligen und ihre eigenen Ordnungen | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,147 | 6,147 | im vorderen Bereich einer fluiden | Bibliothek | birgt jedoch die Gefahr , | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,188 | 6,188 | und dadurch auch in der | Bibliothek | sogenannte Filter-Blasen im physischen Raum | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,216 | 6,216 | die Diskussionen um eine fluide | Bibliothek | einfließen und eventuelle Seiteneffekte müssen | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,238 | 6,238 | digitalen Medien bietet die fluide | Bibliothek | den Vorteil , dass beide | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,316 | 6,316 | - nicht nur für fluide | Bibliotheken | - ein enormes Potential für | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,336 | 6,336 | ermöglichen eine interdisziplinäre Darstellung der | Bibliotheksbestände | und knüpfen an die Erfahrungswelten | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,444 | 6,444 | Bezüglich der Arbeitsgänge in der | Bibliothek | konnte herausgestellt werden , dass | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,476 | 6,476 | aufgefunden werden können . Den | Bibliotheksmitarbeiter | * innen bliebe durch diese | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,542 | 6,542 | den bisherigen Vorstellungen von einer | Bibliothek | . Durch den Einsatz von | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,566 | 6,566 | . Was dies für die | Bibliothek | als Ort bedeutet , sollte | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,579 | 6,579 | Planung von neuen Nutzungskonzepten und | Bibliotheksstrategien | miteinbezogen werden . Bibliothekar * | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,583 | 6,583 | und Bibliotheksstrategien miteinbezogen werden . | Bibliothekar | * innen müssten sich möglicherweise | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,695 | 6,695 | . Es wäre interessant , | Bibliotheken | , die bereits mit automatisierten | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,738 | 6,738 | sich dieses Angebot auf die | Bibliotheksnutzung | auswirkt . Es wäre interessant | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,776 | 6,776 | wie sich die Arbeitswelt des | Bibliothekspersonals | in komplett oder teilweise automatisierten | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,782 | 6,782 | in komplett oder teilweise automatisierten | Bibliotheken | verändert . Bichler , Klaus | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,869 | 6,869 | Wissenschaftliche Dienst in der Digitalen | Bibliothek | - Was kommt nach dem | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,905 | 6,905 | ( 2017 ) : RFID-basierte | Bibliothekstechnologie | – ein Schritt weiter . | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,945 | 6,945 | , helfe dir , dem | Bibliothekar | : Die Bibliothek des MPI | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,948 | 6,948 | , dem Bibliothekar : Die | Bibliothek | des MPI Luxemburg als Wegbereiter | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,984 | 6,984 | : Das Konzept der fluiden | Bibliothek | an der USB Köln . | bibliothek* |
| [26] - Stefanie Spiegelberg | 6,992 | 6,992 | USB Köln . In : | Bibliotheksdienst | . Bd . 52 , | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,025 | 7,025 | Auf dem Weg zur Fluiden | Bibliothek | : Formierung und Konvergenz in | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,082 | 7,082 | 2018 ) : Roboter in | Bibliotheken | und die flexible Ordnung von | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,113 | 7,113 | ( 2013 ) : Die | Bibliothek | und ihre physische Sammlung sind | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,203 | 7,203 | von der Industrie in die | Bibliothek | . Präsentation auf der 14 | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,339 | 7,339 | Hg . : RFID für | Bibliotheken | . Berlin & Heidelberg : | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,618 | 7,618 | stefanie.spiegelberg@tu-dortmund.de 1 DBS – Deutsche | Bibliotheksstatistik | : https://www.bibliotheksstatistik.de/ 2 Payne ( | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,639 | 7,639 | Darüber hinaus beispielshafte ASRS nutzende | Bibliotheken | : Bibliothek der University of | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,641 | 7,641 | beispielshafte ASRS nutzende Bibliotheken : | Bibliothek | der University of British Columbia | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,657 | 7,657 | / Willis 2014 ) , | Bibliothek | der University of Technology Sidney | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,686 | 7,686 | ) . 3 z.B . | Bibliothek | des Sitterwerk in St . | bibliothek* |
| [26] - Stefanie Spiegelberg | 7,705 | 7,705 | 2018 ) bzw . fluide | Bibliothek | im Bau : INFO.HUB des | bibliothek* |
| [27] - Sophie Schneider (20 | 54 | 54 | Bestandsaufnahme über die Zusammensetzung der | bibliotheks- | und informations-wissenschaftlichen Community auf Twitter | bibliothek* |
| [27] - Sophie Schneider (20 | 98 | 98 | einzelne informationswissenschaftliche Themenfelder untersucht . | Bibliotheks- | und Informationswissenschaft , Netzwerkanalyse , | bibliothek* |
| [27] - Sophie Schneider (20 | 2,115 | 2,115 | . Vergleichbare Analysen zu der | bibliotheks- | und / oder informationswissenschaftlichen Community | bibliothek* |
| [27] - Sophie Schneider (20 | 2,133 | 2,133 | Literatur thematisiert dabei entweder nur | Bibliotheken | auf Twitter ( siehe z.B | bibliothek* |
| [27] - Sophie Schneider (20 | 2,158 | 2,158 | nicht explizit WissenschaftlerInnen aus dem | bibliotheks- | / informationswissenschaftlichen Forschungsfeld , oder | bibliothek* |
| [27] - Sophie Schneider (20 | 3,402 | 3,402 | der im deutschen Hochschulraum agierenden | bibliotheks- | und informationswissenschaftlichen Institutionen berücksichtigt . | bibliothek* |
| [27] - Sophie Schneider (20 | 3,421 | 3,421 | die Einrichtungen neben informationswissenschaftlichen auch | bibliothekswissenschaftliche | bzw . gemischte Studiengänge anbieten | bibliothek* |
| [27] - Sophie Schneider (20 | 3,510 | 3,510 | von Hochschulen mit Bachelor-Studiengängen im | Bibliothekswesen | wurden für die Untersuchung herangezogen | bibliothek* |
| [27] - Sophie Schneider (20 | 3,575 | 3,575 | 2018 ) - Institut für | Bibliotheks- | und Informationswissenschaft der HU Berlin | bibliothek* |
| [27] - Sophie Schneider (20 | 4,342 | 4,342 | institutioneller Art ( Ausbildungseinrichtung , | Bibliothek | , Forschungseinrichtung , Museum , | bibliothek* |
| [27] - Sophie Schneider (20 | 4,392 | 4,392 | Teil der auf Twitter stattfindenden | bibliothekarischen | Chat-Veranstaltung . Die vier wissenschaftlichen | bibliothek* |
| [27] - Sophie Schneider (20 | 4,419 | 4,419 | Drei dieser vier Zeitschriften mit | bibliotheks- | und / oder informationswissenschaftlichem Fokus | bibliothek* |
| [27] - Sophie Schneider (20 | 4,722 | 4,722 | die Themenbereiche Open Science , | Bibliotheks- | & Informationswissenschaft sowie Bildung & | bibliothek* |
| [27] - Sophie Schneider (20 | 4,741 | 4,741 | Diese Kategorien scheinen für die | Bibliotheks- | und Informationswissenschaften auf Twitter bedeutend | bibliothek* |
| [27] - Sophie Schneider (20 | 4,777 | 4,777 | zugeordnet worden zusammen mit anderen | bibliotheks- | und informationswissenschaftlichen Themenbereichen wie Forschungsdaten | bibliothek* |
| [27] - Sophie Schneider (20 | 4,852 | 4,852 | , Data Science und Digitale | Bibliothek | . Zusammenfassend lässt sich daraus | bibliothek* |
| [27] - Sophie Schneider (20 | 4,887 | 4,887 | zudem die Diversität der ( | Bibliotheks- | und ) Informationswissenschaften wieder und | bibliothek* |
| [27] - Sophie Schneider (20 | 5,084 | 5,084 | Personen , die sich für | Bibliotheks- | und Informationswissenschaft interessieren unter anderem | bibliothek* |
| [27] - Sophie Schneider (20 | 5,926 | 5,926 | unterrepräsentiert sind . Neben den | Bibliotheks- | und Informationswissenschaften waren die Bereiche | bibliothek* |
| [27] - Sophie Schneider (20 | 5,978 | 5,978 | Open Access . Neben den | bibliotheks- | und informationswissenschaftlichen Themengebieten konnten vor | bibliothek* |
| [27] - Sophie Schneider (20 | 6,029 | 6,029 | beschäftigt . „ Traditionelle " | bibliothekarische | Themen wie beispielsweise die Katalogisierung | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 349 | 349 | 2020 zumindest einige der zentralen | bibliothekarischen | Basisdienste aufrechtzuerhalten , der diesen | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 405 | 405 | Vorbild einiger besonders agil reagierender | Bibliotheken | dazu bei , die Corona-Krise | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 497 | 497 | Öffnung der vor Ort geschlossenen | Bibliothek | in ihrem Effekt auf Organisation | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 521 | 521 | Bereits mit der Schließung der | Bibliothek | für den Publikumsverkehr wurde der | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 580 | 580 | für Kundinnen und Kunden der | Bibliothek | , die es gewohnt waren | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 602 | 602 | recht kurzfristig umzusetzenden Schließung der | Bibliothek | ergaben sich für viele völlig | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 760 | 760 | es , die Telefonauskunft der | Bibliothek | wieder zu aktivieren , diesmal | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 806 | 806 | von den Themen vor der | Bibliotheksschließung | . Es ist nur eine | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 960 | 960 | weiterhin den Zugriff zu ihren | Bibliothekskonten | und den damit verbundenen Berechtigungen | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 1,192 | 1,192 | die Bestände , die eine | Bibliothek | zu bieten hat . Mit | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 1,651 | 1,651 | sich alle , wenn die | Bibliothek | auch wieder in die nichtvirtuelle | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 1,741 | 1,741 | SBB gehört zu den wenigen | Bibliotheken | , die sich immer noch | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 1,856 | 1,856 | Subito – wurden in der | Bibliothek | quasi über Nacht eingestellt und | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 1,872 | 1,872 | Stündlich trafen Meldungen von anderen | Bibliotheken | ein , denen es ähnlich | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 1,895 | 1,895 | Erliegen kam . Einige wenige | Bibliotheken | hielten zumindest ihre Aktivitäten im | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 2,213 | 2,213 | Auf der Ebene des Gemeinsamen | Bibliotheksverbunds | ( GBV ) – ihm | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 2,302 | 2,302 | sowie in anderen Gremien und | Bibliotheksverbünden | sehr schnell darüber diskutiert , | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 2,352 | 2,352 | elektronisch übermittelte Aufsatzkopien von anderen | Bibliotheken | nämlich ausschließlich als physischer Ausdruck | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 2,408 | 2,408 | Akteure aus dem Kultur- und | Bibliotheksbereich | sind daher mit der Absicht | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 2,557 | 2,557 | Beiträge aus allen Bereichen der | Bibliothek | . Mit der einfachen Bedienung | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 2,688 | 2,688 | zuhause sprechen , ist das | Bibliotheksblog | in seinem Schaufenster , dem | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 2,752 | 2,752 | Hinblick auf die Online-Kommunikation der | Bibliothek | sogar noch etwas pointierter formuliert | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 2,952 | 2,952 | nach der Corona-bedingten Schließung der | Bibliothek | verstärkt und halten nun den | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 3,135 | 3,135 | für anderes braucht man einen | Bibliotheksausweis | , der aber während der | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 3,207 | 3,207 | für die Ausstellung , die | Bibliothek | wurde geschlossen . Monatelange Vorbereitungen | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 3,352 | 3,352 | wenigen Tagen , die die | Bibliothek | nach der Schließung für die | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 3,499 | 3,499 | 2017 wurde im Blognetzwerk der | Bibliothek | ein für Ausstellungen reservierter Bereich | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 3,635 | 3,635 | Ausnahmesituation können viele Services der | Bibliothek | nicht wie gewohnt angeboten werden | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 4,183 | 4,183 | recht freien akademischen Alltag mit | Bibliotheksbesuchen | zu strukturieren . Über die | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 4,215 | 4,215 | Kontrolle zu nutzen , die | Bibliothekslesesäle | bedeuten können . Um das | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 4,271 | 4,271 | nicht nur Nutzende mit ihrer | Bibliothek | kommunizieren , sondern auch miteinander | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 4,365 | 4,365 | als vor Ort in der | Bibliothek | , scheint der Community-Effekt letztendlich | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 4,419 | 4,419 | größten und leistungsfähigsten IT-Abteilungen deutscher | Bibliotheken | . Dennoch bedeutet die aktuelle | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 5,059 | 5,059 | senkrecht . Weder Universitäten noch | Bibliotheken | können dieser quasi unmittelbar von | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 5,210 | 5,210 | der Fortbildungs-Events auch aus dem | bibliotheksfernen | Homeoffice weitergehen kann . Parallel | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 5,228 | 5,228 | außen , also für unsere | Bibliotheksnutzer | * innen . Hierzu ist | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 5,262 | 5,262 | der Phase der physisch fühlbaren | Bibliothekslosigkeit | noch unverzichtbarer ist als in | bibliothek* |
| [28] - Heinz-Jürgen Bove, J | 5,363 | 5,363 | , Struktur und Organisationskultur einer | Bibliothek | in zwei Häusern kaum hoch | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 345 | 345 | 2020 zumindest einige der zentralen | bibliothekarischen | Basisdienste aufrechtzuerhalten , der diesen | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 401 | 401 | Vorbild einiger besonders agil reagierender | Bibliotheken | dazu bei , die Corona-Krise | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 493 | 493 | Öffnung der vor Ort geschlossenen | Bibliothek | in ihrem Effekt auf Organisation | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 517 | 517 | Bereits mit der Schließung der | Bibliothek | für den Publikumsverkehr wurde der | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 576 | 576 | für Kundinnen und Kunden der | Bibliothek | , die es gewohnt waren | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 598 | 598 | recht kurzfristig umzusetzenden Schließung der | Bibliothek | ergaben sich für viele völlig | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 756 | 756 | es , die Telefonauskunft der | Bibliothek | wieder zu aktivieren , diesmal | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 802 | 802 | von den Themen vor der | Bibliotheksschließung | . Es ist nur eine | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 956 | 956 | weiterhin den Zugriff zu ihren | Bibliothekskonten | und den damit verbundenen Berechtigungen | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 1,188 | 1,188 | die Bestände , die eine | Bibliothek | zu bieten hat . Mit | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 1,615 | 1,615 | sich alle , wenn die | Bibliothek | auch wieder in die nichtvirtuelle | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 1,705 | 1,705 | SBB gehört zu den wenigen | Bibliotheken | , die sich immer noch | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 1,820 | 1,820 | Subito – wurden in der | Bibliothek | quasi über Nacht eingestellt und | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 1,836 | 1,836 | Stündlich trafen Meldungen von anderen | Bibliotheken | ein , denen es ähnlich | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 1,859 | 1,859 | Erliegen kam . Einige wenige | Bibliotheken | hielten zumindest ihre Aktivitäten im | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 2,177 | 2,177 | Auf der Ebene des Gemeinsamen | Bibliotheksverbunds | ( GBV ) – ihm | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 2,266 | 2,266 | sowie in anderen Gremien und | Bibliotheksverbünden | sehr schnell darüber diskutiert , | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 2,316 | 2,316 | elektronisch übermittelte Aufsatzkopien von anderen | Bibliotheken | nämlich ausschließlich als physischer Ausdruck | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 2,372 | 2,372 | Akteure aus dem Kultur- und | Bibliotheksbereich | sind daher mit der Absicht | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 2,528 | 2,528 | Beiträge aus allen Bereichen der | Bibliothek | . Mit der einfachen Bedienung | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 2,653 | 2,653 | zuhause sprechen , ist das | Bibliotheksblog | in seinem Schaufenster , dem | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 2,717 | 2,717 | Hinblick auf die Online-Kommunikation der | Bibliothek | sogar noch etwas pointierter formuliert | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 2,917 | 2,917 | nach der Corona-bedingten Schließung der | Bibliothek | verstärkt und halten nun den | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 3,100 | 3,100 | für anderes braucht man einen | Bibliotheksausweis | , der aber während der | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 3,172 | 3,172 | für die Ausstellung , die | Bibliothek | wurde geschlossen . Monatelange Vorbereitungen | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 3,317 | 3,317 | wenigen Tagen , die die | Bibliothek | nach der Schließung für die | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 3,464 | 3,464 | 2017 wurde im Blognetzwerk der | Bibliothek | ein für Ausstellungen reservierter Bereich | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 3,600 | 3,600 | Ausnahmesituation können viele Services der | Bibliothek | nicht wie gewohnt angeboten werden | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 4,148 | 4,148 | recht freien akademischen Alltag mit | Bibliotheksbesuchen | zu strukturieren . Über die | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 4,180 | 4,180 | Kontrolle zu nutzen , die | Bibliothekslesesäle | bedeuten können . Um das | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 4,236 | 4,236 | nicht nur Nutzende mit ihrer | Bibliothek | kommunizieren , sondern auch miteinander | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 4,330 | 4,330 | als vor Ort in der | Bibliothek | , scheint der Community-Effekt letztendlich | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 4,384 | 4,384 | größten und leistungsfähigsten IT-Abteilungen deutscher | Bibliotheken | . Dennoch bedeutet die aktuelle | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 5,024 | 5,024 | senkrecht . Weder Universitäten noch | Bibliotheken | können dieser quasi unmittelbar von | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 5,175 | 5,175 | der Fortbildungs-Events auch aus dem | bibliotheksfernen | Homeoffice weitergehen kann . Parallel | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 5,193 | 5,193 | außen , also für unsere | Bibliotheksnutzer | * innen . Hierzu ist | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 5,227 | 5,227 | der Phase der physisch fühlbaren | Bibliothekslosigkeit | noch unverzichtbarer ist als in | bibliothek* |
| [29] - Heinz-Jürgen Bove, J | 5,328 | 5,328 | , Struktur und Organisationskultur einer | Bibliothek | in zwei Häusern kaum hoch | bibliothek* |
| [30] - Barbara Knorn, Erich | 87 | 87 | einem reduzierten Basisbetrieb . Die | Bibliothek | setzt die Verordnung des Landes | bibliothek* |
| [30] - Barbara Knorn, Erich | 151 | 151 | . Das digitale Angebot der | Bibliothek | steht ohne Einschränkungen zur Verfügung | bibliothek* |
| [30] - Barbara Knorn, Erich | 317 | 317 | erschienen sind . Scan-Services der | Bibliothek | : Scan-Service für digitale Semesterapparate | bibliothek* |
| [30] - Barbara Knorn, Erich | 330 | 330 | ausgewählten Dokumente werden von der | Bibliothek | gescannt und zum Download für | bibliothek* |
| [30] - Barbara Knorn, Erich | 378 | 378 | Büchern aus dem Bestand der | Bibliothek | . E-First-Strategie bei den Anschaffungswünschen | bibliothek* |
| [30] - Barbara Knorn, Erich | 411 | 411 | den bereits festgelegten Lizenzbedingungen der | Bibliothek | , dann wird das Buch | bibliothek* |
| [30] - Barbara Knorn, Erich | 435 | 435 | und gedruckte Literatur aus der | Bibliothek | angewiesen . Die Universitätsbibliothek ist | bibliothek* |
| [30] - Barbara Knorn, Erich | 474 | 474 | . Die in Fachbibliotheken gegliederte | Bibliothek | ist im Universitätshauptgebäude und im | bibliothek* |
| [30] - Barbara Knorn, Erich | 518 | 518 | , da eine Komplettschließung des | Bibliotheksbereichs | – wie in anderen Häusern | bibliothek* |
| [30] - Barbara Knorn, Erich | 552 | 552 | auch wegen der Weitläufigkeit der | Bibliotheksfläche | konnte ein Großteil der Services | bibliothek* |
| [30] - Barbara Knorn, Erich | 574 | 574 | Eingänge sind aktuell nur drei | Bibliothekseingänge | geöffnet ; sie ermöglichen den | bibliothek* |
| [30] - Barbara Knorn, Erich | 585 | 585 | Zugang zu allen Teilbereichen der | Bibliothek | . Die Öffnungszeiten wurden auf | bibliothek* |
| [30] - Barbara Knorn, Erich | 602 | 602 | und an Feiertagen bleibt die | Bibliothek | geschlossen . Zutritt zur Bibliothek | bibliothek* |
| [30] - Barbara Knorn, Erich | 607 | 607 | Bibliothek geschlossen . Zutritt zur | Bibliothek | erhalten nur Wissenschaftler * innen | bibliothek* |
| [30] - Barbara Knorn, Erich | 624 | 624 | der Universität . Wer die | Bibliothek | betreten möchte , muss sich | bibliothek* |
| [30] - Barbara Knorn, Erich | 639 | 639 | . Der Aufenthalt in der | Bibliothek | ist nur zum Heraussuchen von | bibliothek* |
| [30] - Barbara Knorn, Erich | 713 | 713 | Nutzer * innen an das | Bibliothekspersonal | an drei Ausleihterminals wenden . | bibliothek* |
| [30] - Barbara Knorn, Erich | 724 | 724 | Bei den Einlasskontrollen achtet das | Bibliothekspersonal | auf die Einhaltung des nötigen | bibliothek* |
| [30] - Barbara Knorn, Erich | 861 | 861 | werden . Aktuell erarbeitet die | Bibliothek | neue digitale Schulungsformate . Das | bibliothek* |
| [30] - Barbara Knorn, Erich | 883 | 883 | Forschungsdaten . Die Publikationsdienste der | Bibliothek | leisten einen wichtigen Beitrag für | bibliothek* |
| [30] - Barbara Knorn, Erich | 899 | 899 | Veröffentlichung ihrer Open-Access-Publikationen . Viele | Bibliotheksmitarbeiter | * innen erbringen diese Arbeit | bibliothek* |
| [30] - Barbara Knorn, Erich | 911 | 911 | Ort in den Abteilungen der | Bibliothek | , viele auf gesicherten Kommunikationswegen | bibliothek* |
| [30] - Barbara Knorn, Erich | 1,077 | 1,077 | mitgetragen wird , hat die | Bibliothek | bereits viele positive Rückmeldungen von | bibliothek* |
| [30] - Barbara Knorn, Erich | 1,170 | 1,170 | auch in den Waschräumen der | Bibliothek | ( Foto : Erich Grevelding | bibliothek* |
| [31] - Karsten Schuldt (202 | 9 | 9 | Karsten SCHULDT Offenbar waren Öffentliche | Bibliotheken | im DACH-Raum nicht auf eine | bibliothek* |
| [31] - Karsten Schuldt (202 | 45 | 45 | auf solche Ereignisse zum professionellen | bibliothekarischen | Handeln gehören . Zumeist auf | bibliothek* |
| [31] - Karsten Schuldt (202 | 71 | 71 | , die auch für Öffentliche | Bibliotheken | relevant ist . Dieser Artikel | bibliothek* |
| [31] - Karsten Schuldt (202 | 95 | 95 | Krisen , Katastrophenplan , Öffentliche | Bibliothek | , Literaturbericht Apparently public libraries | bibliothek* |
| [31] - Karsten Schuldt (202 | 236 | 236 | beschäftigen , wie sich Öffentliche | Bibliotheken | auf Krisen ähnlichen Ausmasses wie | bibliothek* |
| [31] - Karsten Schuldt (202 | 329 | 329 | würden , schienen die Öffentlichen | Bibliotheken | davon einigermassen überrascht . Dabei | bibliothek* |
| [31] - Karsten Schuldt (202 | 372 | 372 | wenig Schwierigkeiten damit hatten , | Bibliotheken | in ein System von relevanten | bibliothek* |
| [31] - Karsten Schuldt (202 | 631 | 631 | grösstmöglicher Kontaktvermeidung bestehen würde . | Bibliotheken | hätten auf diesen Fall also | bibliothek* |
| [31] - Karsten Schuldt (202 | 817 | 817 | . Die anfänglichen Reaktionen Öffentlicher | Bibliotheken | in den ersten Wochen der | bibliothek* |
| [31] - Karsten Schuldt (202 | 877 | 877 | gelten . Es gibt im | Bibliotheks- | , Archiv- und Museumsbereich heute | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,032 | 1,032 | digitale Bestände und IT-Infrastruktur von | Bibliotheken | gelten . ( Mallery 2015 | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,054 | 1,054 | die Krisen- und Nach-Krisenplanung von | Bibliotheken | über die Sicherung von Beständen | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,085 | 1,085 | wird auch auf Funktionen Öffentlicher | Bibliotheken | bezogen . Auch die Arbeit | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,102 | 1,102 | without borders , die mit | bibliothekarischen | Diensten versucht , bei Krisen | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,132 | 1,132 | darauf geben , was für | Bibliotheken | überhaupt möglich und planbar wäre | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,181 | 1,181 | Planungen der Arbeit von Öffentlichen | Bibliotheken | in Bezug auf zukünftige Katastrophen | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,245 | 1,245 | . Aber nur wenige Öffentliche | Bibliotheken | haben einen solchen schützenswerten Bestand | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,432 | 1,432 | , welche auch für Öffentliche | Bibliotheken | relevant sein können . Dieses | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,541 | 1,541 | zu Katastrophen und Katastrophenplanung in | Bibliotheken | , auch spezifisch für oder | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,549 | 1,549 | spezifisch für oder über Öffentliche | Bibliotheken | . Den Grossteil dieser Texte | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,591 | 1,591 | dazu dienten , Erfahrungen von | Bibliotheken | , welche Katastrophen erlebt hatten | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,613 | 1,613 | Toolkits oder andere Anleitungen für | Bibliotheken | erarbeitet , um sie beim | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,666 | 1,666 | Versicherung , dass auch andere | Bibliotheken | von Katastrophen betroffen waren und | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,680 | 1,680 | konnten ; Hinweise , dass | Bibliotheken | in Katastrophen eine wichtige Rolle | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,709 | 1,709 | sich auch die Literatur zu | Bibliotheken | , die sich auf Katastrophen-Planungen | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,722 | 1,722 | Bestandschutz bezieht , auf Wissenschaftliche | Bibliotheken | konzentriert , existiert doch einiges | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,734 | 1,734 | Wissen über Katastrophen und Öffentliche | Bibliotheken | . Bishop & Veil ( | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,744 | 1,744 | ( 2013 ) befragten Öffentliche | Bibliotheken | in den USA , deren | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,772 | 1,772 | fassten zusammen , dass die | Bibliotheken | in allen Gemeinden nach der | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,810 | 1,810 | Gleichwohl hatten nur einige der | Bibliotheken | vorgängig Katastrophenpläne . Diese wiederum | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,848 | 1,848 | Krise geschehen und wie die | Bibliotheken | in der Zeit nach der | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,865 | 1,865 | Nachhinein gingen dann alle befragten | Bibliotheken | daran , Katastrophenpläne zu erstellen | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,889 | 1,889 | ihren Interviews mit den betroffenen | Bibliotheken | kaum über Koordination und Kommunikation | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,924 | 1,924 | welcher zu den Aktivitäten der | Bibliothek | sowohl während als auch nach | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,942 | 1,942 | passt , dass viele befragte | Bibliothekar | * innen angaben , den | bibliothek* |
| [31] - Karsten Schuldt (202 | 1,990 | 1,990 | den Eindruck , dass die | Bibliothek | selbst in der Krise einen | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,017 | 2,017 | ihrer Studie dazu , wie | Bibliotheken | während der Hurrikane in den | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,076 | 2,076 | : 208-209 ) . Öffentliche | Bibliotheken | hätten in den von einem | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,189 | 2,189 | Training , auch für Öffentliche | Bibliotheken | notwendig ist , dass ( | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,199 | 2,199 | ( 2 ) die kleineren | Bibliothek | von einer grösseren Einrichtung – | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,244 | 2,244 | ( 3 ) dass sich | Bibliotheken | schon vor Katastrophen klar werden | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,312 | 2,312 | explizit mit Katastrophen und kleinen | Bibliotheken | beschäftigen , betonen die Notwendigkeit | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,360 | 2,360 | von State Library und Öffentlichen | Bibliotheken | in Louisiana nach Naturkatastrophen schreibt | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,378 | 2,378 | Krisen auch die Prioritäten von | Bibliotheken | verändern müssten : „ Haben | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,417 | 2,417 | Notfall liegt der Nutzen von | Bibliotheken | darin , Nutzende mit ihren | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,508 | 2,508 | übernehmen , welche konkreten Angebote | Bibliotheken | tatsächlichen machen sollen und welche | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,529 | 2,529 | , in der Interviews mit | Bibliothekar | * innen aus Bibliotheken mit | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,533 | 2,533 | mit Bibliothekar * innen aus | Bibliotheken | mit Katastrophenerfahrung durchgeführt wurden , | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,558 | 2,558 | die unterschiedlichen Rollen , welche | Bibliotheken | in den Krisen übernahmen , | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,575 | 2,575 | . Institutionelle Unterstützung : Die | Bibliothek | wurden als Ort genutzt , | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,616 | 2,616 | Verbreitung von Informationen : Die | Bibliothek | agierte als Einrichtung , die | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,637 | 2,637 | verbreitete . Interne Partnerorganisation : | Bibliotheken | – eher Wissenschaftliche – übernahmen | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,682 | 2,682 | der Community : Insbesondere Öffentliche | Bibliotheken | dienten als Ort , an | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,719 | 2,719 | Partnereinrichtung für staatliche Einrichtungen : | Bibliotheken | organisierten Berichte und Seminare über | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,747 | 2,747 | : In dieser Rolle lehrten | Bibliotheken | Einsatzkräften den richtigen Umgang mit | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,771 | 2,771 | der „ Informations-Community ‟ : | Bibliotheken | unterstützten andere Einrichtungen mit Buchspenden | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,779 | 2,779 | Einrichtungen mit Buchspenden , unterstützten | Bibliotheken | , die mehr von den | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,808 | 2,808 | Arbeiten für Personal aus anderen | Bibliotheken | und ähnlichen Einrichtungen . ( | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,858 | 2,858 | der Studie Geschichten aus verschiedene | Bibliotheken | als Basis dienen – auf | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,865 | 2,865 | Basis dienen – auf Öffentliche | Bibliotheken | übertragen . Weitere Rollen sind | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,886 | 2,886 | ( 2011 ) , dass | Bibliotheken | sich in Krisensituationen als Orte | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,909 | 2,909 | Beispiel des Handels von Öffentlichen | Bibliotheken | während der H1N1-Pandemie ( Schweinegrippe | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,939 | 2,939 | also eine Frage , was | Bibliotheken | könnten und was sie dann | bibliothek* |
| [31] - Karsten Schuldt (202 | 2,979 | 2,979 | , und dem Verhalten von | Bibliotheken | in diesen , zeigt ein | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,190 | 3,190 | mit Katastrophenplanungen auch in Öffentlichen | Bibliotheken | dargestellt zu haben . Viele | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,248 | 3,248 | schlug sich auch in der | bibliothekarischen | Literatur wieder , in welcher | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,335 | 3,335 | Ereignis , welches auch für | Bibliotheken | einen Anstoss hätte geben können | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,369 | 3,369 | beachtete Ereignisse , aber gleichwohl | Bibliotheken | betreffen – werden immer wieder | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,388 | 3,388 | ) , Überschwemmung in der | Bibliothek | durch gebrochene Leitungen ( Beales | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,403 | 3,403 | schon wieder fast klassisch für | Bibliotheken | – Schimmelbefall ( Kraft 2006 | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,456 | 3,456 | unterscheiden , scheinen sie für | Bibliotheken | strukturell ähnlich zu sein und | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,508 | 3,508 | für Katastrophen eine Aufgabe für | Bibliotheken | sein sollte , dass diese | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,668 | 3,668 | geht dabei explizit auf Öffentliche | Bibliotheken | ein . Wellheiser et al | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,694 | 3,694 | Fokus auf Herausforderungen , die | Bibliotheken | , Archive und andere Informationseinrichtungen | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,944 | 3,944 | es explizit verschiedene Rollen von | Bibliotheken | in Krisensituationen thematisiert . Weiter | bibliothek* |
| [31] - Karsten Schuldt (202 | 3,985 | 3,985 | von Katastrophen und die verschiedenen | Bibliothekstypen | hinweg , ein gemeinsamer Pool | bibliothek* |
| [31] - Karsten Schuldt (202 | 4,042 | 4,042 | egal , wie wertvoll die | Bibliotheksbestände | sind . ‟ ( Bolger | bibliothek* |
| [31] - Karsten Schuldt (202 | 4,103 | 4,103 | unterstützen , um in der | Bibliothek | oder auch der Gemeinde zu | bibliothek* |
| [31] - Karsten Schuldt (202 | 4,155 | 4,155 | mit welchem die Arbeit der | Bibliothek | wieder aufgebaut und aufrecht erhalten | bibliothek* |
| [31] - Karsten Schuldt (202 | 4,315 | 4,315 | : 472 ) , dass | Bibliotheken | mit Literatur zur emotionalen Bewältigung | bibliothek* |
| [31] - Karsten Schuldt (202 | 4,479 | 4,479 | auch das Support-Personal der jeweiligen | Bibliothek | , dass vielleicht nur temporär | bibliothek* |
| [31] - Karsten Schuldt (202 | 4,489 | 4,489 | temporär oder indirekt in der | Bibliothek | arbeitet . ( Beales 2003 | bibliothek* |
| [31] - Karsten Schuldt (202 | 4,539 | 4,539 | Freiwilligen geben wird , der | Bibliothek | zu helfen . Diese Hilfe | bibliothek* |
| [31] - Karsten Schuldt (202 | 4,649 | 4,649 | für Katastrophen aller Art in | Bibliotheken | notwendig ist . Die Aussagen | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,075 | 5,075 | immer wieder betont , dass | Bibliotheken | sich in lokale Netzwerke , | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,096 | 5,096 | meisten Katastrophen treffen nicht nur | Bibliotheken | selber , sondern ganze Gemeinden | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,113 | 5,113 | Personen und Institutionen – auch | Bibliotheken | selber – nicht unbedingt , | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,121 | 5,121 | nicht unbedingt , welche Rolle | Bibliotheken | in Katastrophen spielen könnten oder | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,132 | 5,132 | haben Probleme damit , wenn | Bibliotheken | in Krisen ungewöhnliche Rollen übernehmen | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,153 | 5,153 | auch im konkreten Krisenfall müssten | Bibliotheken | deshalb aktiv Kontakte zu lokalen | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,184 | 5,184 | hervorgehoben , dass Zusammenarbeit zwischen | Bibliotheken | notwendig wäre . Sich gegenseitig | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,349 | 5,349 | das sich die Arbeit einer | Bibliothek | ausrichten könnte . Alajmi ( | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,439 | 5,439 | wird , wozu eine funktionierende | Bibliothek | zählen kann . ( Alajmi | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,520 | 5,520 | den expliziten Hinweis , dass | Bibliotheken | explizit nach Hilfe fragen sollten | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,655 | 5,655 | wer Zugang zu Räumen der | Bibliothek | erhält . Oft ist dafür | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,682 | 5,682 | ) schlagen vor , dass | Bibliotheken | direkt nach der Katastrophe die | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,720 | 5,720 | 2012 ) sagen , dass | Bibliotheken | sich darüber Gedanken machen sollten | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,817 | 5,817 | um über das Angebot der | Bibliothek | nachzudenken : Sollte es einfach | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,843 | 5,843 | 2018 ) betont , dass | Bibliotheken | aus der Erfahrung anderer Bibliotheken | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,848 | 5,848 | Bibliotheken aus der Erfahrung anderer | Bibliotheken | lernen können . ( Diese | bibliothek* |
| [31] - Karsten Schuldt (202 | 5,894 | 5,894 | beziehungsweise zu erfinden . Die | bibliothekarische | Literatur zu Katastrophen beschränkt sich | bibliothek* |
| [31] - Karsten Schuldt (202 | 6,296 | 6,296 | dann Ziele und Möglichkeiten von | Bibliotheken | in solchen Katastrophen bestimmt , | bibliothek* |
| [31] - Karsten Schuldt (202 | 6,368 | 6,368 | dazu dienen , dass sich | Bibliotheken | in andere Strukturen der Katastrophenplanung | bibliothek* |
| [31] - Karsten Schuldt (202 | 6,795 | 6,795 | , aber grundsätzlich für Öffentliche | Bibliotheken | zu übernehmen , findet sich | bibliothek* |
| [31] - Karsten Schuldt (202 | 6,825 | 6,825 | Liste von möglichen Gefährdungen der | Bibliothek | erstellt wird , ( 2 | bibliothek* |
| [31] - Karsten Schuldt (202 | 6,916 | 6,916 | , welche nur in dieser | Bibliothek | angeboten werden , ( 9 | bibliothek* |
| [31] - Karsten Schuldt (202 | 6,968 | 6,968 | wichtige Punkte . Für die | bibliothekarische | Ausbildung und die dort notwendigen | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,021 | 7,021 | , ob das Thema in | bibliothekswissenschaftlichen | Studiengängen in Nordamerika ausreichend vorkommt | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,105 | 7,105 | die Literatur zur Katastrophenplanung für | Bibliotheken | gesichtet und zusammengefasst wurde , | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,122 | 7,122 | was sich daraus für Öffentliche | Bibliotheken | , auch im DACH-Raum , | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,211 | 7,211 | immer wieder ähnliche Erfahrungen von | Bibliotheken | mit Katastrophenerfahrungen benennen und werden | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,227 | 7,227 | Richtlinien vorgestellt , wie eine | Bibliotheken | – oder ein Netzwerk von | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,233 | 7,233 | – oder ein Netzwerk von | Bibliotheken | – sich auf Katastrophen vorbereiten | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,259 | 7,259 | ein Katastrophenplan auch für Öffentliche | Bibliotheken | sinnvoll ist , damit in | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,330 | 7,330 | Gleichzeitig muss dafür von Öffentlichen | Bibliotheken | akzeptiert werden , dass es | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,480 | 7,480 | Aufgaben geklärt werden , welche | Bibliotheken | übernehmen können und wollen ; | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,523 | 7,523 | werden , in welche Netzwerke | Bibliotheken | bei Katastrophen eingebunden sein müssen | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,547 | 7,547 | geschehen muss . Ansonsten würden | Bibliotheken | gerade bei relevanten Institutionen schnell | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,640 | 7,640 | Informationssammlungen zum Thema Katastrophenplanung in | Bibliotheken | erarbeitet werden , muss die | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,684 | 7,684 | Sie sind wohl bei konkreten | Bibliotheken | , Netzwerken von Bibliotheken oder | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,688 | 7,688 | konkreten Bibliotheken , Netzwerken von | Bibliotheken | oder Verbänden besser aufgehoben als | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,785 | 7,785 | Pandemie , Teil des professionellen | bibliothekarischen | Handels werden sollte . Das | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,858 | 7,858 | Öffentlichen – und anderen – | Bibliotheken | wurden publiziert . Es ist | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,869 | 7,869 | also nicht notwendig , dass | Bibliotheken | von der nächsten auftretenden Krise | bibliothek* |
| [31] - Karsten Schuldt (202 | 7,991 | 7,991 | immer wieder betont , dass | Bibliotheken | als Ort vertrauenswürdiger Informationen agieren | bibliothek* |
| [31] - Karsten Schuldt (202 | 8,039 | 8,039 | , dass diese Aktivitäten von | Bibliotheken | nochmal gespiegelt würden . Auch | bibliothek* |
| [31] - Karsten Schuldt (202 | 8,051 | 8,051 | es unwahrscheinlich , dass gerade | Bibliotheken | bei Katastrophen im DACH-Raum der | bibliothek* |
| [31] - Karsten Schuldt (202 | 8,110 | 8,110 | zu diskutieren . Was sollen | Bibliotheken | machen ? Was können sie | bibliothek* |
| [31] - Karsten Schuldt (202 | 8,139 | 8,139 | erarbeitet werden muss , Teil | bibliothekarischer | Debatten und Berichte werden . | bibliothek* |
| [31] - Karsten Schuldt (202 | 8,472 | 8,472 | 7 . September 2017 . | Bibliotheksdienst | 52 , 1 , 5–15 | bibliothek* |
| [31] - Karsten Schuldt (202 | 9,209 | 9,209 | Zukunft : Bestandserhaltung heute . | Bibliotheksdienst | 36 , 12 , 1701–1713 | bibliothek* |
| [31] - Karsten Schuldt (202 | 9,849 | 9,849 | August 2014 in Weimar . | Bibliotheksdienst | 48 , 12 , 975–984 | bibliothek* |
| [31] - Karsten Schuldt (202 | 10,300 | 10,300 | Almuth 2012 . Themen . | Bibliotheken | . Die Gründung des Notfallverbunds | bibliothek* |
| [31] - Karsten Schuldt (202 | 10,309 | 10,309 | des Notfallverbunds Leipziger Archive und | Bibliotheken | . Bibliotheksdienst 46 , 7 | bibliothek* |
| [31] - Karsten Schuldt (202 | 10,311 | 10,311 | Leipziger Archive und Bibliotheken . | Bibliotheksdienst | 46 , 7 , 557–569 | bibliothek* |
| [31] - Karsten Schuldt (202 | 10,425 | 10,425 | plötzlichem Pilzbefall in Archiven , | Bibliotheken | und Museen . Bibliotheksdienst 40 | bibliothek* |
| [31] - Karsten Schuldt (202 | 10,429 | 10,429 | , Bibliotheken und Museen . | Bibliotheksdienst | 40 , 5 , 547–557 | bibliothek* |
| [31] - Karsten Schuldt (202 | 10,563 | 10,563 | Elisabeth 2003 . Katastrophenplanung in | Bibliotheken | : Notfallvorsorge und Schadensbehebung für | bibliothek* |
| [31] - Karsten Schuldt (202 | 10,749 | 10,749 | . Shared Print – Wie | Bibliotheken | in den Vereinigten Staaten und | bibliothek* |
| [31] - Karsten Schuldt (202 | 10,766 | 10,766 | Kultur- und Wissenschaftserbes sichern . | Bibliothek | Forschung und Praxis 43 , | bibliothek* |
| [31] - Karsten Schuldt (202 | 11,642 | 11,642 | in der Herzogin Anna Amalia | Bibliothek | , Weimar , 2004 ( | bibliothek* |
| [31] - Karsten Schuldt (202 | 11,747 | 11,747 | davon , dass die Öffentliche | Bibliotheken | , die sie befragten , | bibliothek* |
| [31] - Karsten Schuldt (202 | 11,780 | 11,780 | ( 2015 ) zeichnet für | Bibliotheken | im Nahen Osten und Nord | bibliothek* |
| [31] - Karsten Schuldt (202 | 11,805 | 11,805 | fehlender Krisenplanungen . Insoweit sind | Bibliotheken | anderer Ländern vielleicht mit solchen | bibliothek* |
| [31] - Karsten Schuldt (202 | 11,851 | 11,851 | elektronischen Angebote angewiesen . Obwohl | Bibliotheken | – auch die „ Heimatbibliothek | bibliothek* |
| [31] - Karsten Schuldt (202 | 12,017 | 12,017 | mit Hilfestellungen beschäftigten Einrichtungen die | Bibliotheken | und deren Möglichkeiten übersehen , | bibliothek* |
| [31] - Karsten Schuldt (202 | 12,035 | 12,035 | auch solche , die die | Bibliothek | sonst nicht nutzen – sich | bibliothek* |
| [31] - Karsten Schuldt (202 | 12,044 | 12,044 | – sich schnell an die | Bibliothek | wenden , entweder um Hilfe | bibliothek* |
| [31] - Karsten Schuldt (202 | 12,089 | 12,089 | zu finden , als bei | Bibliotheken | , deren Gemeinden gerade einen | bibliothek* |
| [32] - Christian Mathieu (2 | 26 | 26 | Artefakte zu überwinden , stellt | Bibliotheken | vor die Herausforderung , ihre | bibliothek* |
| [32] - Christian Mathieu (2 | 201 | 201 | Impulse zusätzlich befeuerte Prozesse eröffnen | Bibliotheken | gegenwärtig ungeahnte Chancen für ihre | bibliothek* |
| [32] - Christian Mathieu (2 | 282 | 282 | sie gerade in Archiven , | Bibliotheken | und Museen zu finden sind | bibliothek* |
| [32] - Christian Mathieu (2 | 445 | 445 | Materialitätsforschung zugleich als Handlungsimperativ für | Bibliotheken | ( und durchaus auch für | bibliothek* |
| [32] - Christian Mathieu (2 | 570 | 570 | “ eingestellt – , haben | Bibliotheken | tatsächlich bereits damit begonnen , | bibliothek* |
| [32] - Christian Mathieu (2 | 1,053 | 1,053 | Die Materialität von Schriftlichkeit – | Bibliothek | und Forschung im Dialog “ | bibliothek* |
| [33] - Christian Hauschke ( | 5,073 | 5,073 | Schriften des Forschungszentrums Jülich Reihe | Bibliothek | = Library , 12 ) | bibliothek* |
| [33] - Christian Hauschke ( | 6,039 | 6,039 | e.V ; Inst . für | Bibliotheks- | und Informationswiss . der Humboldt-Univ | bibliothek* |
| [33] - Christian Hauschke ( | 6,661 | 6,661 | In : 027.7 Zeitschrift für | Bibliothekskultur | 5 ( 1 ) , | bibliothek* |
| [33] - Christian Hauschke ( | 6,761 | 6,761 | ) : Wissenschaft und Digitale | Bibliothek | . 2 . Aufl . | bibliothek* |
| [33] - Christian Hauschke ( | 6,781 | 6,781 | o Inst . f . | Bibliotheks- | und Informationswissenschaft der Humboldt-Universität zu | bibliothek* |
| [34] - Alessandro Blasetti, | 36 | 36 | Potenzial und konkrete Herausforderungen von | bibliothekarischen | Serviceangeboten für den grünen Weg | bibliothek* |
| [34] - Alessandro Blasetti, | 421 | 421 | . Wie positioniert sich die | Bibliothek | bzw . der Repositorienbetreiber in | bibliothek* |
| [34] - Alessandro Blasetti, | 901 | 901 | . Vielerorts sind es die | Bibliotheken | , die sich für die | bibliothek* |
| [34] - Alessandro Blasetti, | 943 | 943 | Kurz gesagt , für wissenschaftliche | Bibliotheken | sind forschungsnahe Dienstleistungen im Bereich | bibliothek* |
| [34] - Alessandro Blasetti, | 988 | 988 | verfügbar zu machen . Wissenschaftliche | Bibliotheken | können und sollten hier ansetzen | bibliothek* |
| [34] - Alessandro Blasetti, | 1,077 | 1,077 | Wissenschaftler * innen in der | Bibliothek | kompetente Ansprechpartner * innen und | bibliothek* |
| [34] - Alessandro Blasetti, | 1,196 | 1,196 | im Rahmen des 107 . | Bibliothekstages | in Berlin ein „ Hands-on-Lab | bibliothek* |
| [34] - Alessandro Blasetti, | 1,371 | 1,371 | für den Auf- und Ausbau | bibliothekarischer | Services bieten . Gleichzeitig ist | bibliothek* |
| [34] - Alessandro Blasetti, | 1,383 | 1,383 | Beitrag auch ein Appell an | Bibliotheken | : Helfen Sie Ihren Wissenschaftler | bibliothek* |
| [34] - Alessandro Blasetti, | 1,525 | 1,525 | Beitrag richtet sich primär an | Bibliothekar | * innen aus dem deutschsprachigen | bibliothek* |
| [34] - Alessandro Blasetti, | 1,588 | 1,588 | Zweitveröffentlichung vorzunehmen , sind für | Bibliotheken | , vereinfacht dargestellt , die | bibliothek* |
| [34] - Alessandro Blasetti, | 2,197 | 2,197 | . Im Idealfall kann eine | Bibliothek | einen festen Stamm von Autor | bibliothek* |
| [34] - Alessandro Blasetti, | 2,490 | 2,490 | Cirasella 2017 ) : Viele | Bibliotheken | haben moralische und finanzielle Argumente | bibliothek* |
| [34] - Alessandro Blasetti, | 2,655 | 2,655 | diskutiert . Wie erhält die | Bibliothek | Kenntnis von Publikationen , die | bibliothek* |
| [34] - Alessandro Blasetti, | 2,973 | 2,973 | würden die Bedenken auch für | Bibliotheken | ein bedeutsames Hindernis darstellen , | bibliothek* |
| [34] - Alessandro Blasetti, | 3,057 | 3,057 | * innen dem Rat von | Bibliothekar | * innen vertrauen und entsprechend | bibliothek* |
| [34] - Alessandro Blasetti, | 3,080 | 3,080 | sich bei einer Beratung durch | bibliothekarisches | Fachpersonal grundsätzlich nicht um eine | bibliothek* |
| [34] - Alessandro Blasetti, | 3,398 | 3,398 | ihre Publikationen . Sofern die | Bibliothek | nicht selbst das Repositorium betreibt | bibliothek* |
| [34] - Alessandro Blasetti, | 3,415 | 3,415 | zwischen Autor * in und | Bibliothek | sowie Bibliothek und Repositorienbetreiber genutzt | bibliothek* |
| [34] - Alessandro Blasetti, | 3,417 | 3,417 | * in und Bibliothek sowie | Bibliothek | und Repositorienbetreiber genutzt werden . | bibliothek* |
| [34] - Alessandro Blasetti, | 3,723 | 3,723 | Frage 4 ) . Als | Bibliothek | alle Autor * innen einer | bibliothek* |
| [34] - Alessandro Blasetti, | 4,936 | 4,936 | Eine besondere Bedeutung kommt hier | Bibliotheken | zu , die für den | bibliothek* |
| [34] - Alessandro Blasetti, | 4,961 | 4,961 | ist denkbar , dass einzelne | Bibliotheken | besondere OA-Rechte mit einzelnen Verlagen | bibliothek* |
| [34] - Alessandro Blasetti, | 5,200 | 5,200 | Zweitveröffentlichung bieten . Will eine | Bibliothek | ohne Autor * innenkontakt OA-Rechte | bibliothek* |
| [34] - Alessandro Blasetti, | 5,212 | 5,212 | , kann dies für einzelne | Bibliotheken | im Alltag einen erheblichen Aufwand | bibliothek* |
| [34] - Alessandro Blasetti, | 6,308 | 6,308 | Verfügung gestellt . Hat eine | Bibliothek | keinen Zugriff , kann eine | bibliothek* |
| [34] - Alessandro Blasetti, | 6,445 | 6,445 | Mehraufwand und Personalkapazitäten aufseiten der | Bibliothek | erfordert , lohnt sich die | bibliothek* |
| [34] - Alessandro Blasetti, | 7,144 | 7,144 | und Zeitkapazität als Serviceleistung von | Bibliotheken | übernommen werden . Welche Metadaten | bibliothek* |
| [34] - Alessandro Blasetti, | 8,890 | 8,890 | , zu einer Positionierung der | Bibliothek | als Ansprechpartnerin für Fragen rund | bibliothek* |
| [34] - Alessandro Blasetti, | 8,963 | 8,963 | vor allem die Unsicherheit von | Bibliothekar | * innen hinsichtlich der eigenen | bibliothek* |
| [34] - Alessandro Blasetti, | 9,103 | 9,103 | im Rahmen von Zweitveröffentlichungsservices sind | Bibliotheken | regelmäßig mit Interpretationsspielräumen konfrontiert . | bibliothek* |
| [34] - Alessandro Blasetti, | 9,139 | 9,139 | Es liegt letztlich an den | Bibliotheken | selbst , sich dieser Freiheiten | bibliothek* |
| [34] - Alessandro Blasetti, | 9,331 | 9,331 | eine Handreichung für Repository-Manager , | Bibliothekare | und Autoren . https://doi.org/10.2312/allianzoa.004. Arbeitsgruppe | bibliothek* |
| [34] - Alessandro Blasetti, | 9,431 | 9,431 | . ( 2010 ) . | Bibliotheksurheberrecht | : ein Lehrbuch für Praxis | bibliothek* |
| [34] - Alessandro Blasetti, | 9,483 | 9,483 | “ . 107 . Deutscher | Bibliothekartag | , Berlin , 2018 . | bibliothek* |
| [34] - Alessandro Blasetti, | 10,034 | 10,034 | . o-bib . Das offene | Bibliotheksjournal | 3 , Nr . 4 | bibliothek* |
| [34] - Alessandro Blasetti, | 10,168 | 10,168 | für die Zweitveröffentlichung “ . | Bibliotheksdienst | 50 , Nr . 1 | bibliothek* |
| [34] - Alessandro Blasetti, | 10,203 | 10,203 | “ . 107 . Deutscher | Bibliothekartag | , Berlin , 2018 . | bibliothek* |
| [34] - Alessandro Blasetti, | 10,473 | 10,473 | ) teil , doch auch | Bibliothekar | * innen an Fachhochschulen ( | bibliothek* |
| [34] - Alessandro Blasetti, | 10,647 | 10,647 | der Einrichtung ? Übernimmt die | Bibliothek | transparent die Haftung für Zweitveröffentlichungen | bibliothek* |
| [34] - Alessandro Blasetti, | 10,698 | 10,698 | , Autor * in , | Bibliotheksleitung | , . . . ) | bibliothek* |
| [34] - Alessandro Blasetti, | 10,870 | 10,870 | Einrichtung ) ? Soll die | Bibliothek | die im Rahmen von Lizenzverträgen | bibliothek* |
| [34] - Alessandro Blasetti, | 10,992 | 10,992 | ( Autor * innen , | Bibliothek | ) ? Wie wird die | bibliothek* |
| [34] - Alessandro Blasetti, | 12,733 | 12,733 | – Universitätsmedizin Berlin , Medizinische | Bibliothek | Augustenburger Platz 1 D-13353 Berlin | bibliothek* |
| [34] - Alessandro Blasetti, | 12,972 | 12,972 | Regine Tobias auf dem Deutschen | Bibliothekartag | 2018 für das Beispiel KIT | bibliothek* |
| [34] - Alessandro Blasetti, | 13,244 | 13,244 | solcher Dokumente an das zuständige | Bibliothekspersonal | zu ermöglichen . Genauso wünschenswert | bibliothek* |
| [34] - Alessandro Blasetti, | 13,260 | 13,260 | Autor * innen mit der | Bibliothek | bereits zum Zeitpunkt der Annahme | bibliothek* |
| [35] - Fabian Steeg, Adrian | 3,094 | 3,094 | Reconciliation-API genutzt , während im | bibliothekarischen | Bereich das Interesse an der | bibliothek* |
| [35] - Fabian Steeg, Adrian | 3,653 | 3,653 | : O-Bib . Das Offene | Bibliotheksjournal | / Herausgeber VDB , 5 | bibliothek* |
| [35] - Fabian Steeg, Adrian | 3,730 | 3,730 | : lobid – Dateninfrastruktur für | Bibliotheken | . In : Informationspraxis 4 | bibliothek* |
| [36] - Nicole Eichenberger | 21 | 21 | kodikologische Forschung als auch für | Bibliotheken | und Archive als datenverwaltende Institutionen | bibliothek* |
| [36] - Nicole Eichenberger | 826 | 826 | deutschen Handschriftenzentren sowie in anderen | bibliothekarischen | und archivischen Forschungsprojekten ( Eckhardt | bibliothek* |
| [36] - Nicole Eichenberger | 1,218 | 1,218 | Hiltmann 2013 ) und in | bibliothekarisch-archivarischen | Kontexten ( Gradmann et al | bibliothek* |
| [36] - Nicole Eichenberger | 1,278 | 1,278 | z.B . digitalisierten Sammlungen von | Bibliotheken | , ermöglicht werden . Die | bibliothek* |
| [36] - Nicole Eichenberger | 3,444 | 3,444 | zu den digitalisierten Sammlungen von | Bibliotheken | oder zu Fachportalen wie dem | bibliothek* |
| [36] - Nicole Eichenberger | 3,862 | 3,862 | . Berlin : Institut für | Bibliotheks- | und Informationswissenschaft der Humboldt-Universität zu | bibliothek* |
| [38] - Christian Erlinger ( | 20 | 20 | über unsere Smartphones . Im | bibliothekarischen | Informationsdienst finden solche Medien teilweise | bibliothek* |
| [38] - Christian Erlinger ( | 166 | 166 | Access 1 Instant Messaging und | Bibliotheken | 2 OpenAccessButton.Org – Chatbot für | bibliothek* |
| [38] - Christian Erlinger ( | 386 | 386 | ( Fingerle 2017 ) Für | Bibliotheken | bieten Instant Messenger eine interessante | bibliothek* |
| [38] - Christian Erlinger ( | 435 | 435 | WhatsApp als zusätzlichen Kommunikationskanal im | bibliothekarischen | Auskunftsdienst . Die Stärke des | bibliothek* |
| [38] - Christian Erlinger ( | 467 | 467 | der unmittelbaren Koppelung an die | Bibliotheksbestandsdaten | . Die vorliegende Arbeit präsentiert | bibliothek* |
| [38] - Christian Erlinger ( | 630 | 630 | man die Quelle . Bei | Bibliothekskatalogen | und Verlagsdatenbanken muss man in | bibliothek* |
| [38] - Christian Erlinger ( | 667 | 667 | Seer 2017 ) Warum sollten | Bibliotheken | , die mit viel Engagement | bibliothek* |
| [38] - Christian Erlinger ( | 1,656 | 1,656 | * 14 Metadatenschema an . | Bibliotheken | betreiben einen nicht zu unterschätzenden | bibliothek* |
| [38] - Christian Erlinger ( | 1,774 | 1,774 | interessante Distributions- und Kommunikationskanäle für | Bibliotheken | . Bots bieten dabei , | bibliothek* |
| [38] - Christian Erlinger ( | 2,045 | 2,045 | Auskunftsdienst von öffentlichen und wissenschaftlichen | Bibliotheken | in Deutschland . Suttgart . | bibliothek* |
| [38] - Christian Erlinger ( | 2,080 | 2,080 | einem am 33 . Österreichischen | Bibliothekartag | am 15 . September 2017 | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 34 | 34 | des Medienkompetenzrahmens sind Kooperationen mit | Bibliotheken | als Bildungspartner in den Kommunen | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 60 | 60 | aus Bildung , Politik und | Bibliothek | zusammen , die über Formen | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 242 | 242 | werden ? Und was können | Bibliotheken | durch Förderung der Medien- und | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 259 | 259 | Diese Fragen treibt insbesondere Öffentliche | Bibliotheken | zunehmend um , die ihre | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 411 | 411 | Dazu gehören auch die Öffentlichen | Bibliotheken | , denen sich , wie | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 458 | 458 | Kulturfördergesetz NRW ist vorgesehen , | Bibliotheken | dabei zu unterstützen , diesem | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 517 | 517 | zu vermitteln , können Öffentlichen | Bibliotheken | die Schulen ihres Einzugsgebietes dabei | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 623 | 623 | dar , sich über die | Bibliothek | als Kooperationspartner zu informieren oder | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 701 | 701 | zwischen den Bildungspartnern Schule und | Bibliothek | auszuloten . Dafür bot der | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,257 | 1,257 | Zusammenarbeit mit Bildungseinrichtungen „ Bildungspartnerschaft | Bibliothek | und Schule “ wurde 2016 | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,290 | 1,290 | Schulen im Rahmen der Bildungspartnerschaft | Bibliothek | und Schule in Ibbenbüren dar | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,305 | 1,305 | verbindliche Grundlage für die weitere | Bibliotheksarbeit | beschlossen . Vorgestellt wurden die | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,369 | 1,369 | hier ebenfalls Kooperationen mit der | Bibliothek | . Die in den Jahren | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,388 | 1,388 | und der Fachstelle für öffentliche | Bibliotheken | in NRW entwickelten Angebote sind | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,515 | 1,515 | Wandels ist die Notwendigkeit eines | Bibliothekskonzeptes | für die Stadtbücherei Ibbenbüren unter | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,536 | 1,536 | Dezember 2017 die Erstellung eines | Bibliothekskonzeptes | beschlossen . Im Konzept zur | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,545 | 1,545 | Konzept zur „ Entwicklung einer | Bibliotheksstrategie | für die Stadtbücherei Ibbenbüren 2019-2024 | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,571 | 1,571 | Erkundungstag in einer neuen innovativen | Bibliothek | , auch eine Tagung der | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,631 | 1,631 | , die Fachstelle für öffentliche | Bibliotheken | in NRW , Medienberatung , | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,657 | 1,657 | aus dem Kreis Steinfurt , | Bibliotheken | aus dem Münsterland , Schulleiterinnen | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,670 | 1,670 | Schulen und AnsprechpartnerInnen der Bildungspartnerschaft | Bibliothek | und Schule . Eröffnet wurde | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,708 | 1,708 | Er würdigte die Arbeit der | Bibliothek | in diesem Zusammenhang , die | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,738 | 1,738 | Die Angebote und Services der | Bibliothek | im Rahmen der Medien- und | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,783 | 1,783 | dem Medienkompetenzrahmen NRW in der | Bibliothek | gestaltet sind und welche Chancen | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,831 | 1,831 | einen schriftlichen Gruß an die | Bibliotheksleitung | und die Teilnehmenden des Fachtages15 | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,925 | 1,925 | , CC BY 4.0 Öffentliche | Bibliotheken | in Nordrhein-Westfalen sind bereits seit | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,949 | 1,949 | Büning von der Fachstelle Öffentliche | Bibliotheken | NRW16 präsentierte in ihrem Vortrag | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,956 | 1,956 | präsentierte in ihrem Vortrag „ | Bibliotheken | als Kooperationspartner im digitalen Wandel | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,974 | 1,974 | Konzepten zur Medienkompetenzförderung , die | Bibliotheken | bereits erfolgreich in Zusammenarbeit mit | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 1,989 | 1,989 | Büning beschreibt die Funktionen Öffentlicher | Bibliotheken | in vier Bereichen : Vermittlung | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,020 | 2,020 | „ Digitalen Kompetenzzentrums “ . | Bibliotheken | als Kompetenzzentren würden im Bereich | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,105 | 2,105 | erlauben . Damit sei die | Bibliothek | ein „ Haus der Ressourcen | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,204 | 2,204 | wo und wie Kooperationen zwischen | Bibliothek | und Schule beim Medienkompetenzrahmen NRW | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,238 | 2,238 | Ort und können auch für | Bibliotheken | Ansprechpartnerinnen sein bei Fragen rund | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,256 | 2,256 | die Zusammenarbeit zwischen Medienberatung und | Bibliothek | sehr fruchtbar sein kann , | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,340 | 2,340 | Projekt „ Bildungspartner NRW - | Bibliothek | und Schule “ 20 , | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,443 | 2,443 | haben zum Beispiel Schule und | Bibliothek | gemeinsam Ende 2018 den Wettbewerb | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,511 | 2,511 | aller Schulstufen inzwischen in die | Bibliothek | , um die Module zur | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 2,974 | 2,974 | wurden zum Beispiel Bildungspartnerschaften mit | Bibliotheken | , die sich auf die | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 3,062 | 3,062 | der Bücherei , MedienpädagogInnen in | Bibliothek | und Schule , die Lehrende | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 3,162 | 3,162 | verbessern , um Bildungspartnerschaften zwischen | Bibliothek | und Schule zu befördern und | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 3,208 | 3,208 | für die medienpädagogische Unterstützung in | Bibliothek | und Schule zu schaffen . | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 3,604 | 3,604 | schaffen . Gabriele Fahrenkrog , | Bibliothekarin | MA ( LIS ) , | bibliothek* |
| [39] - Gabriele Fahrenkrog, | 3,638 | 3,638 | , Dipl . Verw.Wirtin und | Bibliotheksleiterin | , Stadtbücherei Ibbenbüren , Oststraße | bibliothek* |
| [40] - Christian Hauschke, | 1,304 | 1,304 | dem SWB Katalog des Südwestdeutschen | Bibliotheksverbundes | ( SWB ) . Zudem | bibliothek* |
| [40] - Christian Hauschke, | 2,542 | 2,542 | strukturierten Datenbasis der auf dem | bibliothekarischen | Arbeitsmarkt gefragten Kompetenzen auf Basis | bibliothek* |
| [40] - Christian Hauschke, | 2,555 | 2,555 | . Weiterhin wurden Inhalte aktueller | bibliotheks- | und informationswissenschaftlicher Curricula und Weiterbildungsangebote | bibliothek* |
| [41] - Joanna Einbock, Chri | 1,097 | 1,097 | andere themenrelevante Positionen beispielsweise als | Bibliotheksleitung | ( drei Personen ) , | bibliothek* |
| [41] - Joanna Einbock, Chri | 1,462 | 1,462 | dienen vorrangig der Unterstützung des | Bibliothekswesens | der befragten Einrichtungen ( von | bibliothek* |
| [41] - Joanna Einbock, Chri | 5,102 | 5,102 | Deutschland “ am Institut für | Bibliotheks- | und Informationswissenschaft an der Humboldt-Universität | bibliothek* |
| [42] - Adrian Pohl, Fabian | 62 | 62 | des hbz-Verbundkatalogs , Beschreibungen von | bibliothekarischen | Organisationen und anderen Gedächtnisinstitutionen aus | bibliothek* |
| [42] - Adrian Pohl, Fabian | 73 | 73 | dem Sigelverzeichnis und der Deutschen | Bibliotheksstatistik | ( DBS ) sowie auf | bibliothek* |
| [42] - Adrian Pohl, Fabian | 451 | 451 | an Mitarbeiter * innen in | bibliothekarischen | und wissenschaftlichen Einrichtungen im gesamten | bibliothek* |
| [42] - Adrian Pohl, Fabian | 464 | 464 | . Zum einen sind dies | Bibliothekar | * innen und Wissenschaftler * | bibliothek* |
| [42] - Adrian Pohl, Fabian | 708 | 708 | lobid-API bietet einheitlichen Zugriff auf | bibliothekarische | Daten über eine webbasierte Programmierschnittstelle | bibliothek* |
| [42] - Adrian Pohl, Fabian | 798 | 798 | , nachhaltigen Anwendungen auf Basis | bibliothekarischer | Daten ( siehe auch Steeg | bibliothek* |
| [42] - Adrian Pohl, Fabian | 3,018 | 3,018 | dabei eine große Unterstützung im | bibliothekarischen | Bereich , insbesondere bei der | bibliothek* |
| [42] - Adrian Pohl, Fabian | 3,342 | 3,342 | unseres Entwicklungsprozesses , durch das | bibliothekarische | Anforderungen und Entwicklung miteinander verzahnt | bibliothek* |
| [42] - Adrian Pohl, Fabian | 3,368 | 3,368 | , einer fachlich-inhaltlichen Begutachtung aus | bibliothekarischer | Sicht , und Code Review | bibliothek* |
| [42] - Adrian Pohl, Fabian | 4,615 | 4,615 | performante und vielseitige Infrastruktur für | bibliothekarische | Daten an . Die lobid-Quelldaten | bibliothek* |
| [43] - Oliver Sievi, Andrea | 141 | 141 | leisten . BARTOC ; Wissenschaftliche | Bibliothek | ; Wissensorganisationssysteme ; Semantic Web | bibliothek* |
| [43] - Oliver Sievi, Andrea | 717 | 717 | Schlagwortindexes gehen auf das ehemalige | Bibliothekssystem | Swissbase aus dem Jahr 1990 | bibliothek* |
| [43] - Oliver Sievi, Andrea | 2,518 | 2,518 | “ online stöbern ” im | Bibliotheksregal | ermöglicht werden . Beim Klick | bibliothek* |
| [44] - Christian Hauschke, | 1,350 | 1,350 | den Einsatz von Vitro im | bibliothekarischen | Bereich sind die Projekte Linked | bibliothek* |
| [44] - Christian Hauschke, | 1,393 | 1,393 | bildet – für Katalogisierung von | bibliothekarischen | Metadaten als Linked Data entwickelt | bibliothek* |
| [44] - Christian Hauschke, | 1,466 | 1,466 | . 4 : Erfassung von | bibliothekarischen | Daten mit VitroLib Neben der | bibliothek* |
| [44] - Christian Hauschke, | 1,474 | 1,474 | VitroLib Neben der Standard-Erfassung der | bibliothekarischen | Metadaten bietet VitroLib auf Vitro | bibliothek* |
| [44] - Christian Hauschke, | 1,845 | 1,845 | unter anderem in musealen oder | bibliothekarischen | Bereichen , wo die Anwendung | bibliothek* |
| [45] - Karsten Schuldt, Azr | 317 | 317 | 3.2 Erfahrungsbericht 3.3 Nutzung von | Bibliotheken | durch hochgradig sehbehinderte und blinde | bibliothek* |
| [45] - Karsten Schuldt, Azr | 330 | 330 | Einsatz von Assistiven Technologien in | Bibliotheken | und Museen 3.5 Entwicklung der | bibliothek* |
| [45] - Karsten Schuldt, Azr | 368 | 368 | 4 Fazit 5 Fact-Sheet für | Bibliotheken | und andere Gedächtniseinrichtungen 6 Literatur | bibliothek* |
| [45] - Karsten Schuldt, Azr | 565 | 565 | der Fachliteratur von Gedächtniseinrichtungen ( | Bibliotheken | , Archiven , Museen ) | bibliothek* |
| [45] - Karsten Schuldt, Azr | 656 | 656 | Berichte , die auch für | Bibliotheken | sinnvoll zu nutzen wären . | bibliothek* |
| [45] - Karsten Schuldt, Azr | 667 | 667 | Diese scheinen aber in der | bibliothekarischen | Fachliteratur nicht berücksichtigt zu werden | bibliothek* |
| [45] - Karsten Schuldt, Azr | 913 | 913 | also Museen , Archive und | Bibliotheken | ) sowie Ämter ein , | bibliothek* |
| [45] - Karsten Schuldt, Azr | 1,294 | 1,294 | der Bemühungen um Inklusion in | Bibliotheken | und anderen Gedächtniseinrichtungen recherchiert sowie | bibliothek* |
| [45] - Karsten Schuldt, Azr | 1,628 | 1,628 | dies nicht . In verschiedenen | Bibliotheken | , Archiven und Museen fanden | bibliothek* |
| [45] - Karsten Schuldt, Azr | 1,959 | 1,959 | das Vorhalten von Braille-Zeilen in | Bibliotheken | sich als denkbar , aber | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,141 | 2,141 | Blinde und Menschen mit Sehbehinderungen | Bibliotheken | eigentlich sehr wenig nutzen . | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,196 | 2,196 | wie Menschen mit dieser Beeinträchtigung | Bibliotheken | besser nutzen könnten , 10 | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,214 | 2,214 | kaum ein Interesse an der | Bibliotheksnutzung | besteht . Dies ist für | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,221 | 2,221 | . Dies ist für Wissenschaftliche | Bibliotheken | anders , aber Frau Zimmermann | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,237 | 2,237 | für Studierende mit Behinderungen die | Bibliotheksnutzung | nur eines der Probleme darstellt | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,341 | 2,341 | darunter ein Archiv , fünf | Bibliotheken | und drei Museen , befragt | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,787 | 2,787 | wie man Sehbehinderte in die | bibliothekarische | Arbeit miteinbeziehen kann . Für | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,802 | 2,802 | kontaktierte ich vier grosse Schweizer | Bibliotheken | , von denen drei den | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,827 | 2,827 | meine Anfrage . Die Schweizerische | Bibliothek | für Sehbehinderte war die einzige | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,855 | 2,855 | es sich spezifisch um eine | Bibliothek | für Sehbehinderte handelt , hielt | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,862 | 2,862 | Sehbehinderte handelt , hielt die | Bibliothek | es für sinnvoll auch Leute | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,899 | 2,899 | Kundenberatung eingesetzt . Die anderen | Bibliotheken | beschäftigten keine Menschen mit einer | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,956 | 2,956 | die Frage , ob die | Bibliotheken | ihre Einrichtung so umstrukturieren sollten | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,974 | 2,974 | geboten werden kann , in | Bibliotheken | tätig zu sein . Sigrid | bibliothek* |
| [45] - Karsten Schuldt, Azr | 2,998 | 2,998 | Part mit der Nutzung von | Bibliotheken | durch sehbehinderte und blinde Menschen | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,022 | 3,022 | gefunden . Alle Befragten nutzen | Bibliotheken | , die meisten von ihnen | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,050 | 3,050 | die Nutzung der teilweise in | Bibliotheken | vorhandenen Geräte angewiesen . Aus | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,074 | 3,074 | wichtig für die Nutzung von | Bibliotheken | durch blinde und hochgradig sehbehinderte | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,088 | 3,088 | die gute Zugänglichkeit über die | Bibliothekswebseite | die gute Erreichbarkeit mit öffentlichem | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,111 | 3,111 | Unterstützung durch kompetentes und hilfsbereites | Bibliothekspersonal | ein auf Wünsche und Anforderungen | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,145 | 3,145 | Hörfilme ) Öffentliche und wissenschaftliche | Bibliotheken | könnten ihr Angebot für blinde | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,216 | 3,216 | , wenn öffentliche und wissenschaftliche | Bibliotheken | die Aufmerksamkeit der Menschen mit | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,241 | 3,241 | Zweiergruppe war am Unterschied zwischen | Bibliotheken | und Museen interessiert und wollte | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,284 | 3,284 | besuchten wir je drei grosse | Bibliotheken | und Museen in der Deutschschweiz | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,418 | 3,418 | Videoform auf einem Tablet . | Bibliotheken | bieten den BesucherInnen bei der | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,469 | 3,469 | war , dass alle besuchten | Bibliotheken | auch das Personal als AT | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,503 | 3,503 | zurückgreifen . Dies ist den | Bibliotheken | bewusst und es wird deshalb | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,564 | 3,564 | Nutzung von AT Unterschiede zwischen | Bibliotheken | und Museen bestehen . Unsere | bibliothek* |
| [45] - Karsten Schuldt, Azr | 3,579 | 3,579 | die These auf , dass | Bibliotheken | eher lokal verankert sind , | bibliothek* |
| [45] - Karsten Schuldt, Azr | 5,044 | 5,044 | schon vorhanden . Gerade in | Bibliotheken | und Archiven ist hilfsbereites Personal | bibliothek* |
| [45] - Karsten Schuldt, Azr | 5,493 | 5,493 | ) . „ Die inklusive | Bibliothek | – Teilhabe an Bibliotheken durch | bibliothek* |
| [45] - Karsten Schuldt, Azr | 5,497 | 5,497 | inklusive Bibliothek – Teilhabe an | Bibliotheken | durch Menschen mit ( Seh- | bibliothek* |
| [45] - Karsten Schuldt, Azr | 5,530 | 5,530 | ) . „ Die inklusive | Bibliothek | : Teilhabe an Bibliotheken durch | bibliothek* |
| [45] - Karsten Schuldt, Azr | 5,534 | 5,534 | inklusive Bibliothek : Teilhabe an | Bibliotheken | durch Menschen mit Seheinschränkungen ‟ | bibliothek* |
| [45] - Karsten Schuldt, Azr | 5,585 | 5,585 | BIS – Das Magazin der | Bibliotheken | in Sachsen 9 ( 2016 | bibliothek* |
| [45] - Karsten Schuldt, Azr | 6,355 | 6,355 | wie Menschen mit Rollstuhl Öffentliche | Bibliotheken | in der Schweiz nutzen könnten | bibliothek* |
| [45] - Karsten Schuldt, Azr | 6,425 | 6,425 | genannte Bachelorarbeit zur Nutzung von | Bibliotheken | durch Menschen mit Rollstuhl ( | bibliothek* |
| [45] - Karsten Schuldt, Azr | 6,617 | 6,617 | oder die flexible Nutzung des | Bibliotheksraumes | durch flexible Möbel für Blinde | bibliothek* |
| [45] - Karsten Schuldt, Azr | 6,647 | 6,647 | über die flexible Nutzung von | Bibliotheken | praktisch nicht auf . 11 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 28 | 28 | Konzept Makerspace auch für kleinere | Bibliotheken | in der Schweiz umsetzen lässt | bibliothek* |
| [46] - Karsten Schuldt, Rud | 47 | 47 | reichhaltigen Erfahrungen mit Makerspaces in | Bibliotheken | angeschlossen , gleichzeitig an die | bibliothek* |
| [46] - Karsten Schuldt, Rud | 57 | 57 | die Möglichkeiten und Potentiale kleinerer | Bibliotheken | angepasst . In vier Bibliotheken | bibliothek* |
| [46] - Karsten Schuldt, Rud | 62 | 62 | Bibliotheken angepasst . In vier | Bibliotheken | wurde das Konzept “ Mobiler | bibliothek* |
| [46] - Karsten Schuldt, Rud | 178 | 178 | das Ziel von Makerspaces in | Bibliotheken | sein soll . Makerspace ; | bibliothek* |
| [46] - Karsten Schuldt, Rud | 185 | 185 | soll . Makerspace ; Öffentliche | Bibliothek | ; Projekt ; Gemeindebibliothek ; | bibliothek* |
| [46] - Karsten Schuldt, Rud | 419 | 419 | nutzen 2.3 Voraussetzungen in schweizerischen | Bibliotheken | 2.4 Thesen 3 Boxen im | bibliothek* |
| [46] - Karsten Schuldt, Rud | 563 | 563 | in den letzten Jahren in | Bibliotheken | unter dem Schlagwort “ Makerspace | bibliothek* |
| [46] - Karsten Schuldt, Rud | 586 | 586 | es auch für kleinere Öffentliche | Bibliotheken | sinnvoll einzusetzen ist ? Und | bibliothek* |
| [46] - Karsten Schuldt, Rud | 638 | 638 | Handreichung für kantonale Fachstellen für | Bibliotheken | ( oder ähnliche Einrichtungen , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 653 | 653 | in den deutschen Bundesländern oder | Bibliothekssysteme | mit vielen kleinen Filialen ) | bibliothek* |
| [46] - Karsten Schuldt, Rud | 668 | 668 | für die von ihnen betreuten | Bibliotheken | anbieten wollen . Diese Handreichung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 752 | 752 | nicht zu übersehbaren Entwicklungen im | Bibliothekswesen | , auf Arbeiten , die | bibliothek* |
| [46] - Karsten Schuldt, Rud | 771 | 771 | auf den Spezifika des schweizerischen | Bibliothekssystems | . Grundsätzlich hat sich die | bibliothek* |
| [46] - Karsten Schuldt, Rud | 780 | 780 | sich die Idee , in | Bibliotheken | Makerspaces einzurichten , etabliert . | bibliothek* |
| [46] - Karsten Schuldt, Rud | 848 | 848 | und Hinweisen zu Makerspaces in | Bibliotheken | vorhanden , sondern ebenso Handbücher | bibliothek* |
| [46] - Karsten Schuldt, Rud | 923 | 923 | Howard 2013 ; ausserhalb des | Bibliothekswesens | aber auch in deutsch , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 999 | 999 | Makerspaces und ihrer Nutzung in | Bibliotheken | , sondern auch ein Beispiel | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,077 | 1,077 | Die Prototypen wurden in vier | Bibliotheken | eingesetzt . Nach der Schilderung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,108 | 1,108 | die Weiterentwicklung von Makerspaces in | Bibliotheken | und auch für die Bibliotheksforschung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,113 | 1,113 | Bibliotheken und auch für die | Bibliotheksforschung | im Allgemeinen relevant . Abgeschlossen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,181 | 1,181 | Makerspaces in kleinen und kleinsten | Bibliotheken | umgesetzt werden könnten . Dabei | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,229 | 1,229 | für eine vollständige Ausstattung pro | Bibliothek | zu hoch . Nicht zuletzt | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,268 | 1,268 | die immer wieder neu im | Bibliotheksraum | aufgebaut werden , da der | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,304 | 1,304 | schweizerischen Gemeinden oder das mobile | Bibliothekslabor | der Stadtbibliothek Mannheim , vgl | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,413 | 1,413 | der Literatur zu Makerspaces in | Bibliotheken | geschlossen , ( a ) | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,476 | 1,476 | angesammelte Wissen über Makerspaces in | Bibliotheken | nutzen . Die vorliegenden Berichte | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,510 | 1,510 | untersuchte in einer Studie kleine | Bibliotheken | in Wisconsin , die Makerspaces | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,527 | 1,527 | , was diese von vergleichbaren | Bibliotheken | unterscheidet . ( Crawford Barniskis | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,547 | 1,547 | für diesen Bundesstaat und die | Bibliotheken | im ländlichen Raum – der | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,561 | 1,561 | Makerspaces erklären würde . Die | Bibliotheken | , welche einen Makerspace haben | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,587 | 1,587 | fand sich in allen diesen | Bibliotheken | Personal , das davon überzeugt | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,599 | 1,599 | , dass die Aufgabe von | Bibliotheken | über die reine Ausleihe von | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,642 | 1,642 | auch auf soziale Funktionen von | Bibliotheken | im ländlichen Raum ein – | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,655 | 1,655 | aber fest , dass die | Bibliotheken | selber “ described the goals | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,726 | 1,726 | 2017 ) Viele Berichte aus | Bibliotheken | verstärkten diesen Eindruck . Zwar | bibliothek* |
| [46] - Karsten Schuldt, Rud | 1,829 | 1,829 | Interview-Studie mit Personal aus 12 | Bibliotheken | in den USA und Kanada | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,162 | 2,162 | auch die strukturellen Voraussetzung der | Bibliotheken | im ländlichen Raum in der | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,172 | 2,172 | der Schweiz . Da die | Bibliotheksstatistik | Schweiz nur 12 der 26 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,194 | 2,194 | über die kleinen und kleinsten | Bibliotheken | in der Schweiz zu machen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,226 | 2,226 | eine relativ grosse Verbreitung von | Bibliotheken | , auch in kleineren Gemeinden | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,242 | 2,242 | aber vielen , finden sich | Bibliotheken | , die vor allem betrieben | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,261 | 2,261 | Mitarbeiterinnen , die entweder keine | bibliothekarische | Ausbildung haben oder aber einen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,275 | 2,275 | Schweizerisches Arbeitsgemeinschaft für allgemeine öffentliche | Bibliotheken | ) besuchten , der Grundkenntnisse | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,282 | 2,282 | besuchten , der Grundkenntnisse der | bibliothekarischen | Arbeit vermittelt . Gleichzeitig haben | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,324 | 2,324 | durch kantonale Fachstellen für Öffentliche | Bibliotheken | ( mit unterschiedlichen Namen ) | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,452 | 2,452 | ist zu vermuten , dass | Bibliotheken | , eher als in Städten | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,525 | 2,525 | und finanziell sind viele dieser | Bibliotheken | angemessen , aber auch nicht | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,567 | 2,567 | Aber grundsätzlich müssen sich die | Bibliotheken | angesichts knapper Ressourcen mit ihren | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,580 | 2,580 | . Eine ganze Anzahl dieser | Bibliotheken | entfalten im Rahmen ihrer Möglichkeiten | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,611 | 2,611 | z.B . viele neu eingerichtete | Bibliothekscafés | finden – z.B . in | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,619 | 2,619 | z.B . in der neugebauten | Bibliothek | und Ludothek Spiez , BE | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,655 | 2,655 | es in kleinen und kleineren | Bibliotheken | der Schweiz engagiertes Personal für | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,679 | 2,679 | zumindest in einer Anzahl von | Bibliotheken | und ( b ) dass | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,732 | 2,732 | ) gerade Projekte für diese | Bibliotheken | in kleineren Gemeinden sinnvoll sind | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,774 | 2,774 | Basis der vorliegenden Erfahrungen aus | Bibliotheken | ( und anderen Einrichtungen wie | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,833 | 2,833 | , ist es für die | Bibliotheken | möglich , diese auch sehr | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,927 | 2,927 | ( siehe unten ) in | Bibliotheken | getestet wurde . Die Grundlinien | bibliothek* |
| [46] - Karsten Schuldt, Rud | 2,991 | 2,991 | häufig in den Berichten von | Bibliotheken | finden . 3 Die dritte | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,064 | 3,064 | mussten positive Erfahrungen aus anderen | Bibliotheken | vorliegen . Das bedingt , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,120 | 3,120 | mussten den Erfahrungen aus anderen | Bibliotheken | nach grundsätzlich viel aushalten ( | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,442 | 3,442 | den kantonalen Fachstellen für Öffentliche | Bibliotheken | der Kantone Aargau und Zürich | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,480 | 3,480 | Boxen wurde jeweils in zwei | Bibliotheken | ausprobiert . Sie wurden den | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,486 | 3,486 | ausprobiert . Sie wurden den | Bibliotheken | per Kurier rund eine Woche | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,536 | 3,536 | Interesse war , was die | Bibliotheken | konkret organisiert hatten und das | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,574 | 3,574 | Interview über die Erfahrungen der | Bibliothek | mit der jeweiligen Veranstaltung durchgeführt | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,616 | 3,616 | welche Formen von Veranstaltungen die | Bibliotheksmitarbeiterinnen | entworfen hatten , welche sozialen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,759 | 3,759 | und wöchentlichen Spielenachmittagen . Die | Bibliothek | beschäftigt z.T Personal , dass | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,771 | 3,771 | Hochschulebene ( HTW Chur ) | bibliothekarisch | ausgebildet ist und ist grundsätzlich | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,786 | 3,786 | ausgestattet als die anderen drei | Bibliotheken | , die am Projekt teilnahmen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,796 | 3,796 | teilnahmen . Die von der | Bibliothek | organisierte Veranstaltung , welche unter | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,833 | 3,833 | 14-17 Uhr statt . Die | Bibliothek | hatte sich dazu entschieden , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 3,895 | 3,895 | Tischen im unteren Stock der | Bibliothek | verteilt , ebenso an dem | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,059 | 4,059 | und damit in der ganzen | Bibliothek | zu hören , dies schien | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,080 | 4,080 | Die Veranstaltung war für die | Bibliothek | gut besucht . Die drei | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,255 | 4,255 | dass sie oft von den | Bibliothekarinnen | eingeladen werden mussten , mitzumachen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,420 | 4,420 | schon kannten . Durch die | Bibliothekarinnen | geschah eine grössere Integration der | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,561 | 4,561 | auch taten . Ausserhalb der | Bibliothek | war die Veranstaltung nicht sichtbar | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,578 | 4,578 | das auch so von der | Bibliothek | gewollt . Im Anschluss äusserten | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,587 | 4,587 | Anschluss äusserten sich die befragte | Bibliothekarin | , dass sie sich in | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,686 | 4,686 | und eine Herbstmesse . Die | Bibliothek | ist auf jeder dieser Messen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,730 | 4,730 | Saales – die Veranstaltung der | Bibliothek | . Im Vorfeld hatte die | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,736 | 4,736 | . Im Vorfeld hatte die | Bibliothek | einige Werbung gemacht . Schon | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,789 | 4,789 | Präsentation der Makerspaces-Box durch die | Bibliothek | Die Veranstaltung fand an vier | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,840 | 4,840 | wurde betreut , zwei von | Bibliothekarinnen | ( 3D Drucker , Scan’n’Cut | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,892 | 4,892 | der Veranstaltung hatte sich das | Bibliotheksteam | in der Bibliothek und anschliessend | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,895 | 4,895 | sich das Bibliotheksteam in der | Bibliothek | und anschliessend auch privat mit | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,924 | 4,924 | der Eindruck , dass die | Bibliothekarinnen | alle , die auf die | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,960 | 4,960 | die Nutzerinnen und Nutzer der | Bibliothek | . Es kam zu vielen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 4,977 | 4,977 | zu positiven Rückmeldungen an die | Bibliothekarinnen | über die Veranstaltung selber . | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,037 | 5,037 | Uitikon mit dem Aufbau der | Bibliothek | auf der Bühne im Hintergrund | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,044 | 5,044 | der Bühne im Hintergrund Die | Bibliothek | hatte für die Techniken eine | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,258 | 5,258 | Uitikon Die Rückbindung an die | Bibliothek | , über die Werbung im | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,285 | 5,285 | dass dies eine Veranstaltung der | Bibliothek | sei . Die Menschen , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,303 | 5,303 | so , weil sie die | Bibliothekarinnen | offenbar kannten . Die Herbstmesse | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,373 | 5,373 | auffällig war , dass die | Bibliothekarinnen | es offenbar gewohnt sind , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,554 | 5,554 | auf dem Platz vor der | Bibliothek | aufgebaut war , statt . | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,561 | 5,561 | war , statt . Die | Bibliothek | war für diesen Markt ausnahmsweise | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,573 | 5,573 | . Es fand der normale | Bibliotheksalltag | statt , zusätzlich eine Leseveranstaltung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,603 | 5,603 | . Im Vorfeld hatte die | Bibliothek | mit Plakaten im eigenen Schaufenster | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,638 | 5,638 | Abbildung 8 : Plakat der | Bibliothek | Wettswil für die Veranstaltung Abbildung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,653 | 5,653 | die Veranstaltung im Schaufenster der | Bibliothek | Wettswil , direkt am Platz | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,670 | 5,670 | Die Technologien waren in der | Bibliothek | verteilt : An einem Tisch | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,717 | 5,717 | Im Gegensatz zu den anderen | Bibliotheken | wurden diese Technologien nicht eng | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,729 | 5,729 | sondern eher locker durch zwei | Bibliothekarinnen | , die gleichzeitig auch den | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,888 | 5,888 | schon Nutzerinnen und Nutzer der | Bibliothek | gewesen , aber normalerweise seien | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,902 | 5,902 | Jungen und Männer in der | Bibliothek | , meinten die Bibliotheksmitarbeiterinnen . | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,906 | 5,906 | der Bibliothek , meinten die | Bibliotheksmitarbeiterinnen | . Wie auch im normalen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,912 | 5,912 | . Wie auch im normalen | Bibliotheksalltag | stellten Jugendliche nach dem Primarschulalter | bibliothek* |
| [46] - Karsten Schuldt, Rud | 5,988 | 5,988 | insgesamt recht lebhaft in der | Bibliothek | . Wenn Eltern anwesend waren | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,045 | 6,045 | Tastatur steuern konnten . Die | Bibliothekarinnen | schätzten die Stimmung ein als | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,085 | 6,085 | eine solche Veranstaltung in der | Bibliothek | stattfindet . Es wurde sowohl | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,112 | 6,112 | in Zukunft könnte sich die | Bibliothek | ähnliche Veranstaltungen vorstellen und würde | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,137 | 6,137 | der Veranstaltung begeistert . Die | Bibliothek | wird im Sommer 2017 umziehen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,191 | 6,191 | Kantons Aargau dar . Die | Bibliothek | Möhlin , auch in einem | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,260 | 6,260 | Jeweils eine Person – drei | Bibliothekarinnen | sowie der Sohn einer Leseförderin | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,474 | 6,474 | zusätzlich angeschaffte Literatur in der | Bibliothek | Möhlin Auf dem Tisch mit | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,502 | 6,502 | Werbung wurde im Newsletter der | Bibliothek | und den Terminkalendern regionaler Zeitungen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,515 | 6,515 | zudem wurde am Tresen der | Bibliothek | ein Flyer ausgelegt und in | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,522 | 6,522 | Flyer ausgelegt und in der | Bibliothek | bzw . dem Aufsteller direkt | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,536 | 6,536 | Da die Veranstaltung in der | Bibliothek | stattfand , wurde die Verbindung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,543 | 6,543 | , wurde die Verbindung zur | Bibliothek | durch die Nutzerinnen und Nutzer | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,562 | 6,562 | mit Kindern . Laut der | Bibliothek | auch viele Männer , die | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,570 | 6,570 | Männer , die ansonsten die | Bibliothek | selten besuchen würden , und | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,611 | 6,611 | die Schule regelmässig in die | Bibliothek | kommen . Es galt aber | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,641 | 6,641 | nur . Nach Angaben der | Bibliothek | kamen einige Männer explizit , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,790 | 6,790 | selber als innovativ für eine | Bibliothek | dieser Grösse und führten darauf | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,821 | 6,821 | an einem – für die | Bibliothek | zu grossen – stationären Makerspace | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,925 | 6,925 | . Wenn sich in der | Bibliothek | engagiertes Personal findet , entwickelt | bibliothek* |
| [46] - Karsten Schuldt, Rud | 6,999 | 6,999 | war auffällig , dass die | Bibliotheken | , die sich relativ spontan | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,053 | 7,053 | gewissen Gemeinde- und damit auch | Bibliotheksgrösse | ( alle Bibliotheken , die | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,056 | 7,056 | damit auch Bibliotheksgrösse ( alle | Bibliotheken | , die teilnahmen , hatten | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,065 | 7,065 | , hatten eine Gruppe von | Bibliothekarinnen | , keine arbeitete für sich | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,122 | 7,122 | Vorgaben von aussen . Alle | Bibliotheken | , mit dem engagierten Personal | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,155 | 7,155 | . Unterstützung organisierten sich die | Bibliothekarinnen | z.T . innerhalb ihrer Familie | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,174 | 7,174 | die Veranstaltungen , welche die | Bibliotheken | im Rahmen ihrer lokalen Möglichkeiten | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,252 | 7,252 | von den sozialen Interaktionen zwischen | Bibliothekspersonal | und Nutzenden sowie zwischen den | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,265 | 7,265 | geprägt waren . Dass die | Bibliotheksmitarbeiterinnen | einen Grossteil der Teilnehmenden aus | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,272 | 7,272 | Grossteil der Teilnehmenden aus der | bibliothekarischen | Arbeit und dem Alltag in | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,314 | 7,314 | Fähigkeiten und das Wissen der | Bibliothekarinnen | geprägt zu sein . Bei | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,370 | 7,370 | gab , sich auf die | Bibliothek | bezogen , welche die Veranstaltung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,379 | 7,379 | die Veranstaltung als Erweiterung des | bibliothekarischen | Angebotes ansahen und kommentierten . | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,394 | 7,394 | wenn die Veranstaltung ausserhalb der | Bibliotheksräume | stattfand . Für die Nutzenden | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,423 | 7,423 | von Veranstaltung zum Angebot von | Bibliotheken | zählen kann und sollte . | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,449 | 7,449 | einem positiven Bild von der | Bibliothek | bei . Überraschend war , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,497 | 7,497 | in der Literatur von anderen | Bibliotheken | berichtet – worden . Offenbar | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,543 | 7,543 | Publikationen vor , spezifisch für | Bibliotheken | in Englisch , für Schulen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,571 | 7,571 | ) Es wäre für die | Bibliotheken | also einfach möglich gewesen , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,682 | 7,682 | zukünftige Organisation von Makerspaces in | Bibliotheken | – egal welcher Grösse – | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,710 | 7,710 | . Obwohl dies von einigen | Bibliotheken | positiv gesehen wird , da | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,734 | 7,734 | sich sonst weniger für die | Bibliothek | interessieren würden ) , sollte | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,754 | 7,754 | als ein innovatives Angebot für | Bibliotheken | angesehen und mit positiven Potenzialen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,788 | 7,788 | untermauern . Es ist im | Bibliothekswesen | nicht ausdiskutiert , ob diese | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,904 | 7,904 | Status bei der Nutzung der | Bibliotheken | ) . Für die Entwicklung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,923 | 7,923 | dass das Personal in den | Bibliotheken | nicht unterschätzt werden sollte . | bibliothek* |
| [46] - Karsten Schuldt, Rud | 7,980 | 7,980 | es für die Entwicklung von | Bibliotheken | sinnvoll , dieses zu fördern | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,007 | 8,007 | beigetragen , dass sich die | Bibliothekarinnen | ohne grosse Vorbereitung und ohne | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,054 | 8,054 | Techniken und Methoden in den | Bibliotheken | fördern . Die Mitarbeitenden könnten | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,093 | 8,093 | Innovation gerade auch in kleineren | Bibliotheken | . Wie erwähnt , schien | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,143 | 8,143 | ja , sollte es im | Bibliothekswesen | als Desiderat benannt werden . | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,162 | 8,162 | Diskussionen über die Zukunft von | Bibliotheken | . Wenn diese Literatur nicht | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,201 | 8,201 | in Zeiten , in denen | Bibliotheken | sich als ständig in Veränderung | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,211 | 8,211 | Veränderung begreifen – in der | bibliothekarischen | Praxis das Lesen und Nutzen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,269 | 8,269 | Methode für die Weiterentwicklung von | Bibliotheken | . 11 Für die Frage | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,280 | 8,280 | , mit welchen Angeboten sich | Bibliotheken | weiterentwickeln sollen , insbesondere der | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,303 | 8,303 | die Abläufe und Eigenheiten der | Bibliotheken | sowie ihres Umfeldes in den | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,317 | 8,317 | . Gerade kleinere und kleine | Bibliotheken | sind eng mit ihrem Umfeld | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,502 | 8,502 | konnte , dass Erfahrungen aus | Bibliotheken | des Auslands tatsächlich genutzt werden | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,514 | 8,514 | , um funktionierende Angebote für | Bibliotheken | im schweizerischen Kontext zu entwerfen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,527 | 8,527 | gezeigt wurde , dass auch | Bibliotheken | in kleineren Gemeinden selbständig und | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,549 | 8,549 | eigentliche Ziel von Makerspaces in | Bibliotheken | ? Zu Beginn wurde erwartet | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,574 | 8,574 | konkreten Veranstaltungen , die von | Bibliotheken | ja in realen Situationen entworfen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,601 | 8,601 | Veranstaltungen , welche in den | Bibliotheken | durchgeführt wurden und die grossen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,716 | 8,716 | und Begründung für Makerspaces in | Bibliotheken | liefert das 4-Spaces-Modell mit dem | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,788 | 8,788 | erwähnt , als Thema im | Bibliothekswesen | etabliert . Es ist erstaunlich | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,815 | 8,815 | der Literatur noch in konkreten | Bibliotheken | . 12 ( Willet 2016 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,840 | 8,840 | wieder sowohl als Thema für | Bibliotheken | als auch als konkrete Angebote | bibliothek* |
| [46] - Karsten Schuldt, Rud | 8,848 | 8,848 | als konkrete Angebote in konkreten | Bibliotheken | ( Fontichiaro 2016a , 2016b | bibliothek* |
| [46] - Karsten Schuldt, Rud | 9,484 | 9,484 | Mundraub-Tour und Foodsharing » . | Bibliotheksdienst | 51 , Nr . 2 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 9,581 | 9,581 | . « Makerspaces in öffentlichen | Bibliotheken | : Eine Untersuchung der didaktischen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 9,770 | 9,770 | mehr . Verlangen Sie bessere | Bibliotheken | für eine komplexer gewordene Welt | bibliothek* |
| [46] - Karsten Schuldt, Rud | 9,786 | 9,786 | Berlin : Simon Verlag für | Bibliothekswissen | ( Bibliotheksforschung ) , 2016 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 9,788 | 9,788 | Simon Verlag für Bibliothekswissen ( | Bibliotheksforschung | ) , 2016 . Meinhardt | bibliothek* |
| [46] - Karsten Schuldt, Rud | 9,812 | 9,812 | Creatorspace- und Makerspace-Bewegung und die | Bibliotheken | » . BuB 66 , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,161 | 10,161 | Makerspaces für kleinere und kleinste | Bibliotheken | . Bericht und Materialien zum | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,193 | 10,193 | und Vorschläge für Makerspaces in | Bibliotheken | : Sammelrezension . RESSI 17 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,430 | 10,430 | für Kreativität und Wissenstransfer : | Bibliotheken | als Makerspace » . BuB | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,625 | 10,625 | Hochschulen ) , alle Öffentlichen | Bibliotheken | in Städten über 10.000 Einwohnerinnen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,641 | 10,641 | die in diesem Projekt interessierende | Bibliotheken | kleinerer Gemeinden nur in 12 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,705 | 10,705 | einigen Kantonen ist das Öffentliche | Bibliothekswesen | auch anders organisiert , z.B | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,713 | 10,713 | organisiert , z.B . mit | Bibliotheksentwicklungsplänen | , in der Romandie sind | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,866 | 10,866 | fanden sich auch noch mehr | Bibliotheken | , denen abgesagt werden musste | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,888 | 10,888 | Thema Makerspaces auch in kleineren | Bibliotheken | der Schweiz auf grosses Interesse | bibliothek* |
| [46] - Karsten Schuldt, Rud | 10,929 | 10,929 | speziell zu tun . Die | Bibliothekarinnen | waren darüber weniger überrascht als | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,020 | 11,020 | sondern auch Projektberichte aus anderen | Bibliotheken | . Ebenso lag ein Handbuch | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,033 | 11,033 | LibraryBoxes vor . Nur eine | Bibliothek | – Möhlin – beschäftigte sich | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,140 | 11,140 | der Kritik von Makerspaces in | Bibliotheken | , bei Willet ( 2016 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,172 | 11,172 | werden . ↩ Für die | Bibliotheksforschung | kann auch dies eine interessante | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,200 | 11,200 | , während gleichzeitig in offiziellen | bibliothekarischen | Texten ( z.B . Jahresberichte | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,207 | 11,207 | ( z.B . Jahresberichte von | Bibliotheken | ) ein Diskurs vorherrscht , | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,279 | 11,279 | Hochschulen ) , alle Öffentlichen | Bibliotheken | in Städten über 10.000 Einwohnerinnen | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,295 | 11,295 | die in diesem Projekt interessierende | Bibliotheken | kleinerer Gemeinden nur in 12 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,359 | 11,359 | einigen Kantonen ist das Öffentliche | Bibliothekswesen | auch anders organisiert , z.B | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,367 | 11,367 | organisiert , z.B . mit | Bibliotheksentwicklungsplänen | , in der Romandie sind | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,520 | 11,520 | fanden sich auch noch mehr | Bibliotheken | , denen abgesagt werden musste | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,542 | 11,542 | Thema Makerspaces auch in kleineren | Bibliotheken | der Schweiz auf grosses Interesse | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,583 | 11,583 | speziell zu tun . Die | Bibliothekarinnen | waren darüber weniger überrascht als | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,674 | 11,674 | sondern auch Projektberichte aus anderen | Bibliotheken | . Ebenso lag ein Handbuch | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,687 | 11,687 | LibraryBoxes vor . Nur eine | Bibliothek | – Möhlin – beschäftigte sich | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,794 | 11,794 | der Kritik von Makerspaces in | Bibliotheken | , bei Willet ( 2016 | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,826 | 11,826 | werden . ↩ Für die | Bibliotheksforschung | kann auch dies eine interessante | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,854 | 11,854 | , während gleichzeitig in offiziellen | bibliothekarischen | Texten ( z.B . Jahresberichte | bibliothek* |
| [46] - Karsten Schuldt, Rud | 11,861 | 11,861 | ( z.B . Jahresberichte von | Bibliotheken | ) ein Diskurs vorherrscht , | bibliothek* |
| [47] - Jakob Voß, Laura Bod | 688 | 688 | einige im Projekt coli-conc ermittelten | Bibliotheksklassifikationen | und verwandte Systeme ( Balakrishnan | bibliothek* |
| [47] - Jakob Voß, Laura Bod | 711 | 711 | sollte , die im deutschsprachigen | bibliothekarischen | Bereich überregional genutzt werden ( | bibliothek* |
| [49] - Jana Mersmann, Chris | 1,878 | 1,878 | Veranstaltungen ausgesprochen . Integration von | Bibliothekskatalogen | über SPARQL-Endpoint 1 Datenintegration Integration | bibliothek* |
| [49] - Jana Mersmann, Chris | 2,000 | 2,000 | Ontologie / Architektur Vorkategorisierung VIVO | Bibliothek | Forschungseinrichtu ng Sonstiges Exportschnittstellen ( | bibliothek* |
| [50] - Christian Wilke, Reg | 82 | 82 | 3 Wieviel Mehraufwand entsteht für | Bibliotheken | ? - Eine Ressourcenabschätzung 4 | bibliothek* |
| [50] - Christian Wilke, Reg | 237 | 237 | Werkzeuge entwickelt , die es | Bibliotheken | ermöglichen , Zitationsbeziehungen zwischen einzelnen | bibliothek* |
| [50] - Christian Wilke, Reg | 309 | 309 | vor . Die Materialien einer | Bibliothek | vollständig mit allen ihren Beziehungen | bibliothek* |
| [50] - Christian Wilke, Reg | 333 | 333 | die Zukunftsvision der Linked-Open-Data-Technologie in | Bibliotheken | . Das LOC-DB-Projekt ziele darauf | bibliothek* |
| [50] - Christian Wilke, Reg | 504 | 504 | Daten und die Verknüpfung von | bibliothekarischen | Nachweissystemen und anderen Quellen . | bibliothek* |
| [50] - Christian Wilke, Reg | 609 | 609 | und -Workflows das Projekt aus | bibliothekarischer | Perspektive . Die Rolle der | bibliothek* |
| [50] - Christian Wilke, Reg | 655 | 655 | Gesamtprojekt . Zunächst habe die | Bibliothek | als Datengrundlage einen Ausschnitt des | bibliothek* |
| [50] - Christian Wilke, Reg | 772 | 772 | aus dem Katalog des Südwestdeutschen | Bibliotheksverbunds | ( SWB ) und für | bibliothek* |
| [50] - Christian Wilke, Reg | 1,847 | 1,847 | direkt in das im Südwestdeutschen | Bibliotheksverbund | ( SWB ) genutzte Pica-Format | bibliothek* |
| [50] - Christian Wilke, Reg | 1,896 | 1,896 | zum Beispiel aus Verlagswebseiten oder | Bibliothekskatalogen | sammelt ( Zotero Picker ) | bibliothek* |
| [50] - Christian Wilke, Reg | 2,220 | 2,220 | seit Langem bewährte Metadatenkompetenz der | Bibliothekare | . Per Web-Konferenz wurde schließlich | bibliothek* |
| [50] - Christian Wilke, Reg | 2,556 | 2,556 | Zitationsdaten ein neues Aufgabenfeld für | Bibliotheken | darstellen . Auch in der | bibliothek* |
| [50] - Christian Wilke, Reg | 2,580 | 2,580 | , bestand Einigkeit : Die | Bibliotheksverbünde | sollten hier Verantwortung übernehmen . | bibliothek* |
| [50] - Christian Wilke, Reg | 2,665 | 2,665 | , einen Blick auf eine | bibliothekarische | Zukunftstechnologie zu werfen , die | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 770 | 770 | insbesondere aus dem Blickwinkel der | Bibliotheken | . Die Autorinnen und Autoren | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 902 | 902 | ausschließen . Ist das freie | Bibliothekssystem | Koha eine Alternative zu anderen | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 914 | 914 | Systemen , die vielfach in | Bibliotheken | eingesetzt werden ? , fragt | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 931 | 931 | in seinem Kurzbericht Ein freies | Bibliothekssystem | für wissenschaftliche Bibliotheken – Werkstattbericht | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 934 | 934 | Ein freies Bibliothekssystem für wissenschaftliche | Bibliotheken | – Werkstattbericht der IST Austria | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 1,027 | 1,027 | kulturellen Inhalten der Horizont von | Bibliothekskatalogen | erweitert werden kann . Sie | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 1,142 | 1,142 | Thema Open Data an Wissenschaftlichen | Bibliotheken | in der Schweiz . In | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 1,176 | 1,176 | leitet daraus konkrete Handlungsempfehlungen für | Bibliotheken | ab . Durch die Betrachtung | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 1,214 | 1,214 | allen Facetten von Offenheit in | Bibliotheken | , Archiven und Museen sind | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 1,255 | 1,255 | : Open Data an Wissenschaftlichen | Bibliotheken | der Schweiz . In : | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 1,337 | 1,337 | , Márton : Ein freies | Bibliothekssystem | für wissenschaftliche Bibliotheken - Werkstattbericht | bibliothek* |
| [51] - Gabriele Fahrenkrog, | 1,340 | 1,340 | Ein freies Bibliothekssystem für wissenschaftliche | Bibliotheken | - Werkstattbericht der IST Austria | bibliothek* |
| [52] - Eckhart Arnold, Stef | 896 | 896 | im Zusammenhang mit einem ausgebauten | Bibliothekssystem | ermöglichen , die referierte Literatur | bibliothek* |
| [52] - Eckhart Arnold, Stef | 1,001 | 1,001 | welchen Praxis-Regeln sollten Informationsdienste wie | Bibliotheken | , Archive , Repositorien und | bibliothek* |
| [52] - Eckhart Arnold, Stef | 2,518 | 2,518 | Maßstäbe angelegt werden : Eine | Bibliothek | , die wissenschaftliche Sekundärliteratur wie | bibliothek* |
| [52] - Eckhart Arnold, Stef | 3,272 | 3,272 | im Rahmen der Konsolidierung des | Bibliothekskatalogs | , namentlich der Zusammenführung von | bibliothek* |
| [52] - Eckhart Arnold, Stef | 3,777 | 3,777 | seinen Lemmaansätzen zuordnet . Sogar | Bibliothekssignaturen | können sich ändern oder verschwinden | bibliothek* |
| [52] - Eckhart Arnold, Stef | 3,812 | 3,812 | ist es , wenn die | Bibliothek | eine veraltete Signatur neu verwendet | bibliothek* |
| [52] - Eckhart Arnold, Stef | 4,160 | 4,160 | / de / home / | bibliothek | / digitale-bibliothek-wdb / garantieerklaerung.html . | bibliothek* |
| [52] - Eckhart Arnold, Stef | 8,470 | 8,470 | Einträge im BV-Katalog wurden von | bibliothekarischen | Fachkräften vorgenommen , was eine | bibliothek* |
| [52] - Eckhart Arnold, Stef | 8,694 | 8,694 | ist es nur für ausgebildete | Bibliothekare | und Bibliothekarinnen sicher erkennbar , | bibliothek* |
| [52] - Eckhart Arnold, Stef | 8,696 | 8,696 | nur für ausgebildete Bibliothekare und | Bibliothekarinnen | sicher erkennbar , welchem Katalogeintrag | bibliothek* |
| [53] - Salome Zehnder (2017 | 45 | 45 | und Anwendung der Methode im | Bibliotheksbereich | . Durch den Einsatz von | bibliothek* |
| [53] - Salome Zehnder (2017 | 90 | 90 | Lernatmosphäre “ erhoben werden . | Bibliothek | als Raum ; Nutzerbedürfnisse ; | bibliothek* |
| [53] - Salome Zehnder (2017 | 214 | 214 | Die Fotobefragung 3 Fotobefragung in | Bibliotheken | 4 Fotobefragung an der HFGZ | bibliothek* |
| [53] - Salome Zehnder (2017 | 332 | 332 | sie für die Erhebung von | Bibliotheksnutzer-Bedürfnissen | geeignet sind . Auch wurde | bibliothek* |
| [53] - Salome Zehnder (2017 | 360 | 360 | für die ‚ neue ‘ | Bibliothek | erstellt . Neben bereits bekannten | bibliothek* |
| [53] - Salome Zehnder (2017 | 381 | 381 | Fotobefragung angewandt , die im | Bibliotheksbereich | bisher nur wenig Bekanntheit geniesst | bibliothek* |
| [53] - Salome Zehnder (2017 | 414 | 414 | wird auf bisherige Erfahrungen im | Bibliotheksbereich | hingewiesen um schliesslich die im | bibliothek* |
| [53] - Salome Zehnder (2017 | 439 | 439 | Methode der Fotobefragung in der | Bibliothekswelt | etwas bekannter zu machen , | bibliothek* |
| [53] - Salome Zehnder (2017 | 1,099 | 1,099 | Räumen bildhaft erheben . Im | Bibliotheksbereich | machte die University of Rochester | bibliothek* |
| [53] - Salome Zehnder (2017 | 1,256 | 1,256 | an bestimmten Orten in der | Bibliothek | . Bei der „ entfremdenden | bibliothek* |
| [53] - Salome Zehnder (2017 | 1,337 | 1,337 | Benutzern an Orten in der | Bibliothek | wollten Greifeneder und Seadle „ | bibliothek* |
| [53] - Salome Zehnder (2017 | 1,693 | 1,693 | langen Aufgabenlisten von in anderen | Bibliotheken | durchgeführten Erhebungen nicht übernommen werden | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,141 | 2,141 | des liebsten Arbeitsplatzes ausserhalb der | Bibliothek | zu machen . Diese Aufgabe | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,195 | 2,195 | drinnen oder draussen , eine | Bibliothek | , ein Café oder im | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,320 | 2,320 | dass unterschiedliche Ansichten von verschiedenen | Bibliotheken | dabei waren . So gab | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,344 | 2,344 | aber auch Weitwinkelaufnahmen von ganzen | Bibliotheksräumen | oder Teilen davon . Die | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,440 | 2,440 | zeigte sich , dass eine | Bibliothek | verschiedene Bereiche mit spezifischen Funktionen | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,591 | 2,591 | fanden vor allem Bilder von | Bibliotheksräumen | mit viel Licht oder grossen | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,785 | 2,785 | sich bei Fragen an das | Bibliothekspersonal | wenden kann , wurde von | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,884 | 2,884 | wie für die Nutzer eine | Bibliothek | aussehen und ausgestattet sein sollte | bibliothek* |
| [53] - Salome Zehnder (2017 | 2,970 | 2,970 | wie die Arbeitsflächen in einer | Bibliothek | gestaltet sein sollten : vor | bibliothek* |
| [53] - Salome Zehnder (2017 | 3,009 | 3,009 | , was ihnen in einem | Bibliotheksraum | gefällt und was nicht . | bibliothek* |
| [53] - Salome Zehnder (2017 | 3,364 | 3,364 | : Maktaba Yangu – Meine | Bibliothek | . Qualitative Benutzerforschung an der | bibliothek* |
| [53] - Salome Zehnder (2017 | 3,489 | 3,489 | Lernräumen . Berliner Handreichungen zur | Bibliotheks- | und Informationswissenschaft . Heft 277 | bibliothek* |
| [53] - Salome Zehnder (2017 | 3,638 | 3,638 | o.J . ) : Öffentliche | Bibliothek | Francois Villon . Verfügbar unter | bibliothek* |
| [53] - Salome Zehnder (2017 | 3,664 | 3,664 | ( 2013 ) : Lesesaal | Bibliothek | Birmingham . Verfügbar unter : | bibliothek* |
| [53] - Salome Zehnder (2017 | 3,689 | 3,689 | ( o.J . ) : | Bibliothek | Land- und Amtsgericht Düsseldorf . | bibliothek* |
| [53] - Salome Zehnder (2017 | 3,715 | 3,715 | ( 2010 ) : GESS | Bibliothek | KOM_000059 . Verfügbar via http://ba.e-pics.ethz.ch/ | bibliothek* |
| [53] - Salome Zehnder (2017 | 3,725 | 3,725 | http://ba.e-pics.ethz.ch/ ( Suchterm „ GESS | Bibliothek | “ ) [ Zugriff am | bibliothek* |
| [54] - Christian Koller (20 | 951 | 951 | gleichzeitig stagnierenden oder gar rückläufigen | Bibliotheksbudgets | . 5 Zwischen 1999 und | bibliothek* |
| [54] - Christian Koller (20 | 989 | 989 | Daraus resultierte bei vielen wissenschaftlichen | Bibliotheken | eine Reduktion der Zeitschriftenabonnements , | bibliothek* |
| [54] - Christian Koller (20 | 1,265 | 1,265 | , Verlagen , Universitäten , | Bibliotheken | und gelehrten Gesellschaften zusammengesetzte Kommission | bibliothek* |
| [54] - Christian Koller (20 | 1,968 | 1,968 | Die Auswirkungen auf die wissenschaftlichen | Bibliotheken | als hauptsächliche Informationszentren sind noch | bibliothek* |
| [54] - Christian Koller (20 | 2,040 | 2,040 | elektronische Zeitungen ein Bedeutungsverlust der | Bibliotheken | befürchtet . Der Finch-Report zeichnete | bibliothek* |
| [54] - Christian Koller (20 | 2,167 | 2,167 | , sondern auch den öffentlichen | Bibliotheken | gebührenfrei zur Verfügung stellen sollten | bibliothek* |
| [54] - Christian Koller (20 | 2,178 | 2,178 | , um die Publikumsattraktivität der | Bibliotheken | zu stärken . 20 Davon | bibliothek* |
| [54] - Christian Koller (20 | 3,425 | 3,425 | zweifache Abkassieren bei Autoren und | Bibliotheken | bei hybriden Zeitschriften . Der | bibliothek* |
| [54] - Christian Koller (20 | 3,628 | 3,628 | Und im Bereich der öffentlichen | Bibliotheken | hat in den letzten Jahren | bibliothek* |
| [54] - Christian Koller (20 | 3,659 | 3,659 | 343 von ursprünglich 4'290 öffentlichen | Bibliotheken | geschlossen . Die Zahl bezahlter | bibliothek* |
| [54] - Christian Koller (20 | 3,669 | 3,669 | bezahlter Mitarbeiter / -innen im | Bibliothekswesen | ging von 31'977 auf 24'044 | bibliothek* |
| [54] - Christian Koller (20 | 3,704 | 3,704 | universitärer Bildung als auch zu | bibliothekarischer | Grundversorgung hat damit also massive | bibliothek* |
| [54] - Christian Koller (20 | 4,048 | 4,048 | des Hochschulstudiums und des Abbaus | bibliothekarischer | Grundversorgung ein prioritäres Interesse gerade | bibliothek* |
| [54] - Christian Koller (20 | 5,631 | 5,631 | Denken . Online . Die | Bibliothek | als Managementaufgabe : Festschrift für | bibliothek* |
| [55] - Marco Humbel (2017). | 73 | 73 | von Open Content in Wissenschaftlichen | Bibliotheken | der Schweiz konkret aussieht . | bibliothek* |
| [55] - Marco Humbel (2017). | 99 | 99 | der Autor eine Handlungsempfehlung für | Bibliotheken | . Digitalisierung , OpenGLAM , | bibliothek* |
| [55] - Marco Humbel (2017). | 311 | 311 | der Plattformen mithilfe des Kriterienkataloges | Bibliotheken | investieren vermehrt Ressourcen in Digitalisierungsprojekte | bibliothek* |
| [55] - Marco Humbel (2017). | 401 | 401 | war 2013 die Einbindung von | Bibliotheken | , Archiven und Museen in | bibliothek* |
| [55] - Marco Humbel (2017). | 481 | 481 | zum Schluss , dass Wissenschaftliche | Bibliotheken | sich vermehrt der Open Philosophie | bibliothek* |
| [55] - Marco Humbel (2017). | 525 | 525 | dass Open Data für die | Bibliotheken | heutzutage eine Chance bietet , | bibliothek* |
| [55] - Marco Humbel (2017). | 603 | 603 | konzentrierte sich bislang auf die | Bibliotheken | . Auch spiegelt eine quantitative | bibliothek* |
| [55] - Marco Humbel (2017). | 675 | 675 | von Open Data in Wissenschaftlichen | Bibliotheken | der Schweiz aus ? Der | bibliothek* |
| [55] - Marco Humbel (2017). | 767 | 767 | von Open Data in Wissenschaftlichen | Bibliotheken | der Schweiz aufzeigen zu können | bibliothek* |
| [55] - Marco Humbel (2017). | 785 | 785 | der Autor eine Handlungsempfehlung für | Bibliotheken | und Verantwortliche aus diesem Bereich | bibliothek* |
| [55] - Marco Humbel (2017). | 1,960 | 1,960 | entsprechende Auswahl an geeigneten Wissenschaftlichen | Bibliotheken | zu treffen . Voraussetzung war | bibliothek* |
| [55] - Marco Humbel (2017). | 1,997 | 1,997 | Die Auswahl der unten genannten | Bibliotheken | , beziehungsweise den entsprechenden Plattformen | bibliothek* |
| [55] - Marco Humbel (2017). | 2,015 | 2,015 | oder der mehrfachen Nennung der | Bibliothek | in der Literatur , bezüglich | bibliothek* |
| [55] - Marco Humbel (2017). | 2,053 | 2,053 | beachten , dass eine untersuchte | Bibliothek | auch bei mehreren Plattformen beteiligt | bibliothek* |
| [55] - Marco Humbel (2017). | 2,470 | 2,470 | Vertreter der entsprechenden oder beteiligten | Bibliothek | zwischen dem 12.05.2016 und dem | bibliothek* |
| [55] - Marco Humbel (2017). | 2,773 | 2,773 | am stärksten umgesetzt . In | Bibliotheken | liegt sie bei 9 % | bibliothek* |
| [55] - Marco Humbel (2017). | 3,239 | 3,239 | Digitalisate erwünscht wird . Die | Bibliotheken | machen auf den Plattformen allenfalls | bibliothek* |
| [55] - Marco Humbel (2017). | 3,426 | 3,426 | zum Auftrag , den die | Bibliothek | als Wissensvermittlerin innehat , gesehen | bibliothek* |
| [55] - Marco Humbel (2017). | 3,593 | 3,593 | ist ein Thema in den | Bibliotheken | und wird diskutiert . Anders | bibliothek* |
| [55] - Marco Humbel (2017). | 3,861 | 3,861 | Open Data wird die Wissenschaftlichen | Bibliotheken | und die GLAM allgemein , | bibliothek* |
| [55] - Marco Humbel (2017). | 3,901 | 3,901 | Mit Open Data steht den | Bibliotheken | eine neue Form zur Verfügung | bibliothek* |
| [55] - Marco Humbel (2017). | 4,097 | 4,097 | von Open Data in Wissenschaftlichen | Bibliotheken | . Es gilt festzuhalten , | bibliothek* |
| [55] - Marco Humbel (2017). | 4,271 | 4,271 | stark von den Ressourcen der | Bibliotheken | abhängig . Ebenso hat eine | bibliothek* |
| [55] - Marco Humbel (2017). | 4,299 | 4,299 | , dass wenn für eine | Bibliothek | die Möglichkeit besteht , die | bibliothek* |
| [55] - Marco Humbel (2017). | 4,718 | 4,718 | eines Manifests , vor . | Bibliotheken | können sich dabei , wie | bibliothek* |
| [55] - Marco Humbel (2017). | 5,044 | 5,044 | Trend unter den Gedächtnisnstitutionen . | Bibliotheksdienst | , 50 ( 1 ) | bibliothek* |
| [55] - Marco Humbel (2017). | 5,493 | 5,493 | Linked Open Data in der | Bibliothekswelt | : Grundlagen und Überblick . | bibliothek* |
| [55] - Marco Humbel (2017). | 5,516 | 5,516 | Open ) linked data in | Bibliotheken | . Berlin : de Gruyter | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 29 | 29 | ( OA ) aus der | Bibliothekspraxis | zusammen . Am Beispiel des | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 67 | 67 | kulturelle Inhalte der Horizont von | Bibliothekskatalogen | erweitert werden kann . Zugleich | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 333 | 333 | und übersteigt die Budgets kleiner | Bibliotheken | . Obwohl offene Lizenzen die | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 577 | 577 | und Vernetzung häufig an den | bibliothekarischen | Informations- ( vermittlungs- ) Systemen | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 1,145 | 1,145 | . Neben der Standardrecherche des | bibliothekseigenen | Medienbestandes ( NEBIS , lizensierte | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 1,940 | 1,940 | ca 25'000'000 Datensätze jener Schweizer | Bibliotheken | , die einem der neun | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 1,984 | 1,984 | bearbeitet , die zwar selten | bibliothekarischen | Vorgaben ( MARC21 ) folgen | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 2,087 | 2,087 | angereichert und gefiltert8 . Die | bibliothekarischen | Erschliessungsinstrumente ( kontrollierte Vokabulare ( | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 2,213 | 2,213 | selbe Medium in unterschiedlichen ( | Bibliotheks- | ) Kontexten zugewiesen wurde ( | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 2,509 | 2,509 | die Dokumentation des Kontextwissens der | Bibliotheksbestände | der Mediathek bisher am Modell | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 2,912 | 2,912 | Klassifikationen und Vernetzungsstrukturen werden im | Bibliothekskontext | seit langem diskutiert und implementiert | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 3,502 | 3,502 | beansprucht haben , können auch | Bibliotheken | wichtige Hinweise für Veränderungen geben | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 3,518 | 3,518 | die Strukturen und Außengrenzen der | Bibliotheken | in diesem Sinne offen und | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 4,309 | 4,309 | In : 027 Zeitschrift für | Bibliothekskultur | ( Vol . 4 , | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 4,396 | 4,396 | 8 . November ) : | Bibliotheken | sollten ihre Daten öffnen . | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 4,585 | 4,585 | In : 027 Zeitschrift für | Bibliothekskultur | ( Vol . 4 , | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 4,748 | 4,748 | zu Berlin . Institut für | Bibliotheks- | und Informationswissenschaft . Berlin [ | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 4,885 | 4,885 | erschwert dies die Nachnutzung im | Bibliothekenkontext | . Zudem ist i.d.R . | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 5,001 | 5,001 | anders und zwar sowohl auf | Bibliotheks- | als auch auf Verbundebene . | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 5,251 | 5,251 | ) ; OpenLayers ( JavaScript | Bibliothek | für bekannte Waypoint Format / | bibliothek* |
| [56] - Tabea Lurk, Jürgen E | 5,432 | 5,432 | , etc . ↩ Die | bibliotheksspezifischen | Daten des « integrierten Katalogs | bibliothek* |
| [57] - Christian Kaier (201 | 8 | 8 | https://doi.org/10.11588/ip.2017.1.35225 Christian KAIER Für wissenschaftliche | Bibliotheken | bedeutet der Aufbau publikationsunterstützender Services | bibliothek* |
| [57] - Christian Kaier (201 | 77 | 77 | Publizieren , wissenschaftliche Kommunikation , | Bibliothek | , Kooperation Expanding the library | bibliothek* |
| [57] - Christian Kaier (201 | 163 | 163 | Wissenschaftliches Publizieren als Aufgabe von | Bibliotheken | 2 Relevante Kompetenzen an der | bibliothek* |
| [57] - Christian Kaier (201 | 169 | 169 | 2 Relevante Kompetenzen an der | Bibliothek | 3 Vernetzung innerhalb der eigenen | bibliothek* |
| [57] - Christian Kaier (201 | 197 | 197 | Autor Die neue Rolle wissenschaftlicher | Bibliotheken | als Ansprechpartner von Wissenschaftlern über | bibliothek* |
| [57] - Christian Kaier (201 | 220 | 220 | eines der wichtigsten Zukunftsfelder für | Bibliotheken | wird häufig der Bereich des | bibliothek* |
| [57] - Christian Kaier (201 | 436 | 436 | Bereich des wissenschaftlichen Publizierens bietet | Bibliotheken | die Chance , sich in | bibliothek* |
| [57] - Christian Kaier (201 | 507 | 507 | kann daher die Rolle einer | Bibliothek | innerhalb ihrer Institution wesentlich aufwerten | bibliothek* |
| [57] - Christian Kaier (201 | 517 | 517 | aufwerten . Aus Sicht der | Bibliothek | kann sie außerdem dazu beitragen | bibliothek* |
| [57] - Christian Kaier (201 | 538 | 538 | Aufgaben können und sollen wissenschaftliche | Bibliotheken | dazu sinnvollerweise übernehmen ? Ursprünglich | bibliothek* |
| [57] - Christian Kaier (201 | 601 | 601 | Sinn ) hinzu , zahlreiche | Bibliotheken | verwalten Open-Access-Publikationsfonds . Während Bibliotheken | bibliothek* |
| [57] - Christian Kaier (201 | 606 | 606 | Bibliotheken verwalten Open-Access-Publikationsfonds . Während | Bibliotheken | in einer engen Definition von | bibliothek* |
| [57] - Christian Kaier (201 | 647 | 647 | die beschriebene weitere Definition von | Bibliotheken | als Kompetenzzentren des wissenschaftlichen Publizierens | bibliothek* |
| [57] - Christian Kaier (201 | 726 | 726 | Bereich des Publizierens an der | Bibliothek | ( weiter- ) entwickelt werden | bibliothek* |
| [57] - Christian Kaier (201 | 749 | 749 | Zusammenarbeit besonders erstrebenswert scheint . | Bibliotheken | verfügen über Expertise in Bereichen | bibliothek* |
| [57] - Christian Kaier (201 | 807 | 807 | eingesetzt werden , entsprechen klassischen | bibliothekarischen | Aufgaben und Ausbildungsinhalten . In | bibliothek* |
| [57] - Christian Kaier (201 | 820 | 820 | wird allerdings eine Erweiterung der | bibliothekarischen | Ausbildung auf den gesamten Lebenszyklus | bibliothek* |
| [57] - Christian Kaier (201 | 850 | 850 | 2014 ) und in amerikanischen | bibliothekarischen | Stellenanzeigen wird zunehmend Expertise in | bibliothek* |
| [57] - Christian Kaier (201 | 881 | 881 | regen eine dahingehende Neuorientierung wissenschaftlicher | Bibliotheken | und eine Reorganisation des Bibliothekspersonals | bibliothek* |
| [57] - Christian Kaier (201 | 886 | 886 | Bibliotheken und eine Reorganisation des | Bibliothekspersonals | an , um den neu | bibliothek* |
| [57] - Christian Kaier (201 | 984 | 984 | und Vertrieb kommen in der | bibliothekarischen | Ausbildung meist nicht oder nur | bibliothek* |
| [57] - Christian Kaier (201 | 1,107 | 1,107 | zu dem Ergebnis , dass | Bibliotheken | nicht nur ihre eigenen Kompetenzen | bibliothek* |
| [57] - Christian Kaier (201 | 1,136 | 1,136 | für publikationsunterstützende Angebote . Wollen | Bibliotheken | Aufgaben im Bereich des Publizierens | bibliothek* |
| [57] - Christian Kaier (201 | 1,452 | 1,452 | . Beratungs- und Informationsleistungen der | Bibliothek | müssen die für diesen Bereich | bibliothek* |
| [57] - Christian Kaier (201 | 1,527 | 1,527 | Präsentation von Forschungsleistungen . Während | Bibliotheken | bereits häufig Forschungsinformationssysteme betreiben sowie | bibliothek* |
| [57] - Christian Kaier (201 | 1,574 | 1,574 | werden häufig nicht innerhalb der | Bibliothek | beantwortet werden können . Daher | bibliothek* |
| [57] - Christian Kaier (201 | 1,654 | 1,654 | werden Schreibtrainings oft nicht von | Bibliotheken | , sondern von eigenen Serviceeinrichtungen | bibliothek* |
| [57] - Christian Kaier (201 | 1,675 | 1,675 | zu einer weiteren Schnittstelle einer | Bibliothek | werden , die Publikationsunterstützung anbieten | bibliothek* |
| [57] - Christian Kaier (201 | 1,751 | 1,751 | zu optimieren . Für die | Bibliothek | bietet sich somit – ausgehend | bibliothek* |
| [57] - Christian Kaier (201 | 1,791 | 1,791 | die über die Kernkompetenzen der | Bibliothek | hinausgehen . Als Koordinator und | bibliothek* |
| [57] - Christian Kaier (201 | 1,850 | 1,850 | erkennen lassen mag , sollten | Bibliotheken | die positiven Auswirkungen einer gemeinsamen | bibliothek* |
| [57] - Christian Kaier (201 | 2,003 | 2,003 | Konzept für Publikationsservices und der | Bibliothek | als Kommunikationsschnittstelle haben . Als | bibliothek* |
| [57] - Christian Kaier (201 | 2,042 | 2,042 | sind aus der Sicht von | Bibliotheken | sowohl Zielgruppe als auch Ressource | bibliothek* |
| [57] - Christian Kaier (201 | 2,071 | 2,071 | werden , durch den die | Bibliothek | gleichzeitig an essentielle Informationen gelangt | bibliothek* |
| [57] - Christian Kaier (201 | 2,138 | 2,138 | Publikationskanäle zu , die von | Bibliotheken | zur Verfügung gestellt werden : | bibliothek* |
| [57] - Christian Kaier (201 | 2,214 | 2,214 | anderer Form . Vielfach wird | Bibliothekaren | zunächst nicht zugetraut , in | bibliothek* |
| [57] - Christian Kaier (201 | 2,235 | 2,235 | , wohl auch , weil | Bibliotheken | mit diesem Bereich bisher nur | bibliothek* |
| [57] - Christian Kaier (201 | 2,374 | 2,374 | den einzelnen Fachbereichen und der | Bibliothek | besteht , werden Bibliotheksservices im | bibliothek* |
| [57] - Christian Kaier (201 | 2,378 | 2,378 | der Bibliothek besteht , werden | Bibliotheksservices | im deutschsprachigen Raum oft zentral | bibliothek* |
| [57] - Christian Kaier (201 | 2,546 | 2,546 | und Forschungsdatenmanagement betroffen . Wenn | Bibliotheken | den Anspruch stellen , als | bibliothek* |
| [57] - Christian Kaier (201 | 2,595 | 2,595 | Positionen erarbeitet werden . 2 | Bibliotheken | und Bibliotheksverbünde sind in solchen | bibliothek* |
| [57] - Christian Kaier (201 | 2,597 | 2,597 | werden . 2 Bibliotheken und | Bibliotheksverbünde | sind in solchen Kooperationen Partner | bibliothek* |
| [57] - Christian Kaier (201 | 2,669 | 2,669 | . Gerade diese Vernetzung der | Bibliothek | außerhalb der eigenen Institution trägt | bibliothek* |
| [57] - Christian Kaier (201 | 2,719 | 2,719 | Angebot entsprechend weiterzuentwickeln . Wissenschaftliche | Bibliotheken | erweitern ihre Angebote zunehmend auf | bibliothek* |
| [57] - Christian Kaier (201 | 2,745 | 2,745 | eine sehr lohnende Aufgabe für | Bibliotheken | sein : Sie können sich | bibliothek* |
| [57] - Christian Kaier (201 | 2,767 | 2,767 | Bereich profilieren . Dazu müssen | Bibliothekare | jedoch einerseits ihre vorhandenen Kenntnisse | bibliothek* |
| [57] - Christian Kaier (201 | 2,806 | 2,806 | Presseabteilung gewinnen , die die | bibliothekarischen | Kompetenzen und Ressourcen ergänzen . | bibliothek* |
| [57] - Christian Kaier (201 | 2,850 | 2,850 | Schlüsselfaktoren für den Erfolg von | bibliothekarischen | Angeboten zum wissenschaftlichen Publizieren . | bibliothek* |
| [57] - Christian Kaier (201 | 2,916 | 2,916 | . Eine isolierte Arbeitsweise von | Bibliotheken | ist hingegen gerade im Bereich | bibliothek* |
| [57] - Christian Kaier (201 | 3,450 | 3,450 | Publikationskompetenz als neues Aufgabengebiet für | Bibliotheken | : eine australische Fallstudie . | bibliothek* |
| [57] - Christian Kaier (201 | 3,456 | 3,456 | : eine australische Fallstudie . | Bibliothek | - Forschung und Praxis , | bibliothek* |
| [57] - Christian Kaier (201 | 3,484 | 3,484 | Publikationskompetenz als neues Tätigkeitsfeld von | Bibliotheken | . Bibliotheksdienst , 50 : | bibliothek* |
| [57] - Christian Kaier (201 | 3,486 | 3,486 | neues Tätigkeitsfeld von Bibliotheken . | Bibliotheksdienst | , 50 : 7 , | bibliothek* |
| [57] - Christian Kaier (201 | 3,922 | 3,922 | die neben Publikationsmöglichkeiten an der | Bibliothek | – Universitätsverlag und Repositorium inklusive | bibliothek* |
| [57] - Christian Kaier (201 | 3,950 | 3,950 | der Publikationsservices sind zwei ausgebildete | Bibliothekare | , die beiden anderen , | bibliothek* |
| [57] - Christian Kaier (201 | 3,979 | 3,979 | bestehender Angebote als Stabsstelle der | Bibliothek | konzipiert , auf Initiative der | bibliothek* |
| [57] - Christian Kaier (201 | 3,985 | 3,985 | konzipiert , auf Initiative der | Bibliothek | wurde in der Folge ein | bibliothek* |
| [57] - Christian Kaier (201 | 4,033 | 4,033 | von Akteuren wie Universitätsleitungen , | Bibliotheken | , Forschungsförderung und Wissenschaftlern beispielsweise | bibliothek* |
| [58] - Márton Villányi (201 | 11 | 11 | Auf der Suche nach einem | Bibliothekssystem | entschied sich die Forschungseinrichtung IST | bibliothek* |
| [58] - Márton Villányi (201 | 61 | 61 | . Trotz Herausforderungen kann die | Bibliothek | auf eine erfolgreiche Implementierung zurückblicken | bibliothek* |
| [58] - Márton Villányi (201 | 68 | 68 | eine erfolgreiche Implementierung zurückblicken . | Bibliothekssystem | , Open Source , Koha | bibliothek* |
| [58] - Márton Villányi (201 | 76 | 76 | Source , Koha , Wissenschaftliche | Bibliothek | IST Austria was looking for | bibliothek* |
| [58] - Márton Villányi (201 | 211 | 211 | Goethe Institute für eine neue | Bibliothekssoftware | hat sich auch im deutschsprachigen | bibliothek* |
| [58] - Márton Villányi (201 | 238 | 238 | Die ursprüngliche Version dieses integrierten | Bibliothekssystems | wurde im Jahr 1999 in | bibliothek* |
| [58] - Márton Villányi (201 | 274 | 274 | Bestands und der Ausleihe , | Bibliotheksstatistiken | und vieles mehr . Auch | bibliothek* |
| [58] - Márton Villányi (201 | 367 | 367 | Koha . Die meisten wissenschaftlichen | Bibliotheken | Österreichs legten sich schon vor | bibliothek* |
| [58] - Márton Villányi (201 | 386 | 386 | dessen Betreuung durch den Österreichischen | Bibliothekenverbund | ( OBVSG ) fest . | bibliothek* |
| [58] - Márton Villányi (201 | 504 | 504 | – und somit auch ihre | Bibliothek | – erst 2009 eröffnet wurde | bibliothek* |
| [58] - Márton Villányi (201 | 532 | 532 | neueren Entwicklungen des modernen wissenschaftlichen | Bibliothekswesens | . So wurden Zeitschriften von | bibliothek* |
| [58] - Márton Villányi (201 | 547 | 547 | angeboten . Gerne hätte die | Bibliothek | auch bei Büchern eine ähnliche | bibliothek* |
| [58] - Márton Villányi (201 | 638 | 638 | nach einem passenden , integrierten | Bibliothekssystem | stellte sich erst nach ein | bibliothek* |
| [58] - Márton Villányi (201 | 678 | 678 | sich dem Großteil der wissenschaftlichen | Bibliotheken | Österreichs anzuschließen und Verbundmitglied zu | bibliothek* |
| [58] - Márton Villányi (201 | 780 | 780 | die des GBV ( Gemeinsamer | Bibliotheken | Verbund ) oder der Library | bibliothek* |
| [58] - Márton Villányi (201 | 837 | 837 | ist . Nichtsdestotrotz ist die | Bibliothek | längerfristig an einer Beteiligung in | bibliothek* |
| [58] - Márton Villányi (201 | 853 | 853 | Dazu müssten jedoch auch andere | Bibliothekssysteme | unterstützt werden . Die Nachteile | bibliothek* |
| [58] - Márton Villányi (201 | 924 | 924 | die Aufmerksamkeit auf das freie | Bibliothekssystem | Koha , welches die wesentlichen | bibliothek* |
| [58] - Márton Villányi (201 | 970 | 970 | Benutzer , als auch vom | Bibliothekspersonal | gewünscht . Wichtig war auch | bibliothek* |
| [58] - Márton Villányi (201 | 1,064 | 1,064 | OPAC lässt sich auch vom | Bibliothekspersonal | ohne umfangreiche Vorkenntnisse auf besondere | bibliothek* |
| [58] - Márton Villányi (201 | 1,150 | 1,150 | entsprechen ebenfalls den Ansprüchen der | Bibliothek | . Im Fall des IST | bibliothek* |
| [58] - Márton Villányi (201 | 1,190 | 1,190 | zum Beispiel zur Generierung von | Bibliotheksstatistiken | werden am IST Austria nur | bibliothek* |
| [58] - Márton Villányi (201 | 1,213 | 1,213 | Koha wird weltweit von tausenden | Bibliotheken | eingesetzt . Oft sind es | bibliothek* |
| [58] - Márton Villányi (201 | 1,226 | 1,226 | , nicht selten aber öffentliche | Bibliotheken | mit einem breiten Netz an | bibliothek* |
| [58] - Márton Villányi (201 | 1,236 | 1,236 | an Zweigstellen . Auch wissenschaftliche | Bibliotheken | gehören in einer großen Zahl | bibliothek* |
| [58] - Márton Villányi (201 | 1,294 | 1,294 | gibt die weltweite Verbreitung dieses | Bibliothekssystems | der Bibliothek des IST Austria | bibliothek* |
| [58] - Márton Villányi (201 | 1,296 | 1,296 | weltweite Verbreitung dieses Bibliothekssystems der | Bibliothek | des IST Austria eine gewisse | bibliothek* |
| [58] - Márton Villányi (201 | 1,401 | 1,401 | durch die Zusammenarbeit mit anderen | Bibliotheken | und der Gemeinschaft hohe Synergieeffekte | bibliothek* |
| [58] - Márton Villányi (201 | 1,414 | 1,414 | Implementierung von Koha an der | Bibliothek | des IST Austria erfolgte schrittweise | bibliothek* |
| [58] - Márton Villányi (201 | 1,426 | 1,426 | Hervorzuheben ist , dass die | Bibliothek | gegenwärtig von drei Personen betrieben | bibliothek* |
| [58] - Márton Villányi (201 | 1,457 | 1,457 | erwähnt werden , dass die | Bibliothek | auf die externe Unterstützung einer | bibliothek* |
| [58] - Márton Villányi (201 | 1,527 | 1,527 | Anbieter für die Betreuung des | Bibliothekssystems | . Mit etwas IT-Know-How kann | bibliothek* |
| [58] - Márton Villányi (201 | 1,566 | 1,566 | bei der Implementierung einer neuen | Bibliothekssoftware | war das Fehlen einer alten | bibliothek* |
| [58] - Márton Villányi (201 | 1,587 | 1,587 | Koha noch ohne ein integriertes | Bibliothekssystem | ausgekommen . Für den Katalog | bibliothek* |
| [58] - Márton Villányi (201 | 1,700 | 1,700 | installiert . Zunächst erhielt die | Bibliothek | Zugang zu einer Testversion , | bibliothek* |
| [58] - Márton Villányi (201 | 1,817 | 1,817 | wurden – nach Vorgaben der | Bibliothek | – zum Teil von der | bibliothek* |
| [58] - Márton Villányi (201 | 1,845 | 1,845 | zum Teil aber auch vom | Bibliothekspersonal | selbst durchgeführt ( Vergabe von | bibliothek* |
| [58] - Márton Villányi (201 | 1,864 | 1,864 | ) . Zuerst erhielt die | Bibliothek | Online-Schulungen von der Supportfirma und | bibliothek* |
| [58] - Márton Villányi (201 | 1,883 | 1,883 | und Benutzer . Bücher der | Bibliothek | wurden schon vor der Systemeinführung | bibliothek* |
| [58] - Márton Villányi (201 | 1,899 | 1,899 | selbst ausgeliehen . Aus der | Bibliothek | mitgenommene Bücher mussten in eine | bibliothek* |
| [58] - Márton Villányi (201 | 1,933 | 1,933 | und permanenten Öffnung wollte die | Bibliothek | beibehalten . Die Implementierung einer | bibliothek* |
| [58] - Márton Villányi (201 | 1,992 | 1,992 | Ausleihen pro Tag konnte die | Bibliothek | sofort auf anfängliche Fehler reagieren | bibliothek* |
| [58] - Márton Villányi (201 | 2,042 | 2,042 | gebracht wurden , aktiviert die | Bibliothek | laufend für sinnvoll erachtete Zusatzdienste | bibliothek* |
| [58] - Márton Villányi (201 | 2,051 | 2,051 | erachtete Zusatzdienste . Nachdem die | Bibliothek | in den ersten paar Monaten | bibliothek* |
| [58] - Márton Villányi (201 | 2,136 | 2,136 | einem weiteren Schritt spielte die | Bibliothek | bestehende und hinzugekommene E-Book-Sammlungen als | bibliothek* |
| [58] - Márton Villányi (201 | 2,328 | 2,328 | Beseitigung von Fehlern informierte die | Bibliothek | ihre Benutzerinnen und Benutzer über | bibliothek* |
| [58] - Márton Villányi (201 | 2,396 | 2,396 | anbietet , konnten von der | Bibliothek | nur rudimentär getestet werden . | bibliothek* |
| [58] - Márton Villányi (201 | 2,443 | 2,443 | die maßgeschneidert für die eigene | Bibliothek | einzurichten sind . Anleitungen dazu | bibliothek* |
| [58] - Márton Villányi (201 | 2,460 | 2,460 | Umsetzung ist auch für unerfahrenes | Bibliothekspersonal | durchführbar . An der Bibliothek | bibliothek* |
| [58] - Márton Villányi (201 | 2,465 | 2,465 | Bibliothekspersonal durchführbar . An der | Bibliothek | des IST Austria werden solche | bibliothek* |
| [58] - Márton Villányi (201 | 2,482 | 2,482 | verwendet . Außerdem nutzt die | Bibliothek | solche Reports zur Gegenüberstellung des | bibliothek* |
| [58] - Márton Villányi (201 | 2,526 | 2,526 | zu Buchhändlern befindet sich die | Bibliothek | des IST Austria in der | bibliothek* |
| [58] - Márton Villányi (201 | 2,540 | 2,540 | Werkzeugs . Dies soll der | Bibliothek | erlauben , Bestellungen nicht wie | bibliothek* |
| [58] - Márton Villányi (201 | 2,598 | 2,598 | Der Informationsdienstleister EBSCO und die | Bibliothek | des IST Austria arbeiten seit | bibliothek* |
| [58] - Márton Villányi (201 | 2,648 | 2,648 | Ein weiteres mittelfristiges Projekt der | Bibliothek | ist der Betrieb von Koha | bibliothek* |
| [58] - Márton Villányi (201 | 2,677 | 2,677 | von lizenzierten E-Journals . Die | Bibliothek | des IST Austria wartet momentan | bibliothek* |
| [58] - Márton Villányi (201 | 2,713 | 2,713 | Entscheidung für ein Open Source | Bibliothekssystems | war nicht selbstverständlich , aus | bibliothek* |
| [58] - Márton Villányi (201 | 2,791 | 2,791 | vergleichsweise geringen Kosten . Das | Bibliothekspersonal | konnte sich – zum Teil | bibliothek* |
| [58] - Márton Villányi (201 | 2,818 | 2,818 | Benutzer dürften mit dem neuen | Bibliothekssystem | ebenfalls zufrieden sein , Beschwerden | bibliothek* |
| [58] - Márton Villányi (201 | 2,837 | 2,837 | Die wachsende Zahl von wissenschaftlichen | Bibliotheken | , die sich – auch | bibliothek* |
| [58] - Márton Villányi (201 | 2,855 | 2,855 | , bestätigt den Weg der | Bibliothek | . Eine weitere Vernetzung und | bibliothek* |
| [58] - Márton Villányi (201 | 2,971 | 2,971 | Márton 2015 : Open Source | Bibliothekssysteme | als Alternative ? Erfahrungen am | bibliothek* |
| [58] - Márton Villányi (201 | 3,011 | 3,011 | Betriebs- und Entwicklungsmodelle für das | Bibliothekssystem | Koha , [ online ] | bibliothek* |
| [58] - Márton Villányi (201 | 3,124 | 3,124 | Universität Wien und absolvierte die | bibliothekarische | Grundausbildung an der Österreichischen Nationalbibliothek | bibliothek* |
| [58] - Márton Villányi (201 | 3,176 | 3,176 | ( IST Austria ) als | Bibliothekar | , wo er neben diversen | bibliothek* |
| [58] - Márton Villányi (201 | 3,187 | 3,187 | anderen Tätigkeiten auch mit dem | Bibliothekssystem | Koha betraut ist . Informationspraxis | bibliothek* |
| [59] - Daniel Hürlimann, Al | 567 | 567 | regelmässig konsultieren , und auch | Bibliotheken | werden unabhängig davon weiterhin das | bibliothek* |
| [59] - Daniel Hürlimann, Al | 1,219 | 1,219 | einmal die Abonnementgebühr von den | Bibliotheken | , und zusätzlich die Artikel-Gebühren | bibliothek* |
| [59] - Daniel Hürlimann, Al | 1,256 | 1,256 | , die vor allem von | Bibliotheken | stark kritisiert wird , unlängst | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 29 | 29 | von Zielgruppen bei der Weiterentwicklung | bibliothekarischer | Dienstleistungen . Zu diesem Zweck | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 359 | 359 | Fokusgruppe Quellen Autoren Für wissenschaftliche | Bibliotheken | ist schon lange klar , | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 459 | 459 | und entsprechend zur Wahrnehmung der | Bibliothek | als wichtigem Element der Informationsinfrastruktur | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 477 | 477 | zunehmend geforderten Legitimation von wissenschaftlichen | Bibliotheken | Rechnung getragen werden , belegt | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 3,699 | 3,699 | „ Multiplikatoren “ werden primär | Bibliotheken | bezeichnet , für die ZB | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 6,046 | 6,046 | ggf . auch von den | Bibliotheken | eingekauft werden müsse . Die | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 6,137 | 6,137 | Angebote widerspiegeln müsse . Traditionelle | Bibliotheksführungen | seien wenig zeitgemäß und gehörten | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 6,272 | 6,272 | die vielen bereits in den | Bibliotheken | existierenden Tutorials und Anleitungen ( | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 6,289 | 6,289 | ) gesammelt und dann in | bibliothekarischen | Arbeitsgruppen bearbeitet werden . ZB | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 7,642 | 7,642 | dessen , was eine lokale | Bibliothek | leisten könne . Gerade im | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 8,409 | 8,409 | für elektronische Ressourcen in die | Bibliothekssysteme | beachtet werden . Ebenso sollten | bibliothek* |
| [60] - Fabian Gail, Mark Ve | 9,696 | 9,696 | MED " . In : | Bibliotheksdienst | Band 48 , 2014 , | bibliothek* |
| [61] - Christian Hauschke ( | 34 | 34 | Informationsverhalten zu speichern . 4753 | Bibliothekswebseiten | wurden im Rahmen dieser Untersuchung | bibliothek* |
| [61] - Christian Hauschke ( | 92 | 92 | Webseiten verwendet . Datenschutz ; | Bibliothekswebseite | ; Third-Party-Elemente Embedding of Third | bibliothek* |
| [61] - Christian Hauschke ( | 718 | 718 | Demgegenüber stehen öffentliche und wissenschaftliche | Bibliotheken | , die sich laut Code | bibliothek* |
| [61] - Christian Hauschke ( | 797 | 797 | zur Verfügung . " ( | Bibliothek | und Information Deutschland , 2007 | bibliothek* |
| [61] - Christian Hauschke ( | 813 | 813 | von der Speicherung durch die | Bibliothek | und die Weitergabe an Behörden | bibliothek* |
| [61] - Christian Hauschke ( | 831 | 831 | , sind die Daten der | Bibliotheksnutzerinnen | und –nutzer ebenso schutzbedürftig gegenüber | bibliothek* |
| [61] - Christian Hauschke ( | 857 | 857 | , ob die Webseiten deutscher | Bibliotheken | durch TPE die Sammlung von | bibliothek* |
| [61] - Christian Hauschke ( | 873 | 873 | . Lobid.org stellt Informationen über | bibliothekarische | Einrichtungen als Linked Data über | bibliothek* |
| [61] - Christian Hauschke ( | 902 | 902 | über eine große Zahl von | Bibliotheken | zu tätigen . Dank der | bibliothek* |
| [61] - Christian Hauschke ( | 926 | 926 | mit URLs von Webseiten deutscher | Bibliotheken | zusammengestellt werden . Mit dieser | bibliothek* |
| [61] - Christian Hauschke ( | 1,123 | 1,123 | alle Adressen sind eindeutig einer | Bibliothek | zuzuordnen . http://polizei.sachsen.de führt zum | bibliothek* |
| [61] - Christian Hauschke ( | 1,142 | 1,142 | zahlreiche , gerade kleinere öffentliche | Bibliotheken | verweisen auf die Webseiten ihrer | bibliothek* |
| [61] - Christian Hauschke ( | 1,164 | 1,164 | TPE auf Unterseiten , im | Bibliothekskatalog | oder im Open-Access-Server verwendet werden | bibliothek* |
| [61] - Christian Hauschke ( | 1,299 | 1,299 | Tabelle 1 - Cookies in | Bibliothekswebseiten | Insgesamt wurden von den untersuchten | bibliothek* |
| [61] - Christian Hauschke ( | 1,593 | 1,593 | TPE verhindert werden kann . | Bibliotheken | können durch einfache Maßnahmen viel | bibliothek* |
| [61] - Christian Hauschke ( | 1,776 | 1,776 | lässt sich nahtlos auf das | Bibliothekswesen | übertragen : „ Es ist | bibliothek* |
| [61] - Christian Hauschke ( | 1,858 | 1,858 | , sich der Verpflichtungen des | Bibliothekswesens | hinsichtlich der informationellen Selbstbestimmung ihrer | bibliothek* |
| [61] - Christian Hauschke ( | 1,903 | 1,903 | , Open-Access-Repositorien und anderen von | Bibliotheken | lizenzierten oder selbst angebotenen Diensten | bibliothek* |
| [61] - Christian Hauschke ( | 1,922 | 1,922 | letztmalig am 19.08.2016 aufgerufen . | Bibliothek | und Information Deutschland ( 2007 | bibliothek* |
| [61] - Christian Hauschke ( | 1,933 | 1,933 | ) : Ethische Grundsätze der | Bibliotheks- | und Informationsberufe [ online ] | bibliothek* |
| [61] - Christian Hauschke ( | 2,157 | 2,157 | URLs von Webseiten mit Typ | Bibliothek | aus Lobid.org . URL : | bibliothek* |
| [61] - Christian Hauschke ( | 2,256 | 2,256 | Auf dem Weg zur demokratischen | Bibliothek | . Berlin , Freie Universität | bibliothek* |
| [61] - Christian Hauschke ( | 2,268 | 2,268 | URL : http://demokratische-bibliothek.de/wp-content/uploads/2014/06/Masterarbeit_Jobmann_Zschau_DemPaed_.pdf Christian HAUSCHKE | Bibliothek | der Hochschule Hannover Ricklinger Stadtweg | bibliothek* |
| [61] - Christian Hauschke ( | 2,476 | 2,476 | christian.hauschke at hs-hannover dot de | Bibliothek | der Hochschule Hannover ↩ Informationspraxis | bibliothek* |
| [62] - Beat Mattmann (2016) | 440 | 440 | die möglichen Beteiligten ( also | Bibliotheken | , Archive , Verlage usw | bibliothek* |
| [62] - Beat Mattmann (2016) | 509 | 509 | . Das betrifft neben kleineren | Bibliotheken | und Archiven insbesondere auch bibliothekarische | bibliothek* |
| [62] - Beat Mattmann (2016) | 514 | 514 | Bibliotheken und Archiven insbesondere auch | bibliothekarische | Sondersammlungen , deren Archivalien ( | bibliothek* |
| [62] - Beat Mattmann (2016) | 937 | 937 | heute , neben den konventionellen | Bibliotheks- | und Archivkatalogen , viele Portale | bibliothek* |
| [62] - Beat Mattmann (2016) | 1,024 | 1,024 | : Wo bei den konventionellen | Bibliotheks- | und Archivkatalogen ein Trend hin | bibliothek* |
| [62] - Beat Mattmann (2016) | 1,424 | 1,424 | oder durch interessierte Archive und | Bibliotheken | aufgeteilt oder verkauft . Auch | bibliothek* |
| [62] - Beat Mattmann (2016) | 1,881 | 1,881 | dieser Kosten und der in | Bibliotheken | und Archiven notorisch begrenzten Ressourcen | bibliothek* |
| [62] - Beat Mattmann (2016) | 2,258 | 2,258 | Umstand , den der Berufsverband | Bibliothek | Information Schweiz ( BIS ) | bibliothek* |
| [62] - Beat Mattmann (2016) | 2,660 | 2,660 | eine eher kritische Haltung von | Bibliotheken | und Archiven gegenüber der digitalen | bibliothek* |
| [62] - Beat Mattmann (2016) | 2,704 | 2,704 | den letzten Jahren von vielen | Bibliotheken | und Archiven lanciert wurden . | bibliothek* |
| [62] - Beat Mattmann (2016) | 3,275 | 3,275 | . ) : Die Digitale | Bibliothek | und ihr Recht – ein | bibliothek* |
| [62] - Beat Mattmann (2016) | 3,498 | 3,498 | Hg . ) : Die | Bibliothek | in der Zukunft . Innsbruck | bibliothek* |
| [62] - Beat Mattmann (2016) | 3,522 | 3,522 | Die Bedeutung des Urheberrechts im | Bibliothekswesen | – Grundlagen . In : | bibliothek* |
| [62] - Beat Mattmann (2016) | 3,542 | 3,542 | Hg . ) : Digitale | Bibliothek | und Recht – Bibliothèques numériques | bibliothek* |
| [62] - Beat Mattmann (2016) | 3,586 | 3,586 | ) : Rafael Ball tritt | Bibliotheks-Debatte | los . Digithek-Blog . Online | bibliothek* |
| [63] - Karsten Schuldt (201 | 9 | 9 | Karsten SCHULDT Die Geschichte von | Bibliotheken | kann helfen , ihren heutigen | bibliothek* |
| [63] - Karsten Schuldt (201 | 27 | 27 | geben , welche Entwicklungen der | Bibliotheken | realistisch sind . Anhand eines | bibliothek* |
| [63] - Karsten Schuldt (201 | 58 | 58 | solche Rekonstruktion der Geschichte von | Bibliotheken | und bibliothekarischen Infrastrukturen mit teilweise | bibliothek* |
| [63] - Karsten Schuldt (201 | 60 | 60 | der Geschichte von Bibliotheken und | bibliothekarischen | Infrastrukturen mit teilweise wenig Aufwand | bibliothek* |
| [63] - Karsten Schuldt (201 | 102 | 102 | dass dies auch für andere | Bibliothekstypen | gelten kann . Archivrecherche , | bibliothek* |
| [63] - Karsten Schuldt (201 | 108 | 108 | gelten kann . Archivrecherche , | Bibliotheksgeschichte | , Volksschulbibliotheken , St . | bibliothek* |
| [63] - Karsten Schuldt (201 | 240 | 240 | zum Archiv 1.1 Auftrag der | Bibliothekskommission | und Fragen zum ' Schulbibliotheksartikel | bibliothek* |
| [63] - Karsten Schuldt (201 | 311 | 311 | 6.1 Quellen 6.2 Archivmaterialien Autor | Bibliotheken | sind heute sehr darauf fixiert | bibliothek* |
| [63] - Karsten Schuldt (201 | 330 | 330 | zu gestalten . Diskussionen in | bibliothekarischen | Medien drehen sich oft darum | bibliothek* |
| [63] - Karsten Schuldt (201 | 341 | 341 | , den jetzigen Zustand der | Bibliotheken | zu beschreiben und davon ausgehend | bibliothek* |
| [63] - Karsten Schuldt (201 | 398 | 398 | kann zu verstehen , warum | Bibliotheken | heute so sind , wie | bibliothek* |
| [63] - Karsten Schuldt (201 | 457 | 457 | „ Umfeldes “ von bestimmten | Bibliotheken | direkt zu einer Veränderung der | bibliothek* |
| [63] - Karsten Schuldt (201 | 463 | 463 | direkt zu einer Veränderung der | Bibliotheken | führen muss . Der folgend | bibliothek* |
| [63] - Karsten Schuldt (201 | 516 | 516 | , dass die Archive und | Bibliotheken | mit Sammelauftrag ( in diesem | bibliothek* |
| [63] - Karsten Schuldt (201 | 559 | 559 | , die grundlegenden Strukturen einer | Bibliotheksgeschichte | ( hier der Volksschulbibliotheken des | bibliothek* |
| [63] - Karsten Schuldt (201 | 584 | 584 | die jetzige Situation der untersuchten | Bibliotheken | zu verstehen und darauf aufbauend | bibliothek* |
| [63] - Karsten Schuldt (201 | 609 | 609 | Vorschläge weichen immens von der | bibliothekarischen | Literatur zu Schulbibliotheken ab ( | bibliothek* |
| [63] - Karsten Schuldt (201 | 623 | 623 | Schweizerische Arbeitsgemeinschaft der allgemeinen öffentlichen | Bibliotheken | 2014 , Holderried & Lücke | bibliothek* |
| [63] - Karsten Schuldt (201 | 634 | 634 | 2012 sowie die Darstellung der | bibliothekarischen | Vorstellungen von Schulbibliotheken in Schuldt | bibliothek* |
| [63] - Karsten Schuldt (201 | 657 | 657 | aus der Geschichte der untersuchten | Bibliotheken | begründen – und wären ohne | bibliothek* |
| [63] - Karsten Schuldt (201 | 679 | 679 | dafür , die Geschichte der | Bibliotheken | als rein „ interessantes “ | bibliothek* |
| [63] - Karsten Schuldt (201 | 708 | 708 | Diskussion über die Zukunft der | Bibliotheken | einzubeziehen . Allerdings ist dazu | bibliothek* |
| [63] - Karsten Schuldt (201 | 733 | 733 | sollte , aber in der | bibliothekarischen | Diskussion , in der eher | bibliothek* |
| [63] - Karsten Schuldt (201 | 742 | 742 | der eher historische Behauptungen über | Bibliotheken | vorzuherrschen scheinen , oft etwas | bibliothek* |
| [63] - Karsten Schuldt (201 | 772 | 772 | dennoch entwickeln sich Institutionen wie | Bibliotheken | in Kontinuitätslinien , die ihre | bibliothek* |
| [63] - Karsten Schuldt (201 | 833 | 833 | anders gesagt : Auch für | Bibliotheken | gilt , dass die Zukunft | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,003 | 1,003 | . ) Auftraggeber war die | Bibliothekskommission | St . Gallen , die | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,028 | 1,028 | – Förderung und Weiterentwicklung des | Bibliothekssystems | im Kanton – für Volksschulbibliotheken | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,042 | 1,042 | . Im Gegensatz zu anderen | Bibliothekstypen | waren diese schwer für die | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,051 | 1,051 | für die Arbeit an der | Bibliotheksstrategie | des Kantons zu gewinnen gewesen | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,082 | 1,082 | war bekannt , wie viele | Bibliotheken | es in den Volksschulen des | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,131 | 1,131 | darauf verwiesen , dass die | Bibliotheken | im Volksschulgesetz erwähnt werden . | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,182 | 1,182 | , in drei Kantonen im | Bibliotheksgesetz | , zudem existieren in vier | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,214 | 1,214 | : „ Art 25 : | Bibliothek | 1 Die Schulgemeinde unterhält eine | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,220 | 1,220 | 1 Die Schulgemeinde unterhält eine | Bibliothek | für Schülerinnen und Schüler sowie | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,227 | 1,227 | Schülerinnen und Schüler sowie eine | Bibliothek | für Lehrpersonen . 2 Die | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,233 | 1,233 | für Lehrpersonen . 2 Die | Bibliothek | für Schülerinnen und Schüler kann | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,325 | 1,325 | . fünf Schulen nur eine | Bibliothek | eröffnet und damit das Gesetz | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,342 | 1,342 | ist zudem die Differenzierung von | Bibliotheken | für Schülerinnen und Schüler auf | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,361 | 1,361 | . Dies ist in der | bibliothekarischen | Literatur zu Schulbibliotheken nicht vorgesehen | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,388 | 1,388 | ) Die Formulierung , dass | Bibliotheken | auch mit anderen Einrichtungen zusammen | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,416 | 1,416 | eine Lösung , die für | Bibliothekarinnen | und Bibliothekare gewiss naheliegt und | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,418 | 1,418 | , die für Bibliothekarinnen und | Bibliothekare | gewiss naheliegt und in Kombinierten | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,651 | 1,651 | in seiner Ausbildung – Studium | Bibliothekswissenschaft | und Gender Studies – Archive | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,721 | 1,721 | jemanden , der sonst in | Bibliotheken | arbeitet , ungewöhnlich erschien , | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,740 | 1,740 | Archive haben – wie auch | Bibliotheken | – eigene Regeln und soziale | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,772 | 1,772 | im Vergleich zur Arbeit in | Bibliotheken | , irritierend ähnlich , aber | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,819 | 1,819 | heute genauso selbstverständlich wie in | Bibliotheken | , Online zugänglich . Bekanntlich | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,834 | 1,834 | Provenienzorientiert , im Gegensatz zu | Bibliothekskatalogen | mit ihrer Orientierung auf die | bibliothek* |
| [63] - Karsten Schuldt (201 | 1,993 | 1,993 | war bis dahin weder der | Bibliothekskommission | noch dem Autor bekannt . | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,112 | 2,112 | Eine solche Anmeldeprozedur ist bei | Bibliotheken | im Allgemeinen erst für historische | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,149 | 2,149 | einen Unterschied zwischen Archiv und | Bibliothek | . Interessant war die Reaktion | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,198 | 2,198 | Auch dieses Vorgehen wäre für | Bibliotheken | ungewöhnlich und kann gewiss etwas | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,423 | 2,423 | es – im Gegensatz zu | Bibliotheken | – auch nicht viele Personen | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,523 | 2,523 | auch von der Arbeit in | Bibliotheken | . Zusätzlich zu den vorbestellten | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,732 | 2,732 | aber doch anders als in | Bibliotheken | . Moderne Archive sind an | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,818 | 2,818 | grossen Aufwand zur Geschichte von | Bibliotheken | und bibliothekarischen Institutionen zu finden | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,820 | 2,820 | zur Geschichte von Bibliotheken und | bibliothekarischen | Institutionen zu finden ist . | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,884 | 2,884 | weitergehende Rekonstruktionen der Geschichte von | Bibliotheken | ermöglichen würden . Der erste | bibliothek* |
| [63] - Karsten Schuldt (201 | 2,908 | 2,908 | die Formulierung des Artikels zu | Bibliotheken | im Volksschulgesetz von 1983 . | bibliothek* |
| [63] - Karsten Schuldt (201 | 3,380 | 3,380 | Schulgemeinde verpflichtet wurde , eine | Bibliothek | zu führen . Ansonsten wurde | bibliothek* |
| [63] - Karsten Schuldt (201 | 3,643 | 3,643 | hohen Anteil an Sachliteratur , | bibliothekarischer | Leitung , d.h . bibliothekarischem | bibliothek* |
| [63] - Karsten Schuldt (201 | 3,648 | 3,648 | bibliothekarischer Leitung , d.h . | bibliothekarischem | Personal , und aktuellen Medienformen | bibliothek* |
| [63] - Karsten Schuldt (201 | 3,780 | 3,780 | Schweizerische Arbeitsgemeinschaft der allgemeinen öffentlichen | Bibliotheken | 2014 ) oder der Expertenkommission | bibliothek* |
| [63] - Karsten Schuldt (201 | 3,786 | 3,786 | 2014 ) oder der Expertenkommission | Bibliothek | und Schule im dbv dargelegt | bibliothek* |
| [63] - Karsten Schuldt (201 | 4,192 | 4,192 | Arbeit in den Jahresberichten der | Bibliothek | vor . Erwähnungen , Vernehmlassungen | bibliothek* |
| [63] - Karsten Schuldt (201 | 4,827 | 4,827 | 1969 , allerdings mit mehr | Bibliotheken | , die als Freihand aufgestellt | bibliothek* |
| [63] - Karsten Schuldt (201 | 4,845 | 4,845 | Ton gehalten , der alle | Bibliotheken | , die nicht dem Verständnis | bibliothek* |
| [63] - Karsten Schuldt (201 | 4,853 | 4,853 | nicht dem Verständnis „ moderner | Bibliotheken | “ entsprechen , vorwirft , | bibliothek* |
| [63] - Karsten Schuldt (201 | 4,944 | 4,944 | Schweizerischen Arbeitsgemeinschaft der allgemeinen öffentlichen | Bibliotheken | ( 1 . Auflage , | bibliothek* |
| [63] - Karsten Schuldt (201 | 5,097 | 5,097 | zur Einführung von EDV in | Bibliotheken | , ersetzt worden zu sein | bibliothek* |
| [63] - Karsten Schuldt (201 | 5,381 | 5,381 | herauszugeben oder das Verständnis der | Bibliotheken | als Lesebibliotheken , die in | bibliothek* |
| [63] - Karsten Schuldt (201 | 5,614 | 5,614 | Dinge , nicht nur für | Bibliotheken | , verwendet werden . 1983 | bibliothek* |
| [63] - Karsten Schuldt (201 | 5,705 | 5,705 | nachweisen ; vielmehr sind die | Bibliotheken | auch heute gut finanzierte , | bibliothek* |
| [63] - Karsten Schuldt (201 | 5,848 | 5,848 | Für die weitere Arbeit der | Bibliothekskommission | scheint dieses Wissen hilfreich . | bibliothek* |
| [63] - Karsten Schuldt (201 | 5,879 | 5,879 | auch den Status Quo von | Bibliotheken | betreffen , die vorhandenen Archive | bibliothek* |
| [63] - Karsten Schuldt (201 | 5,897 | 5,897 | Idealfall die lokale Geschichte der | Bibliothekssysteme | zu rekonstruieren . Diese Arbeit | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,104 | 6,104 | die Ergebnisse nur auf diesen | Bibliothekstyp | zu beziehen . Sicherlich ist | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,150 | 6,150 | Bundesarchiv Unterlagen des ehemaligen Deutschen | Bibliotheksinstituts | lagern , im Landesarchiv Berlin | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,170 | 6,170 | Zürich die Unterlagen der Kantonalen | Bibliothekskommission | . Weitere Recherchen werden viel | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,182 | 6,182 | Materialien für unterschiedliche Einrichtungen und | Bibliothekstypen | aufzeigen . Insoweit gibt es | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,208 | 6,208 | St . Gallen alleine ihrem | Bibliothekstyp | Schulbibliothek zuzuschreiben . Es gibt | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,241 | 6,241 | das dies deshalb für andere | Bibliothekstypen | , die sich in agileren | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,280 | 6,280 | wie die Gesellschaft . Wenn | Bibliotheken | immer den Änderungen ihres Umfeldes | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,309 | 6,309 | nicht so , wie die | bibliothekarische | Literatur vermutete . Wenn dies | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,330 | 6,330 | , das dies bei anderen | Bibliotheken | und Bibliothekstypen nicht ebenso zu | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,332 | 6,332 | dies bei anderen Bibliotheken und | Bibliothekstypen | nicht ebenso zu finden sein | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,368 | 6,368 | die offenbar keinen Anschluss an | bibliothekarische | Diskussionen suchen , nur sichtbarer | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,377 | 6,377 | nur sichtbarer als in anderen | Bibliotheken | . Dora , Cornel ( | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,732 | 6,732 | Schweizerische Arbeitsgemeinschaft der allgemeinen öffentlichen | Bibliotheken | ( 2014 ) . Richtlinien | bibliothek* |
| [63] - Karsten Schuldt (201 | 6,741 | 6,741 | . Richtlinien für Schulbibliotheken : | Bibliotheken | , Mediotheken , Informationszentren an | bibliothek* |
| [63] - Karsten Schuldt (201 | 7,030 | 7,030 | Begründung . Die Differenzierung in | Bibliotheken | für Lehrende und Bibliotheken für | bibliothek* |
| [63] - Karsten Schuldt (201 | 7,034 | 7,034 | in Bibliotheken für Lehrende und | Bibliotheken | für Lernende fand sich in | bibliothek* |
| [63] - Karsten Schuldt (201 | 7,070 | 7,070 | den Unterschieden von Archiven und | Bibliotheken | gewesen . ↩ Der Autor | bibliothek* |
| [63] - Karsten Schuldt (201 | 7,097 | 7,097 | ( 1973-2000 ) sowie andere | bibliothekarische | Zeitschriften der 1960er Jahre bis | bibliothek* |
| [64] - Daniel Beucke, Arvid | 40 | 40 | Bibcast , eine Webcast-Serie zu | bibliothekarisch | relevanten Themen statt . Aus | bibliothek* |
| [64] - Daniel Beucke, Arvid | 55 | 55 | , abgelehnten Einreichungen für den | Bibliothekskongress | ein alternatives Forum zu bieten | bibliothek* |
| [64] - Daniel Beucke, Arvid | 115 | 115 | . Bibcast , Webcast , | Bibliothekartag | , Bibliothekskongress , Erfahrungsbericht Bibcast | bibliothek* |
| [64] - Daniel Beucke, Arvid | 117 | 117 | , Webcast , Bibliothekartag , | Bibliothekskongress | , Erfahrungsbericht Bibcast is a | bibliothek* |
| [64] - Daniel Beucke, Arvid | 159 | 159 | Library Congress in Germany ( | Bibliothekskongress | ) . The flexible and | bibliothek* |
| [64] - Daniel Beucke, Arvid | 190 | 190 | . bibcast , webcast , | Bibliothekartag | , library congress , report | bibliothek* |
| [64] - Daniel Beucke, Arvid | 218 | 218 | bei der zentralen Fortbildungsveranstaltung des | Bibliothekswesens | , dem Bibliothekartag bzw . | bibliothek* |
| [64] - Daniel Beucke, Arvid | 221 | 221 | Fortbildungsveranstaltung des Bibliothekswesens , dem | Bibliothekartag | bzw . dem Bibliothekskongress , | bibliothek* |
| [64] - Daniel Beucke, Arvid | 225 | 225 | dem Bibliothekartag bzw . dem | Bibliothekskongress | , zahlreiche Beiträge durch das | bibliothek* |
| [64] - Daniel Beucke, Arvid | 258 | 258 | ( die Auswahlkritierien für den | Bibliothekskongress | 2016 finden sich im Call | bibliothek* |
| [64] - Daniel Beucke, Arvid | 404 | 404 | Ablehnungen der eingereichten Beiträge zum | Bibliothekskongress | 2016 versendet wurden , kam | bibliothek* |
| [64] - Daniel Beucke, Arvid | 486 | 486 | In der Woche vor dem | Bibliothekskongress | , vom 7 . bis | bibliothek* |
| [64] - Daniel Beucke, Arvid | 636 | 636 | , dem offiziellen Hashtag des | Bibliothekskongresses | ) fanden sich schnell Interessierte | bibliothek* |
| [64] - Daniel Beucke, Arvid | 720 | 720 | positive Reaktion der Organisatoren des | Bibliothekskongresses | hat zur Sichtbarkeit der Aktion | bibliothek* |
| [64] - Daniel Beucke, Arvid | 735 | 735 | Heinz-Jürgen Lorenzen , Präsident des | Bibliothek | & Information Deutschland ( BID | bibliothek* |
| [64] - Daniel Beucke, Arvid | 1,776 | 1,776 | von TYPO3 . Der neue | Bibliothekskatalog | der SLUB Dresden ' , | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,006 | 2,006 | Video : ' Systembibliothekar , | Bibliotheksinformatiker | , IT-Bibliothekar - lässt sich | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,167 | 2,167 | wurde der Bibcast-Pilot in der | bibliothekarischen | Community aufgenommen ? Alle Bibcasts | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,258 | 2,258 | , sein Beitrag zum nächsten | Bibliothekskongress | möge abgelehnt werden , damit | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,279 | 2,279 | Erwähnungen von Bibcast-Präsentationen auf dem | Bibliothekskongress | . Auch die Bilanz der | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,565 | 2,565 | . Der Zusammenhang mit dem | Bibliothekskongress | hat zweifelsohne die Sichtbarkeit des | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,661 | 2,661 | Zielgruppe muss dabei nicht auf | BibliothekarInnen | begrenzt bleiben , denn durch | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,686 | 2,686 | Frage der Anbindung an den | Bibliothekartag | / Bibliothekskongress ist auch diejenige | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,688 | 2,688 | Anbindung an den Bibliothekartag / | Bibliothekskongress | ist auch diejenige der Gewinnung | bibliothek* |
| [64] - Daniel Beucke, Arvid | 2,710 | 2,710 | ( abgelehnten ) Beiträgen zum | Bibliothekskongress | zusammengesetzt . Ohne diese Kopplung | bibliothek* |
| [65] - Armin Talke (2016). | 63 | 63 | Regelungen , die Dienstleistungen von | Bibliotheken | betreffen1 . Urheberrecht , Europa | bibliothek* |
| [65] - Armin Talke (2016). | 133 | 133 | Anteil der digitalen Neuerwerbungen der | Bibliotheken | in Deutschland betrug 2015 in | bibliothek* |
| [65] - Armin Talke (2016). | 148 | 148 | % ( Quelle : Deutsche | Bibliotheksstatistik | ) , in der Staatsbibliothek | bibliothek* |
| [65] - Armin Talke (2016). | 209 | 209 | genutzt werden können . Öffentliche | Bibliotheken | , wie etwa Stadtbibliotheken , | bibliothek* |
| [65] - Armin Talke (2016). | 290 | 290 | zugänglich gemacht . Die wissenschaftlichen | Bibliotheken | produzieren und versenden Kopien digital | bibliothek* |
| [65] - Armin Talke (2016). | 355 | 355 | für Bevölkerung und Wissenschaft . | Bibliotheken | bieten ihre Services traditionell in | bibliothek* |
| [65] - Armin Talke (2016). | 442 | 442 | digitalen Medien , der in | Bibliotheken | die Papier-Ressourcen weitgehend ersetzt , | bibliothek* |
| [65] - Armin Talke (2016). | 529 | 529 | Papier per Fernleihe an andere | Bibliotheken | geben . Umgekehrt können BenutzerInnen | bibliothek* |
| [65] - Armin Talke (2016). | 542 | 542 | Werke , die von anderen | Bibliotheken | unter solchen Bedingungen bezogen werden | bibliothek* |
| [65] - Armin Talke (2016). | 584 | 584 | der Fernleihe , nun wieder | Bibliotheksreisen | erforderlich werden , wenn Medien | bibliothek* |
| [65] - Armin Talke (2016). | 596 | 596 | nirgends erreichbar sind . Keine | Bibliothek | hat die finanziellen Mittel , | bibliothek* |
| [65] - Armin Talke (2016). | 621 | 621 | : In der Papierwelt konnten | Bibliotheken | jedes einmal auf den Markt | bibliothek* |
| [65] - Armin Talke (2016). | 649 | 649 | Kaufpreis und die sog . | Bibliothekstantieme | entschädigt ; Bürger und Bürgerinnen | bibliothek* |
| [65] - Armin Talke (2016). | 717 | 717 | nicht auch die Nutzung in | Bibliotheken | . Das führt schon jetzt | bibliothek* |
| [65] - Armin Talke (2016). | 730 | 730 | Einschränkungen der Literaturversorgung . Zur | Bibliotheksausleihe | sind eigene Verträge erforderlich . | bibliothek* |
| [65] - Armin Talke (2016). | 778 | 778 | nicht als E-Book in der | Bibliothek | zu bekommen sind . Ein | bibliothek* |
| [65] - Armin Talke (2016). | 784 | 784 | zu bekommen sind . Ein | bibliothekarischer | Bestandsaufbau nach inhaltlichen Kriterien ist | bibliothek* |
| [65] - Armin Talke (2016). | 830 | 830 | wir vor , dass öffentliche | Bibliotheken | E-Books auf dem Endkundenmarkt lizenzieren | bibliothek* |
| [65] - Armin Talke (2016). | 889 | 889 | anschließende Ausleihe und Archivierung durch | Bibliotheken | möglich sind . Selbstverständlich sollte | bibliothek* |
| [65] - Armin Talke (2016). | 898 | 898 | Selbstverständlich sollte jede von einer | Bibliothek | erworbene Privatlizenz nur den Zugriff | bibliothek* |
| [65] - Armin Talke (2016). | 936 | 936 | Ländern freigestellt werden , eine | Bibliothekstantieme | für digitale Medien einzuführen , | bibliothek* |
| [65] - Armin Talke (2016). | 956 | 956 | klar ist , was die | Bibliothek | darf , handelt sie im | bibliothek* |
| [65] - Armin Talke (2016). | 1,091 | 1,091 | „ Leseplätzen “ in der | Bibliothek | , § 52b UrhG ( | bibliothek* |
| [65] - Armin Talke (2016). | 1,163 | 1,163 | die SBB noch eine andere | Bibliothek | von der Schranke Gebrauch machen | bibliothek* |
| [65] - Armin Talke (2016). | 1,205 | 1,205 | genutzt werden können . Für | Bibliotheken | ist es wichtig , mit | bibliothek* |
| [65] - Armin Talke (2016). | 1,237 | 1,237 | wie auch in anderen Wissenschaftlichen | Bibliotheken | werden ganze Lizenzierungs-Teams beschäftigt , | bibliothek* |
| [65] - Armin Talke (2016). | 1,274 | 1,274 | Rechteinhaber ist die Verhandlungsposition der | Bibliotheken | in der Tendenz schwach , | bibliothek* |
| [65] - Armin Talke (2016). | 1,388 | 1,388 | Teil der Medienwelt können auch | Bibliotheks-Dienstleistungen | vor nationalen Grenzen nicht Halt | bibliothek* |
| [65] - Armin Talke (2016). | 1,427 | 1,427 | von der SBB und anderen | Bibliotheken | nicht selbst , sondern nur | bibliothek* |
| [65] - Armin Talke (2016). | 1,485 | 1,485 | eigenen “ digitalen Ressourcen der | Bibliotheken | gehört zu den Bereichen großer | bibliothek* |
| [65] - Armin Talke (2016). | 1,513 | 1,513 | Werke verbieten , halten sich | Bibliotheken | und Universitäten hier zurück . | bibliothek* |
| [65] - Armin Talke (2016). | 1,892 | 1,892 | Werke , die in den | Bibliotheken | der Ursprungsländer nicht ( mehr | bibliothek* |
| [65] - Armin Talke (2016). | 1,986 | 1,986 | der VG erfolgt . Wissenschaftliche | Bibliotheken | wie die SBB , aber | bibliothek* |
| [65] - Armin Talke (2016). | 2,433 | 2,433 | ; https://ec.europa.eu/digital-single-market/en/news/proposal-directive-european-parliament-and-council-copyright-digital-single-market Die Wünsche der | Bibliotheken | , die im Juni-Gespräch vermittelt | bibliothek* |
| [66] - Dörte Böhner, Gabrie | 99 | 99 | 2015 ) , um die | Bibliothek | als Dritten Ort ( Haas | bibliothek* |
| [66] - Dörte Böhner, Gabrie | 122 | 122 | ) , Videospiele in Öffentlichen | Bibliotheken | ( Schultze 2016 ) , | bibliothek* |
| [66] - Dörte Böhner, Gabrie | 456 | 456 | Zeitschrift von der Fachcommunity aus | Bibliothek | , Archiv und Informationswesen für | bibliothek* |
| [66] - Dörte Böhner, Gabrie | 616 | 616 | : Workshopbericht : Armut und | Bibliotheken | ( Nürnberg 2015 ) . | bibliothek* |
| [66] - Dörte Böhner, Gabrie | 656 | 656 | machen – Praxisfall : Digitale | Bibliothek | . In : Informationspraxis 1 | bibliothek* |
| [66] - Dörte Böhner, Gabrie | 686 | 686 | 2015 ) : Ist die | Bibliothek | ein Dritter Ort ? Ein | bibliothek* |
| [66] - Dörte Böhner, Gabrie | 805 | 805 | : Videospielturniere in öffentlichen Schweizer | Bibliotheken | . In : Informationspraxis 2 | bibliothek* |
| [66] - Dörte Böhner, Gabrie | 829 | 829 | : Urban Gardening und Öffentliche | Bibliotheken | : Konzeption einer Veranstaltungsreihe in | bibliothek* |
| [67] - Tim Schumann (2016). | 15 | 15 | als ein Trend . Öffentliche | Bibliotheken | sollten sich diesem in der | bibliothek* |
| [67] - Tim Schumann (2016). | 93 | 93 | Libraries , Makerspaces , Öffentliche | Bibliothek | , Umweltbildung Urban Gardening is | bibliothek* |
| [67] - Tim Schumann (2016). | 211 | 211 | Dimension des Urban Gardening 4 | Bibliotheken | als urbane Werkstätten von morgen | bibliothek* |
| [67] - Tim Schumann (2016). | 223 | 223 | Abkehr vom Wissensspeicher 4.2 Makerspace | Bibliothek | , Makerspace Garten 5 Praxisprojekt | bibliothek* |
| [67] - Tim Schumann (2016). | 234 | 234 | „ Urban Gardening und Öffentliche | Bibliotheken | “ 5.1 . Konzeption der | bibliothek* |
| [67] - Tim Schumann (2016). | 277 | 277 | und Quellenverzeichnis Autor „ Grüne | Bibliotheken | auf die Tagesordnung “ forderte | bibliothek* |
| [67] - Tim Schumann (2016). | 287 | 287 | forderte Petra Hauke auf dem | Bibliothekartag | 2014 . Von ca . | bibliothek* |
| [67] - Tim Schumann (2016). | 295 | 295 | Von ca . 2000 Öffentlichen | Bibliotheken | in Deutschland würden lediglich 53 | bibliothek* |
| [67] - Tim Schumann (2016). | 339 | 339 | die Konsequenzen daraus für die | Bibliothekspraxis | “ ( Hauke & Werner | bibliothek* |
| [67] - Tim Schumann (2016). | 368 | 368 | „ ganz konkrete Chancen für | Bibliotheken | , [ sich ] als | bibliothek* |
| [67] - Tim Schumann (2016). | 548 | 548 | ) Diesem Trend können sich | Bibliotheken | anschließen und damit nicht nur | bibliothek* |
| [67] - Tim Schumann (2016). | 561 | 561 | Selbstverständnis hin zu einer grünen | Bibliothek | erweitern . Sie können der | bibliothek* |
| [67] - Tim Schumann (2016). | 571 | 571 | der Politik aufzeigen , dass | Bibliotheken | bedeutende Faktoren der Umsetzung gesellschaftspolitischer | bibliothek* |
| [67] - Tim Schumann (2016). | 593 | 593 | und Inklusion bereits vorleben . | Bibliotheken | können sich hier als moderner | bibliothek* |
| [67] - Tim Schumann (2016). | 800 | 800 | Zusätzlich sollte das Thema Makerspace | Bibliothek | mit dem Thema Urban Gardening | bibliothek* |
| [67] - Tim Schumann (2016). | 810 | 810 | Gardening verbunden werden . Öffentliche | Bibliotheken | und Gemeinschaftsgärten teilen viele gemeinsame | bibliothek* |
| [67] - Tim Schumann (2016). | 930 | 930 | Urban Gardening bewegt und warum | Bibliotheken | dieses Thema als ein zukünftiges | bibliothek* |
| [67] - Tim Schumann (2016). | 959 | 959 | , Urban Gardening in die | Bibliothek | zu bringen . Daher wird | bibliothek* |
| [67] - Tim Schumann (2016). | 971 | 971 | die Entwicklung des Themas grüner | Bibliotheksarbeit | dargestellt . Diesem folgen Darstellungen | bibliothek* |
| [67] - Tim Schumann (2016). | 1,023 | 1,023 | , Urban Gardening und Öffentliche | Bibliotheken | zu verknüpfen , wirkt und | bibliothek* |
| [67] - Tim Schumann (2016). | 1,100 | 1,100 | ( ALA 2015 ) . | Bibliotheken | sollen darin eine aktive Rolle | bibliothek* |
| [67] - Tim Schumann (2016). | 1,218 | 1,218 | , neben vielen anderen aktiven | Bibliotheken | , die hier leider nicht | bibliothek* |
| [67] - Tim Schumann (2016). | 1,235 | 1,235 | das beste Beispiel einer grünen | Bibliothek | dar . Mit dem Programm | bibliothek* |
| [67] - Tim Schumann (2016). | 1,349 | 1,349 | Götz ' Plädoyer für Grüne | Bibliotheken | im Jahr 2012 , die | bibliothek* |
| [67] - Tim Schumann (2016). | 1,374 | 1,374 | erstes Seminar zum Thema grüne | Bibliotheken | an der Hochschule der Medien | bibliothek* |
| [67] - Tim Schumann (2016). | 1,396 | 1,396 | , Ausstattung und Management einer | Bibliothek | auf ihre ökologische Nachhaltigkeit geprüft | bibliothek* |
| [67] - Tim Schumann (2016). | 1,483 | 1,483 | einzigartige Saatgutbibliothek in einer Öffentlichen | Bibliothek | . ( Kroll 2015 : | bibliothek* |
| [67] - Tim Schumann (2016). | 1,718 | 1,718 | diskutierten zukünftigen Rolle von Öffentlichen | Bibliotheken | auf . Daher plädiert Christa | bibliothek* |
| [67] - Tim Schumann (2016). | 2,068 | 2,068 | Frage nach der Zukunft der | Bibliotheken | ist derzeit stark diskutiert , | bibliothek* |
| [67] - Tim Schumann (2016). | 2,101 | 2,101 | führt . Vielmehr müssen sich | Bibliotheken | zu einem Co-Working-Hub oder einem | bibliothek* |
| [67] - Tim Schumann (2016). | 2,117 | 2,117 | . Auf diese Weise können | Bibliotheken | „ Orte der Transformation “ | bibliothek* |
| [67] - Tim Schumann (2016). | 2,155 | 2,155 | Schleh fasst zusammen : „ | Bibliotheken | haben das Potential , die | bibliothek* |
| [67] - Tim Schumann (2016). | 2,181 | 2,181 | Fansa hebt hervor , dass | Bibliotheken | sich in einem permanenten Neuerfindungsprozess | bibliothek* |
| [67] - Tim Schumann (2016). | 2,222 | 2,222 | , zum denen auch ein | Bibliotheksgarten | gehören kann . In diesem | bibliothek* |
| [67] - Tim Schumann (2016). | 2,231 | 2,231 | In diesem Sinne kann eine | Bibliothek | sich zu einer „ Befähigungsagentur | bibliothek* |
| [67] - Tim Schumann (2016). | 2,277 | 2,277 | eine neue zentrale Aufgabe von | Bibliotheken | , die am Besten durch | bibliothek* |
| [67] - Tim Schumann (2016). | 2,318 | 2,318 | wird bei der Zukunft der | Bibliotheken | auch auf die Zusammenarbeit mit | bibliothek* |
| [67] - Tim Schumann (2016). | 2,360 | 2,360 | diesen Prozess vor allem für | Bibliotheken | im ländlichen Raum als nötig | bibliothek* |
| [67] - Tim Schumann (2016). | 2,414 | 2,414 | einer Gemeinde Platz in der | Bibliothek | findet , desto eher wird | bibliothek* |
| [67] - Tim Schumann (2016). | 2,421 | 2,421 | , desto eher wird die | Bibliothek | ihren Platz in der Kommune | bibliothek* |
| [67] - Tim Schumann (2016). | 2,726 | 2,726 | Makerspace mitgestalten . Damit stellen | Bibliotheken | ihre Infrastrukturen und Ressourcen auch | bibliothek* |
| [67] - Tim Schumann (2016). | 2,828 | 2,828 | auch gärtnerische Makerspaces ein Teil | bibliothekarischer | Arbeit sein , mit denen | bibliothek* |
| [67] - Tim Schumann (2016). | 2,834 | 2,834 | Arbeit sein , mit denen | Bibliotheken | „ an gesellschaftliche Trends und | bibliothek* |
| [67] - Tim Schumann (2016). | 2,869 | 2,869 | Gardening-Makerspace umzuwandeln , den Raum | Bibliothek | umzudenken und neue Formen des | bibliothek* |
| [67] - Tim Schumann (2016). | 2,955 | 2,955 | von Themen in einer Öffentlichen | Bibliothek | handelt , muss der experimentelle | bibliothek* |
| [67] - Tim Schumann (2016). | 3,739 | 3,739 | z.B . den großen Öffentlichen | Bibliotheken | , ausgehangen . Am 10 | bibliothek* |
| [67] - Tim Schumann (2016). | 3,970 | 3,970 | und bezeichnete die „ Oldesloer | Bibliothek | als Kreativ-Werkstatt “ ( LN | bibliothek* |
| [67] - Tim Schumann (2016). | 4,370 | 4,370 | des Workshops im Mehrzweckraum der | Bibliothek | statt , der mit ca | bibliothek* |
| [67] - Tim Schumann (2016). | 4,481 | 4,481 | sie in die Kinderecke der | Bibliothek | gehen konnten . Da die | bibliothek* |
| [67] - Tim Schumann (2016). | 4,772 | 4,772 | verließen die ersten BesucherInnen die | Bibliothek | wieder . Ca . 10 | bibliothek* |
| [67] - Tim Schumann (2016). | 5,422 | 5,422 | die Veranstaltung auch innerhalb des | Bibliothekswesens | durchaus Aufmerksamkeit . Noch vor | bibliothek* |
| [67] - Tim Schumann (2016). | 5,450 | 5,450 | kommenden Ausgabe das Thema grüne | Bibliotheksarbeit | beleuchten wollte und nach einem | bibliothek* |
| [67] - Tim Schumann (2016). | 5,467 | 5,467 | dazu wird es auf dem | Bibliothekartag | 2016 ein Vortrag zur durchgeführten | bibliothek* |
| [67] - Tim Schumann (2016). | 5,507 | 5,507 | Planungen , ein Unterstützungsprogramm für | Bibliotheken | im ländlichen Raum aufzustellen , | bibliothek* |
| [67] - Tim Schumann (2016). | 5,565 | 5,565 | war die Idee der grünen | Bibliothek | , also einer Bibliothek , | bibliothek* |
| [67] - Tim Schumann (2016). | 5,569 | 5,569 | grünen Bibliothek , also einer | Bibliothek | , die sich vorwiegend architektonisch | bibliothek* |
| [67] - Tim Schumann (2016). | 5,597 | 5,597 | Bad Oldesloe in eine grüne | Bibliothek | oder auch der Einrichtung von | bibliothek* |
| [67] - Tim Schumann (2016). | 5,622 | 5,622 | Die Idee , dass eine | Bibliothek | einen ökologischen Beitrag für ihre | bibliothek* |
| [67] - Tim Schumann (2016). | 5,645 | 5,645 | neu gedacht . Aspekte klassischer | bibliothekarischer | Arbeit , wie der Bereitstellung | bibliothek* |
| [67] - Tim Schumann (2016). | 5,661 | 5,661 | Themengebiet wurden mit neuen Formen | bibliothekarischer | Arbeit , wie der Einrichtung | bibliothek* |
| [67] - Tim Schumann (2016). | 5,742 | 5,742 | Durch die Bereitstellung des Raumes | Bibliothek | , um Initiativen außerhalb des | bibliothek* |
| [67] - Tim Schumann (2016). | 5,749 | 5,749 | um Initiativen außerhalb des Raumes | Bibliothek | anzustoßen und Menschen zu verbinden | bibliothek* |
| [67] - Tim Schumann (2016). | 5,878 | 5,878 | die BesucherInnen zeigt , dass | Bibliotheken | als Multiplikatorinnen für ein solches | bibliothek* |
| [67] - Tim Schumann (2016). | 5,895 | 5,895 | Bereitschaft von Stiftungen , die | Bibliothek | zu unterstützen beweist die hohe | bibliothek* |
| [67] - Tim Schumann (2016). | 5,903 | 5,903 | beweist die hohe Vertrauenswürdigkeit von | Bibliotheken | , auch bei experimentellen Konzepten | bibliothek* |
| [67] - Tim Schumann (2016). | 5,965 | 5,965 | welches die Debatte um grüne | Bibliotheken | und ökologisch und nachhaltige Bibliotheksarbeit | bibliothek* |
| [67] - Tim Schumann (2016). | 5,970 | 5,970 | Bibliotheken und ökologisch und nachhaltige | Bibliotheksarbeit | wieder nur um einen kleinen | bibliothek* |
| [67] - Tim Schumann (2016). | 5,991 | 5,991 | Richtung beibehalten und den Raum | Bibliothek | als Treffpunkt und Vernetzungsort ausbauen | bibliothek* |
| [67] - Tim Schumann (2016). | 6,075 | 6,075 | Veranstaltung außerhalb der Räume der | Bibliothek | zu organisieren . Inspiriert durch | bibliothek* |
| [67] - Tim Schumann (2016). | 6,258 | 6,258 | , Robert 2015 : Die | Bibliothek | als Dritter Ort . Bub | bibliothek* |
| [67] - Tim Schumann (2016). | 6,266 | 6,266 | Ort . Bub – Forum | Bibliothek | und Information ( 65 ) | bibliothek* |
| [67] - Tim Schumann (2016). | 6,378 | 6,378 | Dudek , Jochen 2015 : | Bibliothekspädagogik | – ein etwas anderer Zugang | bibliothek* |
| [67] - Tim Schumann (2016). | 6,388 | 6,388 | Zugang . Bub – Forum | Bibliothek | und Information ( 65 ) | bibliothek* |
| [67] - Tim Schumann (2016). | 6,411 | 6,411 | Zum Stand der Nachhaltigkeitsdebatte im | Bibliotheksbau | . Zeitschrift für Bibliothekswesen und | bibliothek* |
| [67] - Tim Schumann (2016). | 6,415 | 6,415 | im Bibliotheksbau . Zeitschrift für | Bibliothekswesen | und Bibliographie ( 58 ) | bibliothek* |
| [67] - Tim Schumann (2016). | 6,466 | 6,466 | ? . Bub – Forum | Bibliothek | und Information ( 65 ) | bibliothek* |
| [67] - Tim Schumann (2016). | 6,549 | 6,549 | : Farbe bekennen – grüne | Bibliotheken | auf die Agenda . Bub | bibliothek* |
| [67] - Tim Schumann (2016). | 6,557 | 6,557 | Agenda . Bub – Forum | Bibliothek | und Information 66 ( 1 | bibliothek* |
| [67] - Tim Schumann (2016). | 6,583 | 6,583 | : Farbe bekennen – grüne | Bibliotheken | auf die Tagesordnung . ( | bibliothek* |
| [67] - Tim Schumann (2016). | 6,610 | 6,610 | Gabriele 2015 : Die grüne | Bibliothek | der Nachbarschaft . Büchereiperspektiven , | bibliothek* |
| [67] - Tim Schumann (2016). | 6,668 | 6,668 | Makerspace-Bewegung . Bub – Forum | Bibliothek | und Information ( 66 ) | bibliothek* |
| [67] - Tim Schumann (2016). | 6,798 | 6,798 | , Bernd 2015 : Die | Bibliothek | als urbane Werkstatt von morgen | bibliothek* |
| [67] - Tim Schumann (2016). | 6,890 | 6,890 | Vogt , Hannelore 2015 : | Bibliotheken | sollten lebendige Erlebnisräume sein . | bibliothek* |
| [67] - Tim Schumann (2016). | 6,900 | 6,900 | . . Bub – Forum | Bibliothek | und Information 65 ( 7 | bibliothek* |
| [67] - Tim Schumann (2016). | 6,975 | 6,975 | ( FAMI ) in der | Bibliothek | des Presse- und Informationsamtes der | bibliothek* |
| [68] - Gabriele Fahrenkrog | 42 | 42 | die Anforderungen an den Lernort | Bibliothek | . Öffentliche Bibliotheken bieten Zugang | bibliothek* |
| [68] - Gabriele Fahrenkrog | 45 | 45 | den Lernort Bibliothek . Öffentliche | Bibliotheken | bieten Zugang zu Lehr- und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 85 | 85 | nicht den Weg in Öffentliche | Bibliotheken | gefunden . Es wird dargelegt | bibliothek* |
| [68] - Gabriele Fahrenkrog | 98 | 98 | Gründe für ein Engagement von | Bibliotheken | mit OER spricht und aufgezeigt | bibliothek* |
| [68] - Gabriele Fahrenkrog | 107 | 107 | und aufgezeigt , was Öffentliche | Bibliotheken | mit bereits vorhandenen Kompetenzen und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 146 | 146 | zu bearbeiten . Schlüsselwörter Öffentliche | Bibliothek | ; Lernort ; OER ; | bibliothek* |
| [68] - Gabriele Fahrenkrog | 334 | 334 | Aspekte 4 OER in Öffentlichen | Bibliotheken | 4.1 Lernort Bibliothek Weiterbildung , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 337 | 337 | in Öffentlichen Bibliotheken 4.1 Lernort | Bibliothek | Weiterbildung , Lebenslanges Lernen und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 347 | 347 | und OER 4.2 Materialien von | Bibliotheken | und OER 5 Angebote und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 403 | 403 | Medium in den Fokus Öffentlicher | Bibliotheken | rücken sollten . Lernmedien für | bibliothek* |
| [68] - Gabriele Fahrenkrog | 443 | 443 | selbstverständlich Teil des Bestandes Öffentlicher | Bibliotheken | . Insbesondere auch im Bezug | bibliothek* |
| [68] - Gabriele Fahrenkrog | 455 | 455 | Konzept des Lebenslangen Lernens bauen | Bibliotheken | ihre Bestände auf und stellen | bibliothek* |
| [68] - Gabriele Fahrenkrog | 479 | 479 | ermöglichen . Beschäftigte in Öffentlichen | Bibliotheken | erstellen selbst Materialien für Schulungen | bibliothek* |
| [68] - Gabriele Fahrenkrog | 506 | 506 | . Im Bereich der Wissenschaftlichen | Bibliotheken | gibt es eine Reihe von | bibliothek* |
| [68] - Gabriele Fahrenkrog | 623 | 623 | OER für ( Öffentliche ) | Bibliotheken | . Darüber hinaus beleuchtet Plieninger | bibliothek* |
| [68] - Gabriele Fahrenkrog | 681 | 681 | Vermittlung von Bildung für Öffentlichen | Bibliotheken | , und ob freie Bildungsmedien | bibliothek* |
| [68] - Gabriele Fahrenkrog | 692 | 692 | das Potenzial haben , die | Bibliothek | als Lernort zu positionieren , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 740 | 740 | sich mit OER für Öffentliche | Bibliotheken | die Gelegenheit , sich als | bibliothek* |
| [68] - Gabriele Fahrenkrog | 777 | 777 | zur Rolle ( Öffentlicher ) | Bibliotheken | und die konsequente Umsetzung des | bibliothek* |
| [68] - Gabriele Fahrenkrog | 810 | 810 | Überzeugung heraus engagieren sich Wissenschaftliche | Bibliotheken | seit vielen Jahren erfolgreich für | bibliothek* |
| [68] - Gabriele Fahrenkrog | 839 | 839 | entwickelt , die von Wissenschaftlichen | Bibliotheken | mittlerweile selbstverständlich geleistet werden . | bibliothek* |
| [68] - Gabriele Fahrenkrog | 861 | 861 | Arbeiten , daher sahen Öffentliche | Bibliotheken | in der Auseinandersetzung mit Open | bibliothek* |
| [68] - Gabriele Fahrenkrog | 896 | 896 | Engagement mit freien Bildungsmedien : | Bibliotheken | sind Orte der Kommunikation und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 924 | 924 | von und über OER . | Bibliotheken | überall unterstützen die Entdeckung neuer | bibliothek* |
| [68] - Gabriele Fahrenkrog | 979 | 979 | geeignet , OER-Aktivitäten innerhalb der | Bibliothek | zu realisieren ( vgl . | bibliothek* |
| [68] - Gabriele Fahrenkrog | 995 | 995 | . Schon jetzt werden in | Bibliotheken | Materialien zu unterschiedlichen Schulungen und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 1,061 | 1,061 | digitale Formate ergänzt . Öffentliche | Bibliotheken | bleiben auch in Zukunft relevante | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,206 | 2,206 | für den Bereich der Wissenschaftlichen | Bibliotheken | , im Rahmen der Entwicklung | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,228 | 2,228 | . Eine der Kernaufgaben Öffentlicher | Bibliotheken | ist , freien Zugang zu | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,295 | 2,295 | Es ist die Aufgabe von | Bibliotheken | , Ordnung und Übersichtlichkeit durch | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,405 | 2,405 | Aspekte beinhaltet , denen sich | Bibliotheken | als Aufgabe verpflichtet sehen : | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,463 | 2,463 | Etablierung von OER in Öffentlichen | Bibliotheken | auf der Hand liegen , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,537 | 2,537 | Lernorte kombiniert werden . Die | Bibliothek | übernimmt hier sowohl als Lernort | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,566 | 2,566 | Für freie Bildungsmedien in Öffentlichen | Bibliotheken | spricht der praktische Nutzen , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,654 | 2,654 | Gesellschaft bedeutet zudem eine Öffentliche | Bibliothek | , die sich aktiv in | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,688 | 2,688 | an , „ dass öffentliche | Bibliotheken | eine wichtige Rolle als Lernort | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,730 | 2,730 | ausgezeichneter Anknüpfungspunkt gegeben ist , | Bibliotheken | als Lernort herauszustellen ( vgl | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,751 | 2,751 | bezieht sich zum einen auf | Bibliothek | als Ort des Erwerbs und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,787 | 2,787 | Moskaliuk 2015 ) , den | Bibliotheken | heute bieten oder bieten sollten | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,797 | 2,797 | sollten . Eine Vielzahl an | Bibliotheken | stellt bereits Räume für sich | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,836 | 2,836 | . 14 . ' Lernort | Bibliothek | ' soll hier nicht verstanden | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,876 | 2,876 | pädagogisch ausgebildetes Personal in Öffentlichen | Bibliotheken | – kann ein derartiger Service | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,914 | 2,914 | wäre15 . Mit Abschluss einer | bibliotheksfachlichen | Ausbildung sind in aller Regel | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,947 | 2,947 | , die den Ansprüchen an | Bibliothek | als Lernort in der Wissensgesellschaft | bibliothek* |
| [68] - Gabriele Fahrenkrog | 2,956 | 2,956 | der Wissensgesellschaft gerecht werden . | Bibliotheken | entwickeln sich stetig weiter , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,039 | 3,039 | . Mit OER eröffnen Öffentliche | Bibliotheken | die Möglichkeit , Lehrmaterialien aus | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,106 | 3,106 | selbstgesteuerten Lernen , fallen Öffentlichen | Bibliotheken | eine Reihe von Aufgaben zu | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,159 | 3,159 | Gruppen . Weiterhin sind auch | Bibliotheken | dazu angehalten , die Forderungen | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,244 | 3,244 | Konkret bedeutet dies für Öffentliche | Bibliotheken | , OER als vollwertiges Medium | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,294 | 3,294 | Möglichkeiten zu unterstützen . Öffentliche | Bibliotheken | er- und überarbeiten Konzepte zu | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,347 | 3,347 | ) Nutzung und Bearbeitung durch | Bibliotheken | selbst : Freie Materialien können | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,382 | 3,382 | Verfügung gestellt werden . Suchen | Bibliotheken | etwa nach Konzepten zur Nachnutzung | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,438 | 3,438 | geeigneten Materialien gibt . Von | Bibliotheken | erstellte Materialien sind auf Webseiten | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,564 | 3,564 | OER aus und für die | bibliothekarische | Praxis künftig auf einer Plattform17 | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,611 | 3,611 | der Suche nach OER Für | Bibliotheken | erwachsen daraus die Aufgaben : | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,648 | 3,648 | 2013 : 814-818 ) . | Bibliotheken | sind ideal dafür geeignet , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,680 | 3,680 | Materialien vorhanden , Beschäftigte in | Bibliotheken | sind erfahren in der Nutzerberatung | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,699 | 3,699 | . Vor allem verfügen Öffentliche | Bibliotheken | zumeist über gute Kontakte zu | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,744 | 3,744 | OER verbunden sind . Öffentliche | Bibliotheken | können durch Beratung und praktische | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,839 | 3,839 | Unterstützung Lernender und Lehrender können | Bibliotheken | dabei behilflich sein , kollaborativ | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,870 | 3,870 | die Materialien zu verwalten . | Bibliotheken | können Hilfestellung bei der Digitalisierung | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,913 | 3,913 | Zwecke . Weiterhin können Öffentliche | Bibliotheken | Schulungen zur Informationskompetenz im Zusammenhang | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,947 | 3,947 | Frage ob , sondern womit | Bibliotheken | konkret beginnen sollten , sich | bibliothek* |
| [68] - Gabriele Fahrenkrog | 3,987 | 3,987 | sich dann nahezu jede Öffentliche | Bibliothek | , unabhängig von Größe und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,021 | 4,021 | und Nutzerinnen und Nutzer der | Bibliothek | werden mit relevanten Inhalten zusammen | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,046 | 4,046 | OER als Thema des Lernortes | Bibliothek | bekannt zu machen ? Wer | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,076 | 4,076 | an Nutzerinnen und Nutzer der | Bibliothek | im Rahmen der Beratung , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,094 | 4,094 | , kann praktisch von allen | Bibliotheken | erbracht werden . Bloggende Bibliotheken | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,099 | 4,099 | Bibliotheken erbracht werden . Bloggende | Bibliotheken | und auch diejenigen , die | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,133 | 4,133 | eigenen Webseite oder über das | Bibliotheksmanagementsystem | können Rubriken für freie Bildungsmedien | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,158 | 4,158 | sich die Kooperation mit anderen | Bibliotheken | , z.B . durch gemeinsame | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,209 | 4,209 | auch über Informationen auf der | Bibliothekswebseite | oder auch über Infomaterial , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,230 | 4,230 | im Umfeld sollten von der | Bibliothek | ausfindig gemacht werden und z.B | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,257 | 4,257 | das individuelle Beratungsgespräch in der | Bibliothek | erreicht . Bei Anfragen zu | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,307 | 4,307 | zu bestimmten Themen in der | Bibliothek | , stets mitzudenken und in | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,386 | 4,386 | zuletzt sollten Beiträge zum Lernort | Bibliothek | mit Hinweisen auf Angebote und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,416 | 4,416 | OER und wie kann die | Bibliothek | die Erstellung unterstützen ? Abb | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,440 | 4,440 | werden von Beschäftigten in vielen | Bibliotheken | selbst erstellt . Vor allem | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,479 | 4,479 | , an die sich die | Bibliothek | mit unterstützenden Angeboten richten kann | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,489 | 4,489 | kann . Die meisten Öffentlichen | Bibliotheken | verfügen über PC-Internetarbeitsplätze und immer | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,510 | 4,510 | Geräten in den Räumen der | Bibliothek | . Die vorhandene technische Ausstattung | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,634 | 4,634 | auch interaktive Elemente beinhaltet . | Bibliotheken | können die Erstellung dieser Materialien | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,723 | 4,723 | nach Kapazität , kann in | Bibliotheken | eine Kurzeinführung für Kleingruppen ebenso | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,750 | 4,750 | möglich ist . Verfügt die | Bibliothek | nicht selbst über geeignete Räume | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,780 | 4,780 | Ausstattung bereitstellen , während die | Bibliothek | ihrerseits Wissen , etwa über | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,925 | 4,925 | als Schulungsthema infrage . Öffentliche | Bibliotheken | haben - selbst wenn nur | bibliothek* |
| [68] - Gabriele Fahrenkrog | 4,999 | 4,999 | Engagement für OER würde die | Bibliothek | als Ort der digitalen ( | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,032 | 5,032 | Ort die breite Initiative Öffentlicher | Bibliotheken | in diesem Bereich begrüßten und | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,048 | 5,048 | , denn noch immer steht | Bibliothek | für qualitätsgeprüfte Inhalte , Vermittlungskompetenz | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,134 | 5,134 | geschultes Personal für in den | Bibliotheken | . Mit der Fülle der | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,160 | 5,160 | . Darauf sollten sich Öffentliche | Bibliotheken | mit ihren Angebot an Raum | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,319 | 5,319 | Anforderungen , kommen auch Öffentliche | Bibliotheken | kaum umhin , den Umgang | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,347 | 5,347 | Prinzip gelebt werden . Öffentliche | Bibliotheken | , die ' offen ' | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,412 | 5,412 | Wissenschaftsgesellschaft sind noch unterentwickelt . | Bibliotheken | sollten daher eine Funktion zwischen | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,487 | 5,487 | Open Access und in Wissenschaftlichen | Bibliotheken | ist mittlerweile einiges an Erfahrung | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,513 | 5,513 | ) . Darauf können Öffentliche | Bibliotheken | für den Einstieg in OER | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,539 | 5,539 | , würde deren Potenziale für | Bibliotheken | unberücksichtigt lassen , denn erst | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,589 | 5,589 | Bildung für viele Menschen . | Bibliotheken | sollten bei der Gestaltung des | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,796 | 5,796 | Resources ( OER ) in | Bibliotheken | . URL : http://blog.openbib.org/2014/03/05/open-educational-resources-oer-in-bibliotheken/ Hapke | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,810 | 5,810 | : Open Educational Resources und | Bibliotheken | . URL : http://blog.hapke.de/information-literacy/open-educational-resources-und-bibliotheken/ Herrmann | bibliothek* |
| [68] - Gabriele Fahrenkrog | 5,839 | 5,839 | Deutschland ? In : Perspektive | Bibliothek | 4.1 ( 2015 ) , | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,012 | 6,012 | ein Praxisbeispiel . In : | Bibliotheksdienst | . Band 49 , Heft | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,054 | 6,054 | Herausforderung für Hoschschulen – und | Bibliotheken | . In : b-i-t-online 18 | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,123 | 6,123 | ) : Neue Herausforderungen für | Bibliotheken | . In : Bibliotheksdienst . | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,127 | 6,127 | für Bibliotheken . In : | Bibliotheksdienst | . Band 47 , Heft | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,184 | 6,184 | Educational Resources . In : | Bibliotheksdienst | . Band 49 , Heft | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,225 | 6,225 | Educational Resources als Dienstleistungen von | Bibliotheken | . In : Bibliotheksdienst . | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,229 | 6,229 | von Bibliotheken . In : | Bibliotheksdienst | . Band 49 , Heft | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,275 | 6,275 | ( OER ) in öffentlichen | Bibliotheken | . URL : http://zwischenseiten.com/2013/05/24/coer13-7-einsatzszenarios-von-offenen-bildungsressourcen-oer-in-offentlichen-bibliotheken/ Shrivastava | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,628 | 6,628 | HAW Hamburg . Seit 2003 | Bibliothekarin | in Öffentlichen Bibliotheken . eMail | bibliothek* |
| [68] - Gabriele Fahrenkrog | 6,631 | 6,631 | Seit 2003 Bibliothekarin in Öffentlichen | Bibliotheken | . eMail : fahrenkrog@posteo.de Fußnoten | bibliothek* |
| [69] - Simon Schultze (2016 | 15 | 15 | Thema Videospielturniere in öffentlichen Schweizer | Bibliotheken | . Den praktischen Teil dieser | bibliothek* |
| [69] - Simon Schultze (2016 | 84 | 84 | Organisation künftiger Veranstaltungen zusammenzufassen . | Bibliotheksevent | , Gaming , öffentliche Bibliotheken | bibliothek* |
| [69] - Simon Schultze (2016 | 89 | 89 | Bibliotheksevent , Gaming , öffentliche | Bibliotheken | , Schweiz , Videospielturnier This | bibliothek* |
| [69] - Simon Schultze (2016 | 301 | 301 | folgend , führen immer mehr | Bibliotheken | einen Videospielbestand ( Brown , | bibliothek* |
| [69] - Simon Schultze (2016 | 325 | 325 | Treffpunkt gibt es für die | Bibliotheken | weitere Möglichkeiten , das Medium | bibliothek* |
| [69] - Simon Schultze (2016 | 358 | 358 | zum gemeinsamen Videospielen in der | Bibliothek | treffen . Solche Events wurden | bibliothek* |
| [69] - Simon Schultze (2016 | 368 | 368 | wurden bereits erfolgreich in angelsächsischen | Bibliotheken | durchgeführt , was ein entsprechendes | bibliothek* |
| [69] - Simon Schultze (2016 | 414 | 414 | Als positiven Nebeneffekt verzeichneten die | Bibliotheken | zudem mehr neue Bibliotheksnutzerinnen ( | bibliothek* |
| [69] - Simon Schultze (2016 | 418 | 418 | die Bibliotheken zudem mehr neue | Bibliotheksnutzerinnen | ( Buchanan , Vanden Elzen | bibliothek* |
| [69] - Simon Schultze (2016 | 457 | 457 | Erfolge auch in öffentlichen Schweizer | Bibliotheken | möglich sind , beschäftigt sich | bibliothek* |
| [69] - Simon Schultze (2016 | 866 | 866 | im Kontext des Eventmarketings von | Bibliotheken | definiert : „ … . | bibliothek* |
| [69] - Simon Schultze (2016 | 923 | 923 | Teilnehmerinnen untereinander und mit der | Bibliothek | , in Form eines zielgruppenorientierten | bibliothek* |
| [69] - Simon Schultze (2016 | 942 | 942 | zeigen , dass Videospielangebote in | Bibliotheken | von den Nutzerinnen ausgiebig genutzt | bibliothek* |
| [69] - Simon Schultze (2016 | 1,007 | 1,007 | dass ein Videospielbestand auch bisherige | Bibliotheks-Nicht-Nutzerinnen | anzusprechen vermag ( Hommel 2008 | bibliothek* |
| [69] - Simon Schultze (2016 | 1,046 | 1,046 | Nicht-mehr-Nutzer mehr Videospiele in der | Bibliothek | ( Ehmig 2012b , Folie | bibliothek* |
| [69] - Simon Schultze (2016 | 1,064 | 1,064 | , dass der Videospielbestand in | Bibliotheken | ein Bedürfnis der Nutzerinnen ist | bibliothek* |
| [69] - Simon Schultze (2016 | 1,076 | 1,076 | sie vermehrt zum Besuch der | Bibliothek | zu bringen vermag ( Williams | bibliothek* |
| [69] - Simon Schultze (2016 | 1,182 | 1,182 | Internet anbieten . Für die | Bibliotheken | ist es ohne physisches Trägermedium | bibliothek* |
| [69] - Simon Schultze (2016 | 1,219 | 1,219 | . Diese sind gegenüber den | Bibliotheken | meist äusserst skeptisch und sehen | bibliothek* |
| [69] - Simon Schultze (2016 | 1,368 | 1,368 | im Aufbau eines Videospielbestandes für | Bibliotheken | ( Sigl , 2012 ) | bibliothek* |
| [69] - Simon Schultze (2016 | 1,383 | 1,383 | die Frage , ob die | Bibliotheken | generell auf einen Videospielbestand verzichten | bibliothek* |
| [69] - Simon Schultze (2016 | 1,462 | 1,462 | dass die Videospiele eine frühe | Bibliothekssozialisation | unterstützen können ( Neiburger 2007 | bibliothek* |
| [69] - Simon Schultze (2016 | 1,476 | 1,476 | 3 ) . Eine frühe | Bibliothekssozialisation | ist erstrebenswert , da sich | bibliothek* |
| [69] - Simon Schultze (2016 | 1,497 | 1,497 | Jugendlichen auch im späteren Leben | Bibliotheksnutzerinnen | bleiben ( Ehmig 2012a , | bibliothek* |
| [69] - Simon Schultze (2016 | 1,510 | 1,510 | ) . Für eine erfolgreiche | Bibliothekssozialisation | ist besonders der Übergang vom | bibliothek* |
| [69] - Simon Schultze (2016 | 1,536 | 1,536 | , kann ein Videospielbestand die | Bibliotheken | darin unterstützen , eine Relevanz | bibliothek* |
| [69] - Simon Schultze (2016 | 1,649 | 1,649 | als relevantes Medium für die | Bibliotheken | ein , dann stellt sich | bibliothek* |
| [69] - Simon Schultze (2016 | 1,668 | 1,668 | Einbindung von Videospielen in das | Bibliotheksangebot | unter den oben geschilderten Restriktionen | bibliothek* |
| [69] - Simon Schultze (2016 | 1,691 | 1,691 | Videospielen in das Angebot der | Bibliothek | ermöglicht , sind Videospielevents . | bibliothek* |
| [69] - Simon Schultze (2016 | 1,704 | 1,704 | es zunehmend schwieriger , in | Bibliotheken | einen Videospielbestand anzubieten . Dennoch | bibliothek* |
| [69] - Simon Schultze (2016 | 1,766 | 1,766 | eine Chance für Videospiele in | Bibliotheken | . Auch Bibliotheken fokussieren sich | bibliothek* |
| [69] - Simon Schultze (2016 | 1,769 | 1,769 | Videospiele in Bibliotheken . Auch | Bibliotheken | fokussieren sich - unabhängig von | bibliothek* |
| [69] - Simon Schultze (2016 | 1,791 | 1,791 | Zusammenhang wird oft von der | Bibliothek | als Drittem Ort gesprochen . | bibliothek* |
| [69] - Simon Schultze (2016 | 1,798 | 1,798 | Drittem Ort gesprochen . Die | Bibliotheken | verstehen sich in ihrer primären | bibliothek* |
| [69] - Simon Schultze (2016 | 1,833 | 1,833 | Videospiele die räumlich-soziale Veränderung der | Bibliotheken | hin zu einem dritten Ort | bibliothek* |
| [69] - Simon Schultze (2016 | 1,887 | 1,887 | kann das Spielen in der | Bibliothek | einen Event-Charakter erhalten , zum | bibliothek* |
| [69] - Simon Schultze (2016 | 1,903 | 1,903 | . Bisher gesammelte Erfahrungen der | Bibliotheken | zu Videospielevents zeigen , dass | bibliothek* |
| [69] - Simon Schultze (2016 | 1,999 | 1,999 | und ihre positive Wahrnehmung der | Bibliothek | zu erhöhen bzw . konstant | bibliothek* |
| [69] - Simon Schultze (2016 | 2,020 | 2,020 | . 809-811 ) . Die | Bibliotheken | konnten auch neue Nutzerinnen akquirieren | bibliothek* |
| [69] - Simon Schultze (2016 | 2,032 | 2,032 | welche die sonstigen Dienstleistungen der | Bibliothek | bisher nicht nutzten ( Neiburger | bibliothek* |
| [69] - Simon Schultze (2016 | 2,103 | 2,103 | Event auch andere Dienstleistungen der | Bibliothek | von den Teilnehmerinnen genutzt ( | bibliothek* |
| [69] - Simon Schultze (2016 | 2,136 | 2,136 | 33 ) . Beispielsweise berichteten | Bibliotheken | , dass mit den Videospielevents | bibliothek* |
| [69] - Simon Schultze (2016 | 2,234 | 2,234 | ausschliesslich bei nicht von der | Bibliothek | moderierten Events vorgekommen ist ( | bibliothek* |
| [69] - Simon Schultze (2016 | 2,255 | 2,255 | Forschungsstand zeigt , dass die | Bibliotheken | von Videospielevents profitieren können . | bibliothek* |
| [69] - Simon Schultze (2016 | 2,266 | 2,266 | Gleichwohl blieb in der deutschsprachigen | Bibliothekswissenschaft | das Thema „ Videospiele in | bibliothek* |
| [69] - Simon Schultze (2016 | 2,272 | 2,272 | das Thema „ Videospiele in | Bibliotheken | “ bisher unbeachtet . Alle | bibliothek* |
| [69] - Simon Schultze (2016 | 2,295 | 2,295 | 14.05.15 ) ergab für deutschsprachige | Bibliotheken | keine Untersuchungen zum Videospielbestand , | bibliothek* |
| [69] - Simon Schultze (2016 | 2,346 | 2,346 | deren Erkenntnisse auch auf öffentliche | Bibliotheken | in der Schweiz übertragen lassen | bibliothek* |
| [69] - Simon Schultze (2016 | 2,377 | 2,377 | Untersuchung zu Videospielevents in öffentlichen | Bibliotheken | im deutschsprachigen Raum durchzuführen . | bibliothek* |
| [69] - Simon Schultze (2016 | 2,394 | 2,394 | ein Gameevent für eine öffentliche | Bibliothek | haben könnte wie sich die | bibliothek* |
| [69] - Simon Schultze (2016 | 2,439 | 2,439 | Videospielevent in einer öffentlichen Schweizer | Bibliothek | ? Der Fokus der Fragestellung | bibliothek* |
| [69] - Simon Schultze (2016 | 2,459 | 2,459 | Interaktion und der Nutzung anderer | Bibliotheks-Dienstleistungen | während des Events von dieser | bibliothek* |
| [69] - Simon Schultze (2016 | 2,483 | 2,483 | das Geschlecht und die bisherigen | Bibliothekserfahrungen | der Teilnehmerinnen erfragt2 . Wie | bibliothek* |
| [69] - Simon Schultze (2016 | 2,678 | 2,678 | Videospielevent in einer öffentlichen Schweizer | Bibliothek | ? Die aus der Untersuchung | bibliothek* |
| [69] - Simon Schultze (2016 | 2,693 | 2,693 | dass Videospielturniere für eine öffentliche | Bibliothek | in der Schweiz eine sinnvolle | bibliothek* |
| [69] - Simon Schultze (2016 | 2,743 | 2,743 | während dem Event auch andere | Bibliotheksdienstleistungen | von den Teilnehmerinnen genutzt ( | bibliothek* |
| [69] - Simon Schultze (2016 | 2,900 | 2,900 | du schon einmal in einer | Bibliothek | ? Abb . 4 : | bibliothek* |
| [69] - Simon Schultze (2016 | 2,912 | 2,912 | häufig gehst du in die | Bibliothek | ? Wie sollte ein Videospielevent | bibliothek* |
| [69] - Simon Schultze (2016 | 3,019 | 3,019 | bisherigen Erkenntnisse zu Videospielturnieren in | Bibliotheken | beschränkten sich auf den angelsächsischen | bibliothek* |
| [69] - Simon Schultze (2016 | 3,034 | 3,034 | konnte nun für die öffentlichen | Bibliotheken | in der Schweiz geschlossen werden | bibliothek* |
| [69] - Simon Schultze (2016 | 3,091 | 3,091 | sowohl die Nutzung von anderen | Bibliotheksdienstleistungen | fördern können als auch die | bibliothek* |
| [69] - Simon Schultze (2016 | 3,105 | 3,105 | den Teilnehmerinnen . Für die | Bibliotheken | ist dies auch insofern interessant | bibliothek* |
| [69] - Simon Schultze (2016 | 3,155 | 3,155 | in das bestehende Angebot der | Bibliotheken | einbinden zu können . Ein | bibliothek* |
| [69] - Simon Schultze (2016 | 3,179 | 3,179 | Inwiefern die Resultate auch andere | Bibliotheken | dazu animieren , Videospielevents zu | bibliothek* |
| [69] - Simon Schultze (2016 | 3,244 | 3,244 | 2006 ) : Event-Marketing in | Bibliotheken | . Berlin : BibSpider . | bibliothek* |
| [69] - Simon Schultze (2016 | 3,466 | 3,466 | 2014 ) : Gaming und | Bibliotheken | . Praxiswissen . Berlin : | bibliothek* |
| [69] - Simon Schultze (2016 | 3,560 | 3,560 | Gründe für die Nichtnutzung von | Bibliotheken | in Deutschland : Repräsentative Telefonbefragung | bibliothek* |
| [69] - Simon Schultze (2016 | 3,634 | 3,634 | : Games gehören in die | Bibliotheken | . Zeit Online . Verfügbar | bibliothek* |
| [69] - Simon Schultze (2016 | 4,153 | 4,153 | Programs in Libraries . Digitale | Bibliothek | , 2009 ( 1 ) | bibliothek* |
| [69] - Simon Schultze (2016 | 4,777 | 4,777 | Studium der Informationswissenschaften , Schwerpunkt | Bibliothekswissenschaften | mit dem Bachelor ab . | bibliothek* |
| [69] - Simon Schultze (2016 | 4,827 | 4,827 | darunter ‚ Videospiele in der | Bibliothek | ‘ , ‚ Recherchekompetenz als | bibliothek* |
| [69] - Simon Schultze (2016 | 4,836 | 4,836 | Recherchekompetenz als essentielle Fähigkeit der | Bibliothekarin | ‘ und ‚ Das Darknet | bibliothek* |
| [70] - Gary Seitz, Barbara | 514 | 514 | . , es muss in | Bibliothekskatalogen | , Datenbanken , Suchmaschinen , | bibliothek* |
| [70] - Gary Seitz, Barbara | 2,229 | 2,229 | unter : http://dx.doi.org/10.3163/1536-5050.100.4.007 Gary SEITZ | Bibliothek | Geographisches Institut der Universität Zürich | bibliothek* |
| [70] - Gary Seitz, Barbara | 2,244 | 2,244 | Zürich http://www.geo.uzh.ch/de/bibliothek seitz@geo.uzh.ch Barbara GROSSMANN | Bibliothek | Geographisches Institut der Universität Zürich | bibliothek* |
| [70] - Gary Seitz, Barbara | 2,258 | 2,258 | CH-8057 Zürich http://www.geo.uzh.ch/de/bibliothek bgrossma@geo.uzh.ch 1 | Bibliothek | Geographisches Institut der Universität Zürich | bibliothek* |
| [71] - Andrea Hofmann, Chri | 37 | 37 | Die Mitarbeiterinnen und Mitarbeiter der | Bibliothek | liefen zu diesem Zweck mit | bibliothek* |
| [71] - Andrea Hofmann, Chri | 50 | 50 | ausgerüstet durch den Benutzungsbereich der | Bibliothek | , um Fragen der Nutzer | bibliothek* |
| [71] - Andrea Hofmann, Chri | 197 | 197 | Umsetzung des Konzepts in der | Bibliothek | der HsH 3 Erkenntnisse und | bibliothek* |
| [71] - Andrea Hofmann, Chri | 211 | 211 | Roving Librarians ( „ streunende | Bibliothekarinnen | oder Bibliothekare “ ) wird | bibliothek* |
| [71] - Andrea Hofmann, Chri | 213 | 213 | ( „ streunende Bibliothekarinnen oder | Bibliothekare | “ ) wird eine spezielle | bibliothek* |
| [71] - Andrea Hofmann, Chri | 255 | 255 | die Mitarbeiter und Mitarbeiterinnen der | Bibliothek | durch das Bibliotheksgebäude , um | bibliothek* |
| [71] - Andrea Hofmann, Chri | 258 | 258 | Mitarbeiterinnen der Bibliothek durch das | Bibliotheksgebäude | , um Fragen dort beantworten | bibliothek* |
| [71] - Andrea Hofmann, Chri | 382 | 382 | Effekte für das Image der | Bibliothek | und die Auskunftsdienstleistung insgesamt . | bibliothek* |
| [71] - Andrea Hofmann, Chri | 504 | 504 | an welchem Tag durch die | Bibliothek | „ streunt “ . Die | bibliothek* |
| [71] - Andrea Hofmann, Chri | 558 | 558 | Uhr . Die Öffnungszeiten der | Bibliothek | umfassten den Zeitraum von 9 | bibliothek* |
| [71] - Andrea Hofmann, Chri | 752 | 752 | des Monitors zum Ansprechen des | Bibliothekspersonals | ermuntern sollte ( Abb . | bibliothek* |
| [71] - Andrea Hofmann, Chri | 776 | 776 | Informationsangebots wurde unter anderem per | Bibliotheksblog | ( Hofmann 2011 ) informiert | bibliothek* |
| [71] - Andrea Hofmann, Chri | 911 | 911 | häufigsten Fragen aus dem klassisch | bibliothekarischen | Auskunftsspektrum , wobei auffällig ist | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,029 | 1,029 | Regulierung der Lautstärke in der | Bibliothek | sind in Zusammenhang mit den | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,075 | 1,075 | auffällig geringe Anzahl an „ | bibliotheksspezifischen | “ Fragen gilt es weiterhin | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,090 | 1,090 | mit Kolleginnen und Kollegen anderer | Bibliotheken | lassen den Schluss zu , | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,120 | 1,120 | , der auch in anderen | Bibliotheken | erkennbar ist . ( Kenney | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,143 | 1,143 | was Nutzerinnen und Nutzer einer | Bibliothek | wollen : „ They want | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,229 | 1,229 | und somit die Verfügbarkeit des | Bibliothekspersonals | “ netto “ deutlich unter | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,317 | 1,317 | Senkung der Lautstärke in der | Bibliothek | . Präsenz im Benutzungsbereich hatte | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,427 | 1,427 | interessante Diskussionsgrundlage über die Zukunft | bibliothekarischer | Auskunfts- und Unterstützungstätigkeit . Daran | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,488 | 1,488 | rund um die Auskunftsdienste der | Bibliothek | werden . Das Experiment „ | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,560 | 1,560 | zufrieden sind die Benutzer der | Bibliothek | der Fachhochschule Hannover ? : | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,592 | 1,592 | Lärm : Umbaumaßnahmen an der | Bibliothek | der Fachhochschule Hannover zur Schaffung | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,884 | 1,884 | . : Eine Testphase . | Bibliotheksforum | Bayern ( 3 ) , | bibliothek* |
| [71] - Andrea Hofmann, Chri | 1,899 | 1,899 | Internet : URL : https://www.bibliotheksforum-bayern.de/fileadmin/archiv/2015-3/eBook/files/assets/basic-html/page78.html | Bibliothek | der Hochschule Hannover ↩ Informationspraxis | bibliothek* |
| [72] - Martin Wollschläger- | 3,467 | 3,467 | sich im Zusammenhang Fachdatenbanken , | Bibliothekskataloge | oder der Internet-Suche das Phänomen | bibliothek* |
| [72] - Martin Wollschläger- | 3,553 | 3,553 | . ) . Ferner begegnen | Bibliotheken | dem Problem der verteilten Informationsressourcen | bibliothek* |
| [72] - Martin Wollschläger- | 3,604 | 3,604 | die über die Infrastrukturen von | Bibliotheken | realisiert wird ( Hapke 2015 | bibliothek* |
| [72] - Martin Wollschläger- | 6,004 | 6,004 | ) : Hochschuldidaktische Aspekte des | Bibliothekswesens | : Überlegungen und Vorschläge zu | bibliothek* |
| [72] - Martin Wollschläger- | 6,018 | 6,018 | Einführung von Studenten in die | Bibliotheksbenutzung | . DFW - Dokumentation , | bibliothek* |
| [72] - Martin Wollschläger- | 6,891 | 6,891 | De Gruyter Saur . ( | Bibliothek | : Monographien zu Forschung und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 30 | 30 | in den letzten Jahren im | Bibliothekswesen | etabliert . Es beschreibt strategische | bibliothek* |
| [73] - Corinna Haas, Rudolf | 38 | 38 | Es beschreibt strategische Entscheidungen von | Bibliotheken | , sich als Kommunikationsort und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 105 | 105 | angesiedelt ist und der heutigen | bibliothekarischen | Verwendung , als auch zwischen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 111 | 111 | Verwendung , als auch zwischen | Bibliotheken | , die das Schlagwort nutzen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 130 | 130 | verschiedenen neu- oder umgebauten schweizerischen | Bibliotheken | forschend die These vom „ | bibliothek* |
| [73] - Corinna Haas, Rudolf | 150 | 150 | der Studierenden zeigten vor allem | Bibliotheken | , die infrastrukturell „ Dritte | bibliothek* |
| [73] - Corinna Haas, Rudolf | 198 | 198 | aus den festgestellten Differenzen zwischen | bibliothekarischem | Diskurs , Realität in den | bibliothek* |
| [73] - Corinna Haas, Rudolf | 204 | 204 | Diskurs , Realität in den | Bibliotheken | und Zielen der Originalliteratur ergeben | bibliothek* |
| [73] - Corinna Haas, Rudolf | 221 | 221 | , Kommunikationsort , Ethnologie , | bibliothekarisches | Selbstverständnis The term „ Third | bibliothek* |
| [73] - Corinna Haas, Rudolf | 472 | 472 | Der Third Space in der | bibliothekarischen | Diskussion 3.2 Der Third Space | bibliothek* |
| [73] - Corinna Haas, Rudolf | 488 | 488 | Irritationen 4 Ergebnisse aus schweizerischen | Bibliotheken | 4.1 Definitionsansätze für Bibliotheken als | bibliothek* |
| [73] - Corinna Haas, Rudolf | 492 | 492 | schweizerischen Bibliotheken 4.1 Definitionsansätze für | Bibliotheken | als „ Dritter Ort “ | bibliothek* |
| [73] - Corinna Haas, Rudolf | 503 | 503 | 4.2 Untersuchungen der Realität in | Bibliotheken | 4.3 Abschluss des Seminars 4.3.1 | bibliothek* |
| [73] - Corinna Haas, Rudolf | 511 | 511 | des Seminars 4.3.1 Ethnografie in | Bibliotheken | : Marktstudien und sozialwissenschaftliche Forschung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 523 | 523 | Kritik am Dritten Ort als | Bibliotheksraumkonzept | 5 Fazit und offene Fragen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 539 | 539 | um die zukünftige Gestaltung von | Bibliotheken | hat sich in den letzten | bibliothek* |
| [73] - Corinna Haas, Rudolf | 568 | 568 | beispielsweise im Schwerpunkt „ Die | Bibliothek | als Dritter Ort ” der | bibliothek* |
| [73] - Corinna Haas, Rudolf | 609 | 609 | zum Um- und Neubau von | Bibliotheken | , sowohl Öffentlichen als auch | bibliothek* |
| [73] - Corinna Haas, Rudolf | 630 | 630 | von Einrichtungen zu beschreiben : | Bibliotheken | als Orte , die einen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 711 | 711 | . Eine Durchsicht der deutschsprachigen | bibliothekarischen | Zeitschriften zeigt das Aufkommen erst | bibliothek* |
| [73] - Corinna Haas, Rudolf | 743 | 743 | sollte untersucht werden , ob | Bibliotheken | den Ansprüchen , die im | bibliothek* |
| [73] - Corinna Haas, Rudolf | 799 | 799 | auf die Frage , ob | Bibliotheken | ein „ Dritter Ort ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 885 | 885 | und seiner Verwendung in der | bibliothekarischen | Diskussion . Anschliessend ( 4 | bibliothek* |
| [73] - Corinna Haas, Rudolf | 992 | 992 | jeweiligen Studierenden die Entwicklungen im | Bibliothekswesen | zu erläutern . Offensichtlich hat | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,018 | 1,018 | in zahlreichen Diskussionen im deutschsprachigen | Bibliothekswesen | auftauchte . Gleichzeitig wurde durch | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,059 | 1,059 | über die reale Nutzung von | Bibliotheken | in der Schweiz , gab | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,085 | 1,085 | auf die Fragen , ob | Bibliotheken | als Dritte Orte wirkten und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,095 | 1,095 | und ob die Absicht der | Bibliotheken | der tatsächlichen Nutzung entsprach . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,180 | 1,180 | von wissenschaftlichen Methoden in der | Bibliothekspraxis | erfahren . ( Schuldt & | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,194 | 1,194 | Dabei sind der „ Raum | Bibliothek | ” und die tatsächliche Nutzung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,201 | 1,201 | und die tatsächliche Nutzung von | Bibliotheken | ein Schwerpunktinteresse der beiden Dozierenden | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,289 | 1,289 | von Ray Oldenburg sowie der | bibliothekarischen | Literatur aus dem deutsch- und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,318 | 1,318 | solche , die schon in | Bibliotheken | eingesetzt wurden , vorgestellt . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,348 | 1,348 | mit denen versucht wurde , | Bibliotheken | zu beschreiben , die sich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,365 | 1,365 | . Zuletzt wurde gemeinsam die | Bibliothek | der Zürcher Hochschule der Künste | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,403 | 1,403 | Einführung durch den Leiter der | Bibliothek | erkundeten die Studierenden die Einrichtung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,560 | 1,560 | in einer von ihnen gewählten | Bibliothek | in der Schweiz planten . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,570 | 1,570 | . Untersucht wurden die Pestalozzi | Bibliothek | Altstadt – Zürich ( Guttmann | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,612 | 1,612 | ( Conti ) , die | Bibliothek | Hauptpost – St . Gallen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,629 | 1,629 | , Stucki ) , die | Bibliothek | der Pädagogischen Hochschule Zürich ( | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,726 | 1,726 | Wochen wurden in den genannten | Bibliotheken | Beobachtungen mit verschiedenen Methoden , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,804 | 1,804 | , dass kleinere Forschungsprojekte in | Bibliotheken | möglich sind und neue Erkenntnisse | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,851 | 1,851 | von ethnologischen Methoden in der | Bibliothekspraxis | die Arbeit , Ergebnisse und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 1,902 | 1,902 | aktuellen Debatte die Realität in | Bibliotheken | zu erforschen und dabei Erfahrungen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,068 | 2,068 | Dritten Ortes ” in der | bibliothekarischen | Diskussion und der soziologischen Originalliteratur | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,095 | 2,095 | Seminar : Zuerst wird die | bibliothekarische | Diskussion dargestellt ( 3.1 ) | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,159 | 2,159 | , welcher in der englischsprachigen | bibliothekarischen | Diskussion nach 2000 auftaucht und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,196 | 2,196 | um entweder neue Aufgaben von | Bibliotheken | zu entwerfen oder aber neue | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,205 | 2,205 | aber neue und neu umgebaute | Bibliotheken | zu beschreiben . Als Dritter | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,357 | 2,357 | neu gebauten und neu konzipierten | Bibliotheken | wird ebenso als Vorbild beschrieben | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,419 | 2,419 | ” eine sinnvolle Aufgabe für | Bibliotheken | beschriebe . Wenn Bibliotheken zu | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,423 | 2,423 | für Bibliotheken beschriebe . Wenn | Bibliotheken | zu gesellschaftlichen Orten würden oder | bibliothek* |
| [73] - Corinna Haas, Rudolf | 2,533 | 2,533 | zu beschreiben , was eine | Bibliothek | als „ Dritten Ort ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 3,035 | 3,035 | . Gleichzeitig wird dem Raum | Bibliothek | , in kleinerem Rahmen auch | bibliothek* |
| [73] - Corinna Haas, Rudolf | 3,044 | 3,044 | Rahmen auch der Arbeit der | Bibliothekarinnen | und Bibliothekare , grosse Bedeutung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 3,046 | 3,046 | der Arbeit der Bibliothekarinnen und | Bibliothekare | , grosse Bedeutung eingeräumt . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 3,084 | 3,084 | werden wird , dass die | bibliothekarische | Vorstellung vom „ Dritten Ort | bibliothek* |
| [73] - Corinna Haas, Rudolf | 3,117 | 3,117 | Oldenburg wirkt als Verunsicherung der | bibliothekarischen | Diskussion . Grundsätzlich wird immer | bibliothek* |
| [73] - Corinna Haas, Rudolf | 3,235 | 3,235 | spezifischen Aufgaben und Herausforderungen von | Bibliotheken | kein spezielles Interesse hat . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 4,560 | 4,560 | dem Bild , welches die | bibliothekarische | Literatur mit ihren Listen zeichnet | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,086 | 5,086 | Oldenburg andere Orte beschreibt als | Bibliotheken | . Beispielsweise ist es ihm | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,226 | 5,226 | Konzepte für die Zukunft von | Bibliotheken | . Genauer führt er in | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,240 | 5,240 | sogar explizit an , dass | Bibliotheken | zu komplex wären , um | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,287 | 5,287 | gilt es heute für viele | Bibliotheken | als ausgemacht , dass Third | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,313 | 5,313 | Nutzer danach verlangten , dass | Bibliotheken | zu solchen Orten würden ? | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,399 | 5,399 | existieren würden . Warum wollen | Bibliotheken | in Europa dann zu solchen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,415 | 5,415 | eher ein Schlagwort für US-amerikanische | Bibliotheken | sein ? Weiterhin muss bemerkt | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,481 | 5,481 | . Dieser Impetus scheint von | Bibliotheken | weder wahrgenommen noch in seinen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,590 | 5,590 | eine hohe Aufenthaltsqualität hat . | Bibliotheken | tendieren hingegen dazu , „ | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,692 | 5,692 | ” zu bilden . In | bibliothekarischen | Texten werden allerdings oft viel | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,776 | 5,776 | dem Fremd- und Selbstbild von | Bibliotheken | zu entsprechen . Letztlich muss | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,859 | 5,859 | solchen Diskussionsbeitrag als Grundlage für | bibliothekarische | Strategien zu vertrauen ist . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,906 | 5,906 | zehn Jahre in der englischsprachigen | bibliothekarischen | Literatur Verbreitung fand , in | bibliothek* |
| [73] - Corinna Haas, Rudolf | 5,944 | 5,944 | werden . Dies hat im | Bibliothekswesen | aber nicht stattgefunden : Obgleich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,030 | 6,030 | Offensichtlich ist , dass sich | Bibliotheken | nicht unbedingt auf das Modell | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,076 | 6,076 | verankert ? Wieso überzeugt er | Bibliotheken | und warum werden Teile , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,087 | 6,087 | die dagegen sprechen , dass | Bibliotheken | ihn übernehmen , offenbar ignoriert | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,101 | 6,101 | wirkt sich dies in den | Bibliotheken | eigentlich aus ? Im Rahmen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,146 | 6,146 | der selbst deklarierte Anspruch von | Bibliotheken | , „ Dritter Raum ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,164 | 6,164 | umgesetzt wurde . Oft wurden | Bibliotheken | umgestaltet , ohne dass diese | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,190 | 6,190 | untersuchte beispielsweise die Nutzung von | Bibliothekscafés | in den Stadtbibliotheken Aarau und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,235 | 6,235 | hat , das Image der | Bibliotheken | zu verbessern , doch gleichzeitig | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,250 | 6,250 | Überschneidung zwischen der Nutzung der | Bibliotheken | und der Bibliothekscafés . Insbesondere | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,253 | 6,253 | Nutzung der Bibliotheken und der | Bibliothekscafés | . Insbesondere wurden die Cafés | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,279 | 6,279 | ist beachtlich , da viele | Bibliotheken | Cafés und ähnliche Bereiche gerade | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,356 | 6,356 | in denen sie auch die | Bibliothek | betreten hatten . Kommunikation über | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,375 | 6,375 | , dann eher mit dem | Bibliothekspersonal | . Auch dies deutet darauf | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,389 | 6,389 | die kommunikative Funktion , die | Bibliotheken | als „ Dritte Orte ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,450 | 6,450 | über deren Sicht auf die | Bibliothek | führte , wurde ersichtlich , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,459 | 6,459 | ersichtlich , dass diese die | Bibliothek | intensiv als Teil ihres persönlichen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,478 | 6,478 | ist die Situation komplex : | Bibliotheken | scheinen sowohl gewisse Funktionen „ | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,517 | 6,517 | Infrastruktur , die in den | bibliothekarischen | Texten besprochen wird – insbesondere | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,523 | 6,523 | Texten besprochen wird – insbesondere | Bibliothekscafés | – , ohne dass ihre | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,815 | 6,815 | dass die Frage , ob | Bibliotheken | Dritte Orte sind und wenn | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,852 | 6,852 | von Forschungen im konkreten Raum | Bibliothek | getätigt werden soll , einer | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,880 | 6,880 | Irritationen als Hintergrund in schweizerischen | Bibliotheken | nach „ Dritten Orten ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 6,972 | 6,972 | Untersuchungsergebnisse in sechs sehr unterschiedlichen | Bibliotheken | an ( 4.2 ) . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,023 | 7,023 | Hypothesen in Bezug auf die | Bibliothek | als „ Dritter Ort ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,055 | 7,055 | Vorfeld , dem Besuch der | Bibliothek | der Zürcher Hochschule der Künste | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,071 | 7,071 | entschieden werden , was eine | Bibliothek | , die als „ Dritter | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,100 | 7,100 | Hypothesen in den jeweils untersuchten | Bibliotheken | auch testbar waren . In | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,123 | 7,123 | die Ansprüche Oldenburgs oder der | Bibliotheken | zu untersuchen . Auffällig war | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,174 | 7,174 | definierten , dass in einer | Bibliothek | , die als „ Dritter | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,206 | 7,206 | davon aus , dass diese | Bibliothek | gerade deshalb keinen „ Dritten | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,295 | 7,295 | Arbeitsgruppe fünf Kriterien für eine | Bibliothek | , die „ Dritter Ort | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,368 | 7,368 | 2015 ) . Für die | Bibliothek | Hauptpost St . Gallen wurden | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,413 | 7,413 | Medienausleihen und andere „ typische | Bibliotheksarbeiten | ” finden als Hauptaktivität statt | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,433 | 7,433 | 2015 ) . Für die | Bibliothek | der Pädagogischen Hochschule Zürich wurden | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,473 | 7,473 | Dritte Orte ” in der | Bibliothek | , es gibt Orte , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,563 | 7,563 | Oldenburg , aber auch die | bibliothekarische | Literatur vorgeschlagen werden , in | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,592 | 7,592 | Listen , die in der | bibliothekarischen | Literatur präsentiert werden , fielen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,640 | 7,640 | es , die Eigendefinitionen der | Bibliotheken | zu erfassen , teilweise durch | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,686 | 7,686 | Vorgehen zeigte , dass auch | Bibliotheken | untereinander sehr unterschiedliche Definitionen des | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,703 | 7,703 | Beispielsweise betonte die Leitung einer | Bibliothek | auf die Frage , ob | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,751 | 7,751 | , bei aller Verschiedenheit der | Bibliotheken | , positive Bezüge auf das | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,775 | 7,775 | Hingegen fanden sich in den | Bibliotheksordnungen | einiger Bibliotheken , die sich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,777 | 7,777 | sich in den Bibliotheksordnungen einiger | Bibliotheken | , die sich explizit als | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,796 | 7,796 | . So steht in der | Bibliotheksordnung | der Pädagogischen Hochschule Zürich : | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,831 | 7,831 | Insoweit scheint der Wunsch von | Bibliotheken | , „ Dritter Ort ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,868 | 7,868 | Realität in den jeweils untersuchten | Bibliotheken | zu erfassen . Oft kamen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,947 | 7,947 | Nutzern als auch mit dem | Bibliothekspersonal | . Grundsätzlich ist das Ergebnis | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,970 | 7,970 | Blick auf die jeweils untersuchte | Bibliothek | entwarfen – , bezogen auf | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,980 | 7,980 | auf die weitläufigen Vorstellungen von | Bibliotheken | als „ Dritte Orte ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 7,991 | 7,991 | , ernüchternd : Die untersuchten | Bibliotheken | werden nur zu einem geringen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,032 | 8,032 | , dass dafür in solchen | Bibliotheken | eine intensive Kommunikation stattfinden müsste | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,051 | 8,051 | eine ganze Anzahl der untersuchten | Bibliotheken | sich explizit als „ Dritte | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,085 | 8,085 | Regeln und die Einrichtung von | Bibliothekscafés | . Dennoch sind die Ergebnisse | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,093 | 8,093 | sind die Ergebnisse für die | Bibliotheken | positiv : Sie werden intensiv | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,114 | 8,114 | zeigen , dass diese die | Bibliotheken | in ihrer jetzigen Form hauptsächlich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,139 | 8,139 | die zeigten , dass die | Bibliotheken | zumindest zum Teil Funktionen des | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,158 | 8,158 | aber die Nutzerinnen und Nutzer | Bibliotheken | dennoch nicht als „ Dritte | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,190 | 8,190 | ) – die sowohl ein | Bibliothekscafé | als auch eine literarische Veranstaltungsreihe | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,219 | 8,219 | sich eher kurz in der | Bibliothek | aufhalten , dann zwar oft | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,262 | 8,262 | den literarischen Veranstaltungen scheint die | Bibliothek | als „ Dritter Ort ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,296 | 8,296 | sich das Bild von der | Bibliothek | in den letzten Jahren massiv | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,306 | 8,306 | massiv geändert hat . Die | Bibliothek | wird , obwohl sie „ | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,351 | 8,351 | ” nicht zutreffen . Die | Bibliothek | ist einladend , aber sie | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,423 | 8,423 | Nutzer , die zwar die | Bibliothek | nutzten , aber so gut | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,485 | 8,485 | = 42 ) und dem | Bibliothekspersonal | ( N = 17 ) | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,535 | 8,535 | % ja ) . Die | Bibliothek | wird genutzt , dennoch schloss | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,566 | 8,566 | Interaktion wünscht , sondern die | Bibliothek | vor allem als Platz der | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,664 | 8,664 | für die erst 2015 eröffnete | Bibliothek | Hauptpost St . Gallen , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,687 | 8,687 | Kantonsbibliothek Vadiana und die Öffentliche | Bibliothek | der Stadt unter dem neuen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,719 | 8,719 | , der zur Gründung dieser | Bibliothek | führte und die positive Sicht | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,731 | 8,731 | Bevölkerung St . Gallens auf | Bibliotheken | zeigt , siehe Dora 2013 | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,739 | 8,739 | siehe Dora 2013 ) Die | Bibliothek | ist explizit an einem publikumsreichen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,776 | 8,776 | , den genauen Charakter der | Bibliothek | zu erfassen . So will | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,783 | 8,783 | erfassen . So will die | Bibliothek | „ Dritter Ort ” sein | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,837 | 8,837 | zahlreichen Nutzerinnen und Nutzer die | Bibliothek | ganz anders wahrnehmen und nutzen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,896 | 8,896 | Nutzern selber hergestellt . Die | Bibliothek | erschien sehr ruhig , obwohl | bibliothek* |
| [73] - Corinna Haas, Rudolf | 8,940 | 8,940 | eine Anzahl von Personen die | Bibliothek | regelmässig aufsucht ( 9 täglich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,004 | 9,004 | der Umfrage sehr positiv zur | Bibliothek | und ihrer Atmosphäre . Das | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,010 | 9,010 | und ihrer Atmosphäre . Das | Bibliothekscafé | trug ebenso wenig zur Kommunikation | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,028 | 9,028 | aber weniger als Teil der | Bibliothek | und kaum in Verbindung mit | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,035 | 9,035 | kaum in Verbindung mit einem | Bibliotheksbesuch | . Die Vorstellung , dass | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,046 | 9,046 | Menschen zwischen Arbeit in der | Bibliothek | und Kommunikation im Bibliothekscafé hin- | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,050 | 9,050 | der Bibliothek und Kommunikation im | Bibliothekscafé | hin- und herwechseln würden , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,074 | 9,074 | Ergebnisse eine den Vorstellungen von | Bibliotheken | über ihre eigene Zukunft entgegenstehende | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,085 | 9,085 | Einschätzung : „ [ Öffentliche | Bibliotheken | ] möchten Orte sein , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,114 | 9,114 | um diese neue Gestalt der | Bibliothek | in der Bibliothekswelt und gegenüber | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,117 | 9,117 | Gestalt der Bibliothek in der | Bibliothekswelt | und gegenüber den Einflussgruppen zu | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,139 | 9,139 | dass die Nutzer von öffentlichen | Bibliotheken | ein geringes Interesse an diesem | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,160 | 9,160 | oder den Arbeitsplätzen in die | Bibliothek | gehen . ” ( Jehli | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,200 | 9,200 | architektonische und infrastrukturelle Angebot der | Bibliotheken | . Diese wurde in den | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,300 | 9,300 | These auf , dass die | Bibliothek | einen Teil der von ihr | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,382 | 9,382 | , welchen die Leiterin der | Bibliothek | in einem Interview dargelegt hatte | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,419 | 9,419 | des Personals ) , die | Bibliothek | sehr wohl als „ Dritter | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,450 | 9,450 | , dass dieser in der | Bibliothek | genutzte Definitionsansatz sehr weit vom | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,505 | 9,505 | nicht in den Mittelpunkt der | bibliothekarischen | Arbeit zu stellen und den | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,521 | 9,521 | als Teil der Bemühungen von | Bibliotheken | zu verstehen , die sich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,538 | 9,538 | stellte die Arbeitsgruppe in der | Bibliothek | der Pädagogischen Hochschule Zürich fest | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,560 | 9,560 | ) Die Leiterin beschrieb die | Bibliothek | als „ Dritter Ort ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,577 | 9,577 | Funktion als Lernort . Die | Bibliothek | ist dann auch auf die | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,627 | 9,627 | dann auch , dass die | Bibliothek | vorrangig als ein Lernort genutzt | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,643 | 9,643 | Einzelpersonen . Offensichtlich folgte die | Bibliothek | erfolgreich der eigenen Definition eines | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,812 | 9,812 | Orte ” festgelegt wurden . | Bibliotheken | , in denen nicht kommuniziert | bibliothek* |
| [73] - Corinna Haas, Rudolf | 9,877 | 9,877 | zum Beispiel dadurch , dass | Bibliotheksnutzerinnen | und -nutzer soziale Kontrolle ausüben | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,000 | 10,000 | Forschungen zur Nutzung des Raumes | Bibliothek | ( Weis 2015 ) legen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,020 | 10,020 | diese Aufteilung schon in der | bibliothekarischen | Literatur angelegt ist oder erst | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,052 | 10,052 | Überblick über ethnografische Forschung in | Bibliotheken14 | und trug anschliessend einige weiterführende | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,065 | 10,065 | Dritten Ort als Konzept für | Bibliotheken | und Bibliotheksräume vor . Wie | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,067 | 10,067 | als Konzept für Bibliotheken und | Bibliotheksräume | vor . Wie der Überblick | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,076 | 10,076 | der Überblick über Ethnografie in | Bibliotheken | zeigte , lassen sich seit | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,097 | 10,097 | werden ethnografische Methoden in der | bibliothekarischen | Marktforschung eingesetzt , wobei Nutzerinnen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,111 | 10,111 | die Gestaltung physischer und virtueller | Bibliotheksräume | einbezogen werden ( Foster 2007 | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,160 | 10,160 | in der qualitativen Sozialforschung über | Bibliotheken | zur Anwendung , besonders in | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,167 | 10,167 | Anwendung , besonders in der | bibliothekssoziologischen | Forschung Frankreichs ( Paugam & | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,184 | 10,184 | 2010 ) . Bei der | bibliothekarischen | Marktforschung dient die ethnografische Untersuchung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,210 | 10,210 | ist die sozialwissenschaftliche Forschung in | Bibliotheken | nicht primär service- , sondern | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,272 | 10,272 | Frage stehen die Dienstleistungen der | Bibliothek | nicht notwendigerweise im Zentrum . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,552 | 10,552 | sei das Konzept jedoch für | Bibliotheken | zu eindimensional , da sie | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,612 | 10,612 | Dritten Raum ” auch in | Bibliothekskonzepte | und in die empirische Forschung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,621 | 10,621 | empirische Forschung in und über | Bibliotheken | aufzunehmen . Dies geschehe etwa | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,735 | 10,735 | dass die verbreiteten Schlagworte im | Bibliothekswesen | hinterfragt werden können und sich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,758 | 10,758 | für Entscheidungen über die zukünftige | Bibliothekspraxis | . Grundsätzlich zeigten die Forschungen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,773 | 10,773 | es nicht an Versuchen von | Bibliotheken | mangelt , sich als „ | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,824 | 10,824 | getroffen wurden , damit die | Bibliothek | ein „ Dritter Ort ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,860 | 10,860 | den Studierenden beobachtete Nutzung von | Bibliotheken | sich von den Konzepten und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,873 | 10,873 | Architektinnen und Architekten sowie der | Bibliothekarinnen | und Bibliothekare unterscheidet . Konsens | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,875 | 10,875 | Architekten sowie der Bibliothekarinnen und | Bibliothekare | unterscheidet . Konsens scheint es | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,897 | 10,897 | wenn sie sich in der | Bibliothek | wohl fühlen . Nur scheint | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,954 | 10,954 | zur Untersuchung der Nutzung von | Bibliotheken | vor , welches auf Henri | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,972 | 10,972 | die tatsächliche Wirkung des Raumes | Bibliothek | erklären lässt aus dem Zusammenspiel | bibliothek* |
| [73] - Corinna Haas, Rudolf | 10,995 | 10,995 | b ) dem Verhalten des | Bibliothekspersonals | und den Angeboten der Bibliothek | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,000 | 11,000 | Bibliothekspersonals und den Angeboten der | Bibliothek | und ( c ) dem | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,045 | 11,045 | wirken können . Der Raum | Bibliothek | in seiner Nutzung ist im | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,090 | 11,090 | Erklärungskraft zu haben . Viele | Bibliotheken | haben sich mit der Ebene | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,146 | 11,146 | Dies führt offenbar oft zu | Bibliotheken | , die als „ potentielle | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,194 | 11,194 | und Nutzer wollten , dass | Bibliotheken | „ Dritte Orte ” würden | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,210 | 11,210 | grossen Teilen mit den jetzigen | Bibliotheken | sehr zufrieden und benutzen sie | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,237 | 11,237 | Personen zu , welche die | Bibliotheken | nicht nutzen . Aber es | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,250 | 11,250 | die Frage stellen , wieso | Bibliotheken | eigentlich „ Dritte Orte ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,284 | 11,284 | es eher eine Aufforderung der | Bibliotheken | an sich selbst , offener | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,316 | 11,316 | , bei seiner Wiederentdeckung im | Bibliotheksbereich | zu einem sehr offenen Begriff | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,534 | 11,534 | mehr besprochen wird , wenn | Bibliotheken | sich auf den Begriff beziehen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,549 | 11,549 | zu fragen , welche Motive | Bibliotheken | eigentlich dazu bewegen , sich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,647 | 11,647 | aufschlussreicher , die Selbstdarstellung von | Bibliotheken | als „ Dritte Orte ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,713 | 11,713 | akzeptierte Quelle für die jeweiligen | bibliothekarischen | Strategien . Möglicherweise , so | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,727 | 11,727 | Seminarergebnisse jedenfalls nahe , verkürzen | Bibliotheken | das Konzept des „ Dritten | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,764 | 11,764 | Dritte Orte ” bezeichnen . | Bibliotheken | scheinen bemüht , mit einem | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,796 | 11,796 | wie die steigenden Nutzungszahlen vieler | Bibliotheken | und auch die Ergebnisse des | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,819 | 11,819 | und Nutzern in den untersuchten | Bibliotheken | zeigte – nicht unbedingt so | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,830 | 11,830 | , wie dies von den | Bibliotheken | intendiert wird . Gegenüber den | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,838 | 11,838 | . Gegenüber den Unterhaltsträgern der | Bibliotheken | , Politik und Öffentlichkeit fungiert | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,864 | 11,864 | die auch künftige Relevanz von | Bibliotheken | argumentieren lässt , nämlich als | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,919 | 11,919 | und Nutzer in den untersuchten | Bibliotheken | deutet zumindest darauf hin , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,944 | 11,944 | jetzigen Ausgestaltung – beispielsweise mit | Bibliotheken | , die nicht als Begegnungsort | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,974 | 11,974 | der Suche nach der eigenen | bibliothekarischen | Identität eine Rolle spielt und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 11,988 | 11,988 | nach innen , in die | Bibliotheken | hinein , wirkt . Zur | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,031 | 12,031 | die insbesondere in der skandinavischen | Bibliotheksszene | erhoben wird , aber auch | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,063 | 12,063 | Funktionswandel der ( Öffentlichen ) | Bibliothek | propagiert , in den sich | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,110 | 12,110 | an , die Entwicklung von | Bibliotheken | sowohl voranzutreiben als auch zu | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,190 | 12,190 | ( 2015 ) . Die | Bibliothek | als Dritter Ort : Bibliotheken | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,195 | 12,195 | Bibliothek als Dritter Ort : | Bibliotheken | müssen mehr als Ausleihstellen sein | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,225 | 12,225 | ( 2014a ) . Die | Bibliothek | als Dritter Ort : Wenn | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,231 | 12,231 | als Dritter Ort : Wenn | Bibliotheken | im 21 . Jahrhundert bestehen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,301 | 12,301 | ( 2014 ) . Das | Bibliothekscafé | als dritter Ort : Praxis-Untersuchungen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,316 | 12,316 | die Beeinflussungsmöglichkeiten zwischen einer öffentlichen | Bibliothek | und einem Café in den | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,341 | 12,341 | ) . „ Ist die | Bibliothek | der Pädagogischen Hochschule Zürich ein | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,402 | 12,402 | ) . Familien in der | Bibliothek | : Eine Fallanalyse der Freihandbibliothek | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,437 | 12,437 | 2015 ) . Dritter Ort | Bibliothek | : Untersuchung in der Kinder- | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,459 | 12,459 | ( 2015 ) . Sind | Bibliotheken | ein dritter Ort ? ( | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,503 | 12,503 | 2013 ) . Das neue | Bibliotheksgesetz | des Kantons St . Gallen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,515 | 12,515 | Ein Impuls für die schweizerische | Bibliotheksgesetzgebung | . In : LIBREAS . | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,538 | 12,538 | ( 2010 ) . Die | Bibliothek | auf dem Weg zum „ | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,588 | 12,588 | Annäherungen an den Raum der | Bibliothek | . In : Ulrich , | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,603 | 12,603 | Hrsg . ) : Die | Bibliothek | als öffentlicher Ort und öffentlicher | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,646 | 12,646 | Ort ? : Der enthierarchisierte | Bibliotheksraum | / Plattform für die Vermittlung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,756 | 12,756 | ) . Wozu Ethnografie in | Bibliotheken | ? In : Bibliothek Forschung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,760 | 12,760 | in Bibliotheken ? In : | Bibliothek | Forschung und Praxis 38 ( | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,782 | 12,782 | . Ein komplexes Ganzes : | Bibliotheken | sind mehr als Dritte Orte | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,800 | 12,800 | In : BuB . Forum | Bibliothek | und Information 7 ( 2015 | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,890 | 12,890 | ) . Seminar : „ | Bibliothek | als Dritter Ort ” am | bibliothek* |
| [73] - Corinna Haas, Rudolf | 12,925 | 12,925 | 2015 ) . Ist die | Bibliothek | Hauptpost in St . Gallen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,000 | 13,000 | Wozu benutzen ältere Personen eine | Bibliothek | ? ( Bachelorarbeit HTW Chur | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,066 | 13,066 | ( 2015 ) . Sind | Bibliotheken | Dritte Orte : Empirische Nutzerforschung | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,358 | 13,358 | . Berlin : Institut für | Bibliotheks- | und Informationswissenschaft der Humboldt-Universität zu | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,372 | 13,372 | . ( Berliner Handreichungen zur | Bibliotheks- | und Informationswissenschaft ; 277 ) | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,432 | 13,432 | Service nach Maß – Eine | Bibliothek | für die Informationskultur der Studierenen | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,576 | 13,576 | 2015 ) . Ist die | Bibliothek | ein Dritter Ort ? : | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,585 | 13,585 | ? : Forschung in der | Bibliothek | Hauptpost St . Gallen und | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,716 | 13,716 | 2015 ) . Aufenthalt in | Bibliotheken | . Berlin : Institut für | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,722 | 13,722 | . Berlin : Institut für | Bibliotheks- | und Informationswissenschaft der Humboldt-Universität zu | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,733 | 13,733 | Berlin ( Berliner Handreichungen zur | Bibliotheks- | und Informationswissenschaft ; 390 ) | bibliothek* |
| [73] - Corinna Haas, Rudolf | 13,957 | 13,957 | Vortrag beim Symposium „ Die | Bibliothek | als Idee ” der LIBREAS | bibliothek* |
| [73] - Corinna Haas, Rudolf | 14,008 | 14,008 | Dies lässt sich aus den | bibliothekarischen | Quellen nicht bestätigen , diese | bibliothek* |
| [73] - Corinna Haas, Rudolf | 14,435 | 14,435 | es erstaunlich , wenn in | bibliothekarischen | Texten „ Third Place ” | bibliothek* |
| [73] - Corinna Haas, Rudolf | 15,071 | 15,071 | sind das Netz der Öffentlichen | Bibliotheken | in Zürich und umfassen aktuell | bibliothek* |
| [74] - Rudolf Mumenthaler, | 196 | 196 | 2012 Verantwortlicher für die Vertiefung | Bibliothekswissenschaft | . 1 Einleitung 2 Vorgehen | bibliothek* |
| [74] - Rudolf Mumenthaler, | 231 | 231 | den Major 7.1 Der Major | Bibliotheksmanagement | 7.2 Der Major Informations- und | bibliothek* |
| [74] - Rudolf Mumenthaler, | 411 | 411 | zusätzlich zu den bestehenden Vertiefungen | Bibliothekswissenschaft | , Records Management und Archivierung | bibliothek* |
| [74] - Rudolf Mumenthaler, | 886 | 886 | , ein moderneres Berufsbild des | Bibliothekars | / der Bibliothekarin zu vermitteln | bibliothek* |
| [74] - Rudolf Mumenthaler, | 889 | 889 | Berufsbild des Bibliothekars / der | Bibliothekarin | zu vermitteln , denn von | bibliothek* |
| [74] - Rudolf Mumenthaler, | 916 | 916 | und dass sie innerhalb der | Bibliotheken | die Rolle von Innovationsträgern spielen | bibliothek* |
| [74] - Rudolf Mumenthaler, | 966 | 966 | Informationsbranche auszubilden . Fächer wie | Bibliotheksinformatik | , Data Science , Usability | bibliothek* |
| [74] - Rudolf Mumenthaler, | 1,621 | 1,621 | Major definiert und benannt : | Bibliotheksmanagement | , Informations- und Medienmanagement , | bibliothek* |
| [74] - Rudolf Mumenthaler, | 1,941 | 1,941 | . Standards und Regelwerke im | Bibliotheksbereich | ) und auch die Umsetzung | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,136 | 2,136 | sollen . Studierende im Major | Bibliotheksmanagement | werden sich entsprechend mit Digitalisierung | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,175 | 2,175 | Usability-Engineering werden hingegen das Modul | Bibliotheks- | und Archivinformatik aus dem Major | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,181 | 2,181 | und Archivinformatik aus dem Major | Bibliotheksmanagement | belegen . Hinzu kommen schliesslich | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,263 | 2,263 | Major-übergreifender Projektkurs . Der Major | Bibliotheksmanagement | befasst sich mit der Erwerbung | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,281 | 2,281 | , Management und Bau von | Bibliotheken | , mit modernen Dienstleistungen , | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,299 | 2,299 | Stellen in Öffentlichen und Wissenschaftlichen | Bibliotheken | . Folgende einschlägige Module sind | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,307 | 2,307 | einschlägige Module sind vorgesehen : | Bibliotheksdienstleistungen | Standards und Regelwerke Bestand , | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,316 | 2,316 | Bestand , Medien und Wissenschaftskommunikation | Bibliotheksmanagement | und Bibliotheksbau Aktuelle Trends in | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,318 | 2,318 | Medien und Wissenschaftskommunikation Bibliotheksmanagement und | Bibliotheksbau | Aktuelle Trends in Bibliothekswissenschaft und | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,322 | 2,322 | und Bibliotheksbau Aktuelle Trends in | Bibliothekswissenschaft | und -praxis Informationsvermittlung Bibliotheks- und | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,326 | 2,326 | in Bibliothekswissenschaft und -praxis Informationsvermittlung | Bibliotheks- | und Archivinformatik Der Major Informations- | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,464 | 2,464 | Digitale Langzeitarchivierung Digitalisierung Quellenkunde Preservation | Bibliotheks- | und Archivinformatik Web und Usability | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,894 | 2,894 | . Direktorinnen und Direktoren von | Bibliotheken | , Archiven , Leiterinnen und | bibliothek* |
| [74] - Rudolf Mumenthaler, | 2,943 | 2,943 | und wird von den Verbänden | Bibliothek | Information Schweiz ( BIS ) | bibliothek* |
| [75] - Christian Hauschke, | 3,311 | 3,311 | URL : http://dx.doi.org/10.1002/pds.3805. Christian HAUSCHKE | Bibliothek | der Hochschule Hannover , Ricklinger | bibliothek* |
| [76] - Jens Ambacher, Gabri | 33 | 33 | zum Thema " Armut und | Bibliotheken | " , der auf dem | bibliothek* |
| [76] - Jens Ambacher, Gabri | 39 | 39 | " , der auf dem | Bibliothekstag | 2015 in Nürnberg durchgeführt wurde | bibliothek* |
| [76] - Jens Ambacher, Gabri | 61 | 61 | zu den Themen " Können | Bibliotheken | Menschen in Armut dabei helfen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 77 | 77 | ? " , " Können | Bibliotheken | Menschen in Armut dabei helfen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 93 | 93 | ? " und " Können | Bibliotheken | Kinder und Jugendliche in Armut | bibliothek* |
| [76] - Jens Ambacher, Gabri | 172 | 172 | angedacht . Armut , Öffentliche | Bibliothek | , Soziale Gerechtigkeit , Stigmatisierung | bibliothek* |
| [76] - Jens Ambacher, Gabri | 346 | 346 | den drei Tischen 2.1 Können | Bibliotheken | Menschen in Armut dabei helfen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 367 | 367 | Karsten Schuldt ) 2.2 Können | Bibliotheken | Menschen in Armut dabei helfen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 388 | 388 | Gabriele Fahrenkrog ) 2.3 Können | Bibliotheken | Kinder und Jugendliche in Armut | bibliothek* |
| [76] - Jens Ambacher, Gabri | 411 | 411 | von Armut / Problembewusstsein der | Bibliotheksangestellten | ? 2.3.2 Situation der Familien | bibliothek* |
| [76] - Jens Ambacher, Gabri | 446 | 446 | nur der Kinder ) 2.3.6 | Bibliothek | als Ort erleben 2.3.7 „ | bibliothek* |
| [76] - Jens Ambacher, Gabri | 452 | 452 | als Ort erleben 2.3.7 „ | Bibliothekssterben | “ 2.3.8 Partizipation der Kinder | bibliothek* |
| [76] - Jens Ambacher, Gabri | 476 | 476 | einem Vortrag auf dem Deutschen | Bibliothekartag | 2014 in Bremen und Diskussionen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 487 | 487 | , die auf dem schweizerischen | Bibliothekskongress | 2014 in Lugano begannen , | bibliothek* |
| [76] - Jens Ambacher, Gabri | 501 | 501 | dieses Berichtes auf dem Deutschen | Bibliothekartag | 2015 in Nürnberg , mithilfe | bibliothek* |
| [76] - Jens Ambacher, Gabri | 522 | 522 | zum Thema „ Armut und | Bibliotheken | “ . Grundidee hinter diesem | bibliothek* |
| [76] - Jens Ambacher, Gabri | 564 | 564 | Kolleginnen und Kollegen in den | Bibliotheken | ein weit verbreitetes Interesse daran | bibliothek* |
| [76] - Jens Ambacher, Gabri | 579 | 579 | nachzudenken , ob und was | Bibliotheken | für Menschen in Armut leisten | bibliothek* |
| [76] - Jens Ambacher, Gabri | 681 | 681 | drei Fragen diskutiert : Können | Bibliotheken | Menschen in Armut dabei helfen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 694 | 694 | Alltag zu gestalten ? Können | Bibliotheken | Menschen in Armut dabei helfen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 707 | 707 | der Armut auszusteigen ? Können | Bibliotheken | Kinder und Jugendliche in Armut | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,079 | 1,079 | Themenkomplex ' obdachlose Menschen und | Bibliotheken | ' , der oft angesprochen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,155 | 1,155 | aber nicht nur ) Öffentliche | Bibliotheken | im Alltag von Menschen in | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,271 | 1,271 | beispielsweise eine kostenlose Benutzung von | Bibliotheken | . Mit dem kostenlosen Zugang | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,278 | 1,278 | Mit dem kostenlosen Zugang würden | Bibliotheken | auch ihrem Grundauftrag , qualitativ | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,373 | 1,373 | Dimensionen sinnvoll , beispielsweise wenn | Bibliotheken | mit einem offenen Klima dabei | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,395 | 1,395 | . Dafür müsse aber die | Bibliothek | auch erreichbar sein , was | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,472 | 1,472 | betroffenen Menschen die Angebote von | Bibliotheken | nicht unbedingt bekannt sind und | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,497 | 1,497 | Ebenso wurde vermutet , dass | Bibliotheken | für viele weiterhin als Einrichtungen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,535 | 1,535 | wieder wurde geäussert , dass | Bibliotheken | , um für Menschen in | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,557 | 1,557 | sollten , teilweise um dort | bibliothekarische | Angebote zu unterbreiten – zum | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,694 | 1,694 | Schulbus einen ( kostenlosen ) | Bibliotheksbus | einrichten – ein Bus , | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,710 | 1,710 | Quartieren abholt , in die | Bibliothek | bringt und später wieder zurück | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,760 | 1,760 | ob Personen in Armut in | Bibliotheken | eigentlich wirklich willkommen seien . | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,797 | 1,797 | , ob sie den Raum | Bibliothek | nach ihrem Gutdünken nutzen oder | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,860 | 1,860 | Konsens bestand darin , dass | Bibliotheken | hier nur in Kooperation mit | bibliothek* |
| [76] - Jens Ambacher, Gabri | 1,943 | 1,943 | sich als Ergänzung zu den | Bibliotheken | : dort , wo der | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,051 | 2,051 | die Ausstattung / Infrastruktur von | Bibliotheken | angesehen . Sie steht potenziell | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,122 | 2,122 | . Weitere konkrete Angebote von | Bibliotheken | für Menschen in Armut seien | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,157 | 2,157 | könnten . Die Verantwortlichen in | Bibliotheken | sollten sich bei der Politik | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,183 | 2,183 | findet die Diskussion um soziale | Bibliotheksarbeit | allerdings in der Fachcommunity faktisch | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,270 | 2,270 | sehr zeitaufwändig . Gerade kleinere | Bibliotheken | mit dünner Personaldecke stoßen hier | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,329 | 2,329 | Urlaubsreisen leisten kann . Damit | Bibliotheken | nachhaltig dazu beitragen können , | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,366 | 2,366 | es den Einwand , dass | Bibliotheken | immer dort auch an andere | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,385 | 2,385 | selbst nicht weiterhelfen können . | Bibliotheken | dienten somit eher als Auskunftsstelle | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,455 | 2,455 | und Raum gestellt ? In | Bibliotheken | sollten die Schwellen zur Nutzung | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,482 | 2,482 | In einigen Kommunen ist der | Bibliotheksausweis | beispielsweise Teil des Kulturpasses , | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,513 | 2,513 | . „ Buchen Sie einen | Bibliothekar | ” wurde als eine Möglichkeit | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,574 | 2,574 | ist ein Problem in vielen | Bibliotheken | . Oft haben Nutzende heikle | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,606 | 2,606 | Nutzerinnen und Nutzer in der | Bibliothek | sogenannte „ Diskretionskärtchen ” nehmen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,677 | 2,677 | im Hinblick darauf , was | Bibliotheken | konkret leisten können , um | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,729 | 2,729 | sich , ob sich die | Bibliotheksangestellten | des möglichen Armutsproblems ihrer Nutzerinnen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,746 | 2,746 | gilt , die Mitarbeitenden der | Bibliothek | zu sensibilisieren . Es braucht | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,784 | 2,784 | mit ihren Kindern in die | Bibliothek | kommen . Die Eltern versuchen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,809 | 2,809 | nehmen dabei die Angebote der | Bibliotheken | oft gerne an , allerdings | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,949 | 2,949 | , dass dies in der | Bibliothek | – vorerst – ohne Lesebezug | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,960 | 2,960 | geschehen kann , indem die | Bibliothek | als Ort zum Sein und | bibliothek* |
| [76] - Jens Ambacher, Gabri | 2,975 | 2,975 | vergleiche auch den Abschnitt „ | Bibliothek | als Ort erleben “ ) | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,013 | 3,013 | werden , umso mehr als | Bibliotheken | für buch- und leseferne Familien | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,036 | 3,036 | sind . Vorschlag : Die | Bibliothek | sollte eigene Elternabende anbieten und | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,082 | 3,082 | ihren Kindern untersagen , die | Bibliothek | zu besuchen und Medien auszuleihen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,138 | 3,138 | dass als Einstieg in die | Bibliothek | Klassensätze oder Themenkisten ausgeliehen werden | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,218 | 3,218 | , dass die Betroffenen die | Bibliothek | nicht aus Kostengründen meiden . | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,334 | 3,334 | aber auch eine Stigmatisierung der | Bibliotheksangestellten | geben ( zum Beispiel innerhalb | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,341 | 3,341 | ( zum Beispiel innerhalb des | Bibliotheksteams | ) , die sich für | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,438 | 3,438 | Eltern nicht nur in die | Bibliothek | kommen , um für ihre | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,462 | 3,462 | den Eltern Lust auf die | Bibliothek | zu machen und sie , | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,535 | 3,535 | Erfahrung zeigt , dass die | Bibliothek | zu oft noch eine Hemmschwelle | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,565 | 3,565 | erfahren Menschen in Armut vom | bibliothekarischen | Angebot für sie ? Zum | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,605 | 3,605 | die Menschen nicht in die | Bibliothek | kommen , muss die Bibliothek | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,610 | 3,610 | Bibliothek kommen , muss die | Bibliothek | zu den Leuten hingehen und | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,667 | 3,667 | werden , um in die | Bibliothek | zu kommen . Die direkte | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,676 | 3,676 | Die direkte Begegnung mit den | Bibliotheksangestellten | und der Austausch sind wichtig | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,684 | 3,684 | Austausch sind wichtig . Die | Bibliothek | ist für Kinder und Jugendliche | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,718 | 3,718 | es keinen Platz hat . | Bibliotheken | bieten sich an als Lernorte | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,776 | 3,776 | , gibt es teils erweiterte | Bibliotheksangebote | : Zum Beispiel Sommerlesekurse oder | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,787 | 3,787 | andere Bücher-bezogene Angebote . Die | Bibliothek | bleibt während den Ferien als | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,813 | 3,813 | ) . Kulturangebote in den | Bibliotheken | sind im Trend ( ein | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,822 | 3,822 | ( ein Problem für die | Bibliotheken | sind jedoch die wachsenden Personalkosten | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,836 | 3,836 | ist , wenn sich die | Bibliothek | bei möglichst vielen Menschen als | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,874 | 3,874 | „ Ich ging in die | Bibliothek | , weil sie da war | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,885 | 3,885 | “ . Die Erreichbarkeit der | Bibliothek | ist wesentlich wichtig , gerade | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,904 | 3,904 | sie ab , in die | Bibliothek | zu gehen . Kinder und | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,921 | 3,921 | . Für Jugendliche kann die | Bibliothek | unter Umständen auch ein Treffpunkt | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,941 | 3,941 | ) . Aber viele kleine | Bibliotheken | wurden eingespart oder zu einer | bibliothek* |
| [76] - Jens Ambacher, Gabri | 3,971 | 3,971 | Benutzerinnen und Benutzer abschreckt . | Bibliotheksbusse | bieten teils Ersatz , aber | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,009 | 4,009 | und brauchen und wie ihre | Bibliothek | aussehen soll . Es wurden | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,053 | 4,053 | ab 3-jährig können in der | Bibliothek | abgeholt werden ( was Eltern | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,061 | 4,061 | ( was Eltern in die | Bibliothek | führt ) . Mit Kitas | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,090 | 4,090 | regulären Öffnungszeit ) könnte die | Bibliothek | nur für Kitas zur Verfügung | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,118 | 4,118 | Erinnerung an den Besuch der | Bibliothek | gemacht . Mit Schulen : | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,162 | 4,162 | zu erreichen . „ Die | Bibliothek | ist nicht für behinderte Kinder | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,182 | 4,182 | . Andererseits kann seitens der | Bibliothek | zum Beispiel einmal im Monat | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,270 | 4,270 | gehöre dir “ der örtlichen | Bibliothek | in Trams , Bussen , | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,331 | 4,331 | Teilnehmenden auf Erfahrungen aus unterschiedlichen | Bibliotheken | , Städten und Gemeinden unterschiedlicher | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,399 | 4,399 | von gesellschaftlichen Einrichtungen oder Öffentlicher | Bibliotheken | niederschlägt . Insoweit sind die | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,452 | 4,452 | Konsens vorherrschte , dass sich | Bibliotheken | mit dem Thema Armut und | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,472 | 4,472 | vielfältigen anderen Möglichkeiten auf dem | Bibliothekartag | war es allerdings bemerkenswert , | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,518 | 4,518 | darauf hingewiesen , dass viele | Bibliotheken | schon viele Angebote unterbreiten oder | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,526 | 4,526 | Angebote unterbreiten oder die alltägliche | Bibliotheksarbeit | so ausrichten , dass Menschen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,558 | 4,558 | das schon vorhandene Wissen aus | Bibliotheken | sichtbarer zu machen . Es | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,633 | 4,633 | Sozialwissenschaft – erarbeitete Wissen im | Bibliothekswesen | zu verbreiten . Nicht zuletzt | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,650 | 4,650 | über Armut , das in | Bibliotheken | genutzt werden könnte . Einerseits | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,667 | 4,667 | , die sich direkt mit | Bibliotheken | beschäftigen , selten , andererseits | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,713 | 4,713 | in Armut , wenn sie | Bibliotheken | nutzen sollen , nicht stigmatisiert | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,775 | 4,775 | scheint es die Aufgabe von | Bibliotheken | zu sein , Angebote zu | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,933 | 4,933 | Ebenso übergreifend gelten Kooperationen von | Bibliotheken | mit unterschiedlichen Einrichtungen , denen | bibliothek* |
| [76] - Jens Ambacher, Gabri | 4,988 | 4,988 | es sinnvoll , wenn sich | Bibliotheken | vor einer Kooperation über die | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,086 | 5,086 | genannt wurden : Was sollen | Bibliotheken | und Kooperationspartner genau tun ? | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,129 | 5,129 | schon viele Erfahrungen in einzelnen | Bibliotheken | vorliegen , die sichtbar gemacht | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,145 | 5,145 | auch erwähnt , dass die | Bibliotheken | nicht unbedingt der Ort sein | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,249 | 5,249 | gezeigt , dass das Thema | Bibliotheken | und Armut oder genauer von | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,269 | 5,269 | sinnvolles Thema für die weitere | bibliothekarische | Arbeit angesehen wird . In | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,290 | 5,290 | wobei Menschen in Armut durch | Bibliotheken | unterstützt werden können , gibt | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,312 | 5,312 | , ( a ) dass | Bibliotheken | eine Rolle im Leben von | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,396 | 5,396 | Eindruck vor , dass viele | Bibliotheken | schon Angebote entwickelt haben , | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,434 | 5,434 | eine Mailingliste “ Armut und | Bibliotheken | ” eingerichtet , die eine | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,466 | 5,466 | ist unter ' Armut und | Bibliotheken | ' zu finden , dort | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,486 | 5,486 | um ein verstärktes Engagement von | Bibliotheken | zur Unterstützung von Flüchtlingen schliesst | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,496 | 5,496 | schliesst nahtlos an die am | Bibliothekartag | erörterten Themen an . Jens | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,546 | 5,546 | rudolf.mumenthaler@htwchur.ch Ruth SCHAFFER WÜTHRICH , | Bibliothek | im Kunstmuseum Bern , Hodlerstrasse | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,573 | 5,573 | und ist heute Leiterin der | Bibliothek | im Kunstmuseum Bern . ) | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,649 | 5,649 | 2015 ) . Armut und | Bibliotheken | – wie erfolgreich kann die | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,655 | 5,655 | – wie erfolgreich kann die | bibliothekarische | Arbeit für Menschen in Armut | bibliothek* |
| [76] - Jens Ambacher, Gabri | 5,670 | 5,670 | ] . 104 . Deutscher | Bibliothekartag | in Nürnberg 2015 , https://opus4.kobv.de/opus4-bib-info/frontdoor/index/index/docId/1879 | bibliothek* |
| [77] - Dörte Böhner, Gabrie | 438 | 438 | dem ermunternden Treffen beim Bremer | Bibliothekartag | . Doch wir wollen Sie | bibliothek* |
| [77] - Dörte Böhner, Gabrie | 513 | 513 | haben Möglichkeiten und Grenzen der | Bibliothekspolitik | in der Schweiz untersucht , | bibliothek* |
| [77] - Dörte Böhner, Gabrie | 550 | 550 | untersucht die Barrierefreiheit in Digitalen | Bibliotheken | . Angesichts der Relevanz des | bibliothek* |
| [77] - Dörte Böhner, Gabrie | 814 | 814 | im Museum , in der | Bibliothek | , im Archiv oder an | bibliothek* |
| [78] - Rudolf Mumenthaler, | 32 | 32 | wurden Möglichkeiten und Grenzen von | Bibliothekspolitik | in der Schweiz erläutert . | bibliothek* |
| [78] - Rudolf Mumenthaler, | 72 | 72 | und diskutiert , wie sich | Bibliotheken | aktiv beteiligen können . Im | bibliothek* |
| [78] - Rudolf Mumenthaler, | 120 | 120 | geeigneten politischen Instrumente für die | Bibliothek | einsetzen . Die Mobilisierung der | bibliothek* |
| [78] - Rudolf Mumenthaler, | 138 | 138 | klar auf der Seite der | Bibliotheksanliegen | war , ist dabei ein | bibliothek* |
| [78] - Rudolf Mumenthaler, | 147 | 147 | dabei ein entscheidender Erfolgsfaktor . | Bibliothek | ; Bibliothekspolitik ; Netzwerk ; | bibliothek* |
| [78] - Rudolf Mumenthaler, | 149 | 149 | entscheidender Erfolgsfaktor . Bibliothek ; | Bibliothekspolitik | ; Netzwerk ; Einflussanalyse The | bibliothek* |
| [78] - Rudolf Mumenthaler, | 313 | 313 | und Akteure 3.5 Einflussanalyse 3.6 | Bibliotheksverband | 4 Fazit Quellen Autoren Folgender | bibliothek* |
| [78] - Rudolf Mumenthaler, | 357 | 357 | . Thema des Seminars war | Bibliothekspolitik | , insbesondere Aktivitäten gegen die | bibliothek* |
| [78] - Rudolf Mumenthaler, | 366 | 366 | gegen die geplante Schließung von | Bibliotheken | . Ziel war es , | bibliothek* |
| [78] - Rudolf Mumenthaler, | 393 | 393 | politischen Aktivitäten zum Erhalt von | Bibliotheken | gab . Auf der Basis | bibliothek* |
| [78] - Rudolf Mumenthaler, | 404 | 404 | dieser Struktur sollten Empfehlungen für | Bibliotheken | gegeben werden , die sich | bibliothek* |
| [78] - Rudolf Mumenthaler, | 422 | 422 | betrachtet wurden andere Formen der | Bibliothekspolitik | , beispielsweise im Kontext von | bibliothek* |
| [78] - Rudolf Mumenthaler, | 483 | 483 | Proteste gegen die Schließung von | Bibliotheken | in Berlin ( Schuldt 2008a | bibliothek* |
| [78] - Rudolf Mumenthaler, | 502 | 502 | Vortrag zur Politik hinter der | Bibliotheksinitiative | St . Gallen im schweizerischen | bibliothek* |
| [78] - Rudolf Mumenthaler, | 531 | 531 | Protesten sowie erste Strukturen der | Bibliothekspolitik | im Bezug auf diese Proteste | bibliothek* |
| [78] - Rudolf Mumenthaler, | 578 | 578 | Beispiel der geplanten Schließung der | Bibliothek | Ruopigen keine Dokumentation gibt , | bibliothek* |
| [78] - Rudolf Mumenthaler, | 595 | 595 | kurz erläutert : Bei der | Bibliothek | Ruopigen handelt es sich um | bibliothek* |
| [78] - Rudolf Mumenthaler, | 641 | 641 | der Luzerner Stadtrat , die | Bibliothek | zu schließen . Im Parlament | bibliothek* |
| [78] - Rudolf Mumenthaler, | 655 | 655 | angenommen , die Schließung der | Bibliothek | nicht diskutiert . Aktiv wurde | bibliothek* |
| [78] - Rudolf Mumenthaler, | 726 | 726 | ähnliche Proteste für andere schweizerische | Bibliotheken | analysieren . In einem Prozess | bibliothek* |
| [78] - Rudolf Mumenthaler, | 759 | 759 | angesprochene Empfehlung für die schweizerischen | Bibliotheken | entstehen , wobei davon ausgegangen | bibliothek* |
| [78] - Rudolf Mumenthaler, | 792 | 792 | Beispiele für diese Form von | Bibliothekspolitik | besprochen , beispielsweise das Advocacy | bibliothek* |
| [78] - Rudolf Mumenthaler, | 825 | 825 | für Proteste zum Erhalt von | Bibliotheken | finden lassen . Die Studierenden | bibliothek* |
| [78] - Rudolf Mumenthaler, | 850 | 850 | Luzern , den Umbau von | Bibliotheken | sowie einen schon seit längerer | bibliothek* |
| [78] - Rudolf Mumenthaler, | 880 | 880 | trotz aller negativen Vermutung in | bibliothekarischen | Diskussionen , die Situation zumindest | bibliothek* |
| [78] - Rudolf Mumenthaler, | 888 | 888 | die Situation zumindest für Öffentliche | Bibliotheken | ( Gemeindebibliotheken und Schulbibliotheken ) | bibliothek* |
| [78] - Rudolf Mumenthaler, | 911 | 911 | offenbar weniger darum , ob | Bibliotheken | geschlossen werden , sondern ob | bibliothek* |
| [78] - Rudolf Mumenthaler, | 972 | 972 | aus denen sich Empfehlungen für | Bibliotheken | ableiten lassen . Bibliothekspolitik , | bibliothek* |
| [78] - Rudolf Mumenthaler, | 976 | 976 | für Bibliotheken ableiten lassen . | Bibliothekspolitik | , so zumindest der Eindruck | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,021 | 1,021 | Akteuren und Akteurinnen auch über | Bibliotheken | entschieden , ohne diese in | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,046 | 1,046 | der Wahrnehmung von Öffentlichkeit und | Bibliotheken | . Zwar gibt es in | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,196 | 1,196 | . Grundsätzlich scheint es für | Bibliotheken | sinnvoll zu sein , die | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,244 | 1,244 | Parlamenten Personen , welche die | Bibliothek | aktiv darauf hinweisen , wenn | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,274 | 1,274 | oben schon erwähnt , haben | Bibliotheken | in der Schweiz einen relativ | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,297 | 1,297 | werden über den Kopf der | Bibliotheken | hinweg verändert , Entscheidungen über | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,306 | 1,306 | Entscheidungen über den Ausbau von | Bibliotheken | getroffen , ohne die Notwendigkeit | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,314 | 1,314 | ohne die Notwendigkeit mit den | Bibliotheken | selber zu besprechen . Bislang | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,323 | 1,323 | . Bislang führt dies für | Bibliotheken | in der Schweiz zu guten | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,350 | 1,350 | bleiben muss . Gleichzeitig sind | Bibliotheken | so nur wenig in der | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,426 | 1,426 | Dora die erfolgreiche Strategie der | Bibliotheksinitiative | St . Gallen mit “ | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,482 | 1,482 | nicht auf einem Netzwerk der | Bibliothek | , wobei bei diesem Verein | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,622 | 1,622 | heissen , Entscheidungen über die | Bibliotheksentwicklung | an solche formalisierten Netzwerke abzutreten | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,674 | 1,674 | GP ) grundsätzlich für die | Bibliotheken | eintraten und stimmten , die | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,703 | 1,703 | eher gegen die Interessen der | Bibliotheken | argumentierten . Entscheidend für den | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,763 | 1,763 | Vertreter der SVP für bestimmte | Bibliotheken | eintraten . Offenbar spielen lokale | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,777 | 1,777 | bestimmte Argumentationen – beispielsweise die | Bibliothek | als Ort der Traditionspflege – | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,787 | 1,787 | – für die Haltung zu | Bibliotheken | eine Rolle . Während sich | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,793 | 1,793 | eine Rolle . Während sich | Bibliotheken | also in gewisser Weise auf | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,836 | 1,836 | dies auch , dass die | Bibliotheken | in den grösseren Städten eine | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,907 | 1,907 | allerdings die Frage , wie | Bibliotheken | im ländlichen Raum darauf reagieren | bibliothek* |
| [78] - Rudolf Mumenthaler, | 1,975 | 1,975 | die Meinung vor , dass | Bibliotheken | solche Argumentationen für alle politischen | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,029 | 2,029 | ihre Interventionen parlamentarische Mittel ( | Bibliotheksinitiative | St . Gallen die Volksinitiative | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,179 | 2,179 | . Gallen hat die dortige | Bibliotheksinitiative | den Weg über eine kantonale | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,192 | 2,192 | das ursprüngliche Ziel , einen | Bibliotheksneubau | in der Stadt St . | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,226 | 2,226 | . Im Ergebnis ist ein | Bibliotheksgesetz | geschaffen worden , das die | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,387 | 2,387 | Rückzug des Schliessungsentscheids der lokalen | Bibliotheksfiliale | gezwungen . Bei der Analyse | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,407 | 2,407 | auf : Die jeweils betroffenen | Bibliothekarinnen | und Bibliothekare sind nur selten | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,409 | 2,409 | Die jeweils betroffenen Bibliothekarinnen und | Bibliothekare | sind nur selten aktiv beteiligt | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,465 | 2,465 | die von Entscheidungen bezüglich ihrer | Bibliothek | betroffen sind , auch öffentlich | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,561 | 2,561 | in der Abwendung einer geplanten | Bibliotheksfusion | in Köniz . Bis zum | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,636 | 2,636 | die nicht in der betroffenen | Bibliothek | beschäftigt sind – was nicht | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,650 | 2,650 | dass sie nicht anderswo als | Bibliothekarinnen | oder Bibliothekare arbeiten – , | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,652 | 2,652 | nicht anderswo als Bibliothekarinnen oder | Bibliothekare | arbeiten – , die Interventionen | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,660 | 2,660 | , die Interventionen zugunsten von | Bibliotheken | zu initiieren . Dass dabei | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,691 | 2,691 | von politischen Entscheidungen , die | Bibliotheken | betreffen , haben , ist | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,710 | 2,710 | , den man sich als | Bibliothek | oder Aktive und Aktiver in | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,729 | 2,729 | werden , dass Aktivitäten für | Bibliotheken | erst dann begonnen werden , | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,772 | 2,772 | den Personen , welche die | Bibliotheken | benutzen , aber wenig Einfluss | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,845 | 2,845 | führt zu fragen , ob | Bibliotheken | sich stärker für eigene Anliegen | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,872 | 2,872 | die Bevölkerung den Anliegen der | Bibliotheken | grundsätzlich positiv gegenübersteht . Es | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,899 | 2,899 | . Nur fällt es den | Bibliotheken | und ihren Interessenvertretern oft schwer | bibliothek* |
| [78] - Rudolf Mumenthaler, | 2,961 | 2,961 | leicht für die Anliegen der | Bibliothek | gewinnen zu lassen . Im | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,032 | 3,032 | hier festhalten , dass für | Bibliotheken | die Einflussnahme über einen gut | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,047 | 3,047 | ist . Zudem dürften über | bibliotheksfreundliche | Parlamentarierinnen und Parlamentarier die Parlamente | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,130 | 3,130 | nach der möglichen Rolle des | Bibliotheksverbandes | . Der Verband Bibliothek Information | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,134 | 3,134 | des Bibliotheksverbandes . Der Verband | Bibliothek | Information Schweiz ( BIS ) | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,159 | 3,159 | Möglichkeiten , die Situation von | Bibliotheken | zu verbessern . ( Canadian | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,171 | 3,171 | Association , 2012 ) Eine | Bibliotheksinitiative | Schweiz , die an den | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,187 | 3,187 | anschliessen und in anderen Kantonen | Bibliotheksgesetze | initiieren wollte , scheint eingestellt | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,215 | 3,215 | Personen für ein Engagement für | Bibliotheken | motivieren . Klar wurde im | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,227 | 3,227 | des Seminars , dass der | Bibliotheksverband | allein Initiativen nicht erfolgreich lancieren | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,256 | 3,256 | , mit dem sich der | Bibliotheksverband | in solche Prozesse einbringen könnte | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,287 | 3,287 | . Auch die Rolle des | Bibliotheksverbandes | blieb am Ende offen , | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,309 | 3,309 | wird , die mit den | Bibliotheken | gemeinsam entwickelt werden muss . | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,335 | 3,335 | in politische Prozesse , die | Bibliotheken | betreffen , kaum dokumentiert werden | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,411 | 3,411 | der eigenen politischen Möglichkeiten unter | Bibliotheken | verbreiteten . Wenn sichtbar wird | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,419 | 3,419 | Wenn sichtbar wird , dass | Bibliotheken | Möglichkeiten haben , in die | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,517 | 3,517 | Strukturen auf die Möglichkeiten von | Bibliothekspolitik | auswirken . Zudem waren die | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,527 | 3,527 | die Entscheidungen im Bezug auf | Bibliotheken | in der Schweiz immer wieder | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,603 | 3,603 | wie sich dies auf die | Bibliothekspolitik | auswirkt . Zusammenfassen lassen sich | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,612 | 3,612 | lassen sich die Erkenntnisse über | Bibliotheksproteste | , die im Rahmen des | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,625 | 3,625 | wurden , wie folgt : | Bibliotheksproteste | sind erfolgreich , wenn sie | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,659 | 3,659 | . So scheinen zum Beispiel | Bibliotheksbesetzungen | in der Schweiz eher kein | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,683 | 3,683 | ein probates Mittel . Erfolgreiche | Bibliotheksproteste | sind oft das Ergebnis einer | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,724 | 3,724 | immer zusätzliche Arbeit für die | Bibliothek | . Die betroffenen Bibliothekarinnen und | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,728 | 3,728 | die Bibliothek . Die betroffenen | Bibliothekarinnen | und Bibliothekare beteiligen sich erstaunlich | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,730 | 3,730 | . Die betroffenen Bibliothekarinnen und | Bibliothekare | beteiligen sich erstaunlich selten direkt | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,784 | 3,784 | im Krisenfall die Anliegen der | Bibliothek | offiziell vertreten , falls diese | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,806 | 3,806 | Schweiz haben vor allem Öffentliche | Bibliotheken | einen relativ guten Stand , | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,838 | 3,838 | die grundsätzlich die Anliegen der | Bibliotheken | unterstützt , verspricht am meisten | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,927 | 3,927 | 2013 ) . Das neue | Bibliotheksgesetz | des Kantons St . Gallen | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,939 | 3,939 | Ein Impuls für die schweizerische | Bibliotheksgesetzgebung | . In : LIBREAS . | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,962 | 3,962 | ( 2012 ) . Eine | Bibliotheksstrategie | für die Schweiz . In | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,969 | 3,969 | die Schweiz . In : | Bibliothek | . Forschung und Praxis 36 | bibliothek* |
| [78] - Rudolf Mumenthaler, | 3,993 | 3,993 | ) . Kiezbezogene Proteste für | Bibliotheken | 2007-2008 . Eine Interview-Collage mit | bibliothek* |
| [78] - Rudolf Mumenthaler, | 4,033 | 4,033 | Auseinandersetzungen um die Aufgaben von | Bibliotheken | vor dem Hintergrund modernen bürgerschaftlichen | bibliothek* |
| [78] - Rudolf Mumenthaler, | 4,050 | 4,050 | um die Schließung kleinerer Öffentlicher | Bibliotheken | in Berlin 2007-2008 . In | bibliothek* |
| [78] - Rudolf Mumenthaler, | 4,167 | 4,167 | Kontakte zu einzelnen , der | Bibliothek | wohlgesinnten und gut vernetzten Politikerinnen | bibliothek* |
| [79] - Susanne Baudisch, El | 160 | 160 | digitalen Angeboten wissenschaftlicher und öffentlicher | Bibliotheken | in Deutschland angekommen ist ; | bibliothek* |
| [79] - Susanne Baudisch, El | 233 | 233 | Empfehlungen für ( Digitale ) | Bibliotheken | und deren Verbände , um | bibliothek* |
| [79] - Susanne Baudisch, El | 273 | 273 | der zweite Schritt . Digitale | Bibliothek | , Barrierefreiheit , Open Access | bibliothek* |
| [79] - Susanne Baudisch, El | 657 | 657 | für Alle ' 3 Digitale | Bibliotheken | und das Thema ' Barrierefreiheit | bibliothek* |
| [79] - Susanne Baudisch, El | 777 | 777 | zu barrierefreiem Webdesign in Digitalen | Bibliotheken | Dank Quellen AutorInnen Digitale Medien | bibliothek* |
| [79] - Susanne Baudisch, El | 796 | 796 | . Hierbei erweisen sich Digitale | Bibliotheken | als Tore zur Welt des | bibliothek* |
| [79] - Susanne Baudisch, El | 1,427 | 1,427 | mit weiteren Quellenangaben ) Digitale | Bibliotheken | übernehmen eine Mittlerfunktion bei Wissensbereitstellung | bibliothek* |
| [79] - Susanne Baudisch, El | 1,447 | 1,447 | sie nicht : die Digitale | Bibliothek | . Der Terminus vereint eine | bibliothek* |
| [79] - Susanne Baudisch, El | 1,500 | 1,500 | im Folgenden der Begriff Digitale | Bibliothek | ( en ) gebraucht wird | bibliothek* |
| [79] - Susanne Baudisch, El | 1,523 | 1,523 | die von öffentlichen und wissenschaftlichen | Bibliotheken | in Deutschland , oft auch | bibliothek* |
| [79] - Susanne Baudisch, El | 1,597 | 1,597 | Design für Alle in Digitalen | Bibliotheken | ' ; ( vgl . | bibliothek* |
| [79] - Susanne Baudisch, El | 1,627 | 1,627 | Kommunikation ( IuK ) der | Bibliotheken | in Deutschland tatsächlich angekommen ist | bibliothek* |
| [79] - Susanne Baudisch, El | 1,655 | 1,655 | auf dem 5 . Kongress | Bibliothek | & Information Deutschland 2013 vorgestellt | bibliothek* |
| [79] - Susanne Baudisch, El | 1,701 | 1,701 | Anbietern digitaler Angebote sowie mit | bibliothekarischen | Fachgremien und Verbänden . Die | bibliothek* |
| [79] - Susanne Baudisch, El | 1,779 | 1,779 | in den digitalen Angeboten von | Bibliotheken | , die anschließend exemplarisch für | bibliothek* |
| [79] - Susanne Baudisch, El | 1,858 | 1,858 | Empfehlungen für ( Digitale ) | Bibliotheken | und deren Verbände in Abschnitt | bibliothek* |
| [79] - Susanne Baudisch, El | 2,729 | 2,729 | , darunter für " Öffentliche | Bibliotheken | , z.B . Kataloge und | bibliothek* |
| [79] - Susanne Baudisch, El | 3,452 | 3,452 | sich in der Praxis Digitaler | Bibliotheken | mit dem Open Access-Prinzip längst | bibliothek* |
| [79] - Susanne Baudisch, El | 3,627 | 3,627 | und Publikationsmanagement häufig mit wissenschaftlichen | Bibliotheken | kooperieren . In ihrer Resolution | bibliothek* |
| [79] - Susanne Baudisch, El | 3,797 | 3,797 | Nutzer4 von heute erleben Digitale | Bibliotheken | , hier fokussiert auf das | bibliothek* |
| [79] - Susanne Baudisch, El | 3,805 | 3,805 | fokussiert auf das Angebot von | Bibliotheken | , in ganz unterschiedlichen Facetten | bibliothek* |
| [79] - Susanne Baudisch, El | 3,822 | 3,822 | , dass wissenschaftliche und öffentliche | Bibliotheken | in Deutschland mit ihren analogen | bibliothek* |
| [79] - Susanne Baudisch, El | 3,854 | 3,854 | . - Die Deutsche Digitale | Bibliothek | , kleine Schwester der Europeana | bibliothek* |
| [79] - Susanne Baudisch, El | 3,954 | 3,954 | online zu publizieren . Wissenschaftliche | Bibliotheken | schaffen hierfür den Zugang oder | bibliothek* |
| [79] - Susanne Baudisch, El | 3,972 | 3,972 | Access . - Und Öffentliche | Bibliotheken | eröffnen allen Nutzern , von | bibliothek* |
| [79] - Susanne Baudisch, El | 4,006 | 4,006 | Spielen und vielem mehr . | Bibliotheken | bedienen dabei mit Erschließung , | bibliothek* |
| [79] - Susanne Baudisch, El | 4,101 | 4,101 | Zugriff in Echtzeit . Aus | bibliothekspolitischer | Perspektive gibt es international klare | bibliothek* |
| [79] - Susanne Baudisch, El | 4,141 | 4,141 | Prüfliste für den Zugang zu | Bibliotheken | für Menschen mit Behinderungen ( | bibliothek* |
| [79] - Susanne Baudisch, El | 4,196 | 4,196 | UNESCO / IFLA Manifest für | Bibliotheken | für Menschen mit Lesebehinderungen ( | bibliothek* |
| [79] - Susanne Baudisch, El | 4,231 | 4,231 | und Schlüsselfunktionen von Regierungen , | Bibliotheken | und Informationsvermittlern aufgezeigt , " | bibliothek* |
| [79] - Susanne Baudisch, El | 4,308 | 4,308 | einen Entwurf von Richtlinien für | bibliothekarische | Angebote , die sich gezielt | bibliothek* |
| [79] - Susanne Baudisch, El | 4,451 | 4,451 | alle tatsächlich auch in nationale | Bibliotheksgesetze | Eingang findet , zeigt der | bibliothek* |
| [79] - Susanne Baudisch, El | 4,480 | 4,480 | berücksichtigende Personengruppen benennt dieses neue | Bibliotheksgesetz | explizit Menschen mit Behinderungen , | bibliothek* |
| [79] - Susanne Baudisch, El | 4,518 | 4,518 | Personengruppen ausweist , denen öffentliche | Bibliotheken | ihre besondere Aufmerksamkeit widmen sollen | bibliothek* |
| [79] - Susanne Baudisch, El | 4,547 | 4,547 | etwa auch in einem länderübergreifenden | Bibliotheksgesetz | , gibt es in Deutschland | bibliothek* |
| [79] - Susanne Baudisch, El | 4,568 | 4,568 | Struktur ist die Gesetzgebung für | Bibliotheken | eine Angelegenheit der Bundesländer , | bibliothek* |
| [79] - Susanne Baudisch, El | 4,624 | 4,624 | weitere Informationen bietet dazu das | Bibliotheksportal | . Ein Blick auf die | bibliothek* |
| [79] - Susanne Baudisch, El | 4,684 | 4,684 | Allein der Musterentwurf des Deutschen | Bibliotheksverbandes | e.V . zu einem Bibliotheksgesetz | bibliothek* |
| [79] - Susanne Baudisch, El | 4,689 | 4,689 | Bibliotheksverbandes e.V . zu einem | Bibliotheksgesetz | für die Länder sieht vor | bibliothek* |
| [79] - Susanne Baudisch, El | 4,696 | 4,696 | die Länder sieht vor , | Bibliotheken | als " barrierefreie Orte der | bibliothek* |
| [79] - Susanne Baudisch, El | 4,731 | 4,731 | das Thema Barrierefreiheit für die | Bibliotheken | hierzulande keinesfalls ein neues , | bibliothek* |
| [79] - Susanne Baudisch, El | 4,760 | 4,760 | steht nach wie vor der | Bibliotheksbau | , erst danach folgen zunehmend | bibliothek* |
| [79] - Susanne Baudisch, El | 4,775 | 4,775 | maßgeblichen Veröffentlichungen von und für | Bibliotheken | aus jüngerer Zeit zu diesem | bibliothek* |
| [79] - Susanne Baudisch, El | 4,788 | 4,788 | ein Aufsatz mit dem Fokus | Bibliotheksbau | von Jürgen Weber hervorzuheben , | bibliothek* |
| [79] - Susanne Baudisch, El | 4,801 | 4,801 | Begriff Universal Design für die | Bibliothekswelt | einbringt und eine Zielvereinbarung zur | bibliothek* |
| [79] - Susanne Baudisch, El | 4,822 | 4,822 | nicht zu den Standards in | Bibliotheken | . " ( Weber 2009 | bibliothek* |
| [79] - Susanne Baudisch, El | 4,842 | 4,842 | " Zugang zu barrierefrei gestalteten | Bibliothekskatalogen | und Informationssystemen via Internet " | bibliothek* |
| [79] - Susanne Baudisch, El | 4,870 | 4,870 | der Zeitschrift BuB - Forum | Bibliothek | und Information dem Schwerpunkt Barrierefreiheit | bibliothek* |
| [79] - Susanne Baudisch, El | 4,897 | 4,897 | Webdesign in ihrer Relevanz für | Bibliotheken | ( Viehweger 2011 ) . | bibliothek* |
| [79] - Susanne Baudisch, El | 4,919 | 4,919 | barrierefreie Gestaltung von Web-Angeboten in | Bibliotheken | , noch basierend auf BITV | bibliothek* |
| [79] - Susanne Baudisch, El | 4,935 | 4,935 | 2010 ) . Über die | Bibliotheken | hinaus bietet der wesensverwandte Museumsbereich | bibliothek* |
| [79] - Susanne Baudisch, El | 5,064 | 5,064 | in den digitalen Angeboten der | Bibliotheken | recht unterschiedliche Grade der Ausprägung | bibliothek* |
| [79] - Susanne Baudisch, El | 5,110 | 5,110 | am Beispiel der Deutschen Digitalen | Bibliothek | ( DDB ) zeigen . | bibliothek* |
| [79] - Susanne Baudisch, El | 5,361 | 5,361 | Webdesign für die meisten teilnehmenden | Bibliotheken | keine gesetzliche Pflicht ist . | bibliothek* |
| [79] - Susanne Baudisch, El | 5,374 | 5,374 | werden in der Praxis einige | Bibliotheken | unterschiedlichster Träger selbst aktiv und | bibliothek* |
| [79] - Susanne Baudisch, El | 5,430 | 5,430 | meist größerer bzw . überregionaler | Bibliotheken | zu finden ist . Die | bibliothek* |
| [79] - Susanne Baudisch, El | 5,718 | 5,718 | Handlungsempfehlungen zur Barrierefreiheit in Digitalen | Bibliotheken | . Als Testobjekte wurden digitale | bibliothek* |
| [79] - Susanne Baudisch, El | 5,728 | 5,728 | digitale Ressourcen und Dienste von | Bibliotheken | und Wissenschaftseinrichtungen in Deutschland gewählt | bibliothek* |
| [79] - Susanne Baudisch, El | 5,940 | 5,940 | Webdesign . Als Werkzeuge Digitaler | Bibliotheken | werden im Folgenden jene Weboberflächen | bibliothek* |
| [79] - Susanne Baudisch, El | 5,984 | 5,984 | , die vorwiegend von wissenschaftlichen | Bibliotheken | angeboten werden : 10 Fachportale | bibliothek* |
| [79] - Susanne Baudisch, El | 6,065 | 6,065 | systematische Stichprobe für Weboberflächen Digitaler | Bibliotheken | gelten dürfen ; Zweitens 5 | bibliothek* |
| [79] - Susanne Baudisch, El | 6,076 | 6,076 | Online-Kataloge ( OPACs ) wissenschaftlicher | Bibliotheken | mit dem Ziel , spezifische | bibliothek* |
| [79] - Susanne Baudisch, El | 6,097 | 6,097 | eine weitverbreitete Plattform für Öffentliche | Bibliotheken | , die den Zugriff auf | bibliothek* |
| [79] - Susanne Baudisch, El | 6,203 | 6,203 | gänzlich außerhalb des Einflussbereichs der | Bibliotheken | liegt . Die Aktion Mensch | bibliothek* |
| [79] - Susanne Baudisch, El | 9,206 | 9,206 | " Herzstück " einer jeden | Bibliothek | . Als solche verzeichnen sie | bibliothek* |
| [79] - Susanne Baudisch, El | 9,219 | 9,219 | jene digitalen Ressourcen , die | Bibliotheken | als mehr oder weniger eigene | bibliothek* |
| [79] - Susanne Baudisch, El | 9,235 | 9,235 | und damit als ihre Digitale | Bibliothek | bereitstellen . Der OPAC ist | bibliothek* |
| [79] - Susanne Baudisch, El | 9,264 | 9,264 | am häufigsten genutzte Internetangebot der | Bibliothek | " ( Gantert / Hacker | bibliothek* |
| [79] - Susanne Baudisch, El | 9,278 | 9,278 | ) . Folgerichtig gehören barrierefreie | Bibliothekskataloge | zu den priorisierten Webangeboten , | bibliothek* |
| [79] - Susanne Baudisch, El | 9,350 | 9,350 | elektronische Kataloge als Teil komplexer | Bibliotheks | ( management ) systeme heute | bibliothek* |
| [79] - Susanne Baudisch, El | 9,367 | 9,367 | kommerziellen Anbietern entwickelt und den | Bibliotheken | zum Kauf bzw . als | bibliothek* |
| [79] - Susanne Baudisch, El | 9,378 | 9,378 | Nutzungslizenz angeboten . Seitens der | Bibliotheken | ist damit das Problem der | bibliothek* |
| [79] - Susanne Baudisch, El | 9,427 | 9,427 | mitgeliefert ; Zum anderen können | Bibliotheken | die Nutzeroberflächen in ihr eigenes | bibliothek* |
| [79] - Susanne Baudisch, El | 9,481 | 9,481 | gleiche , als innovativ geltende | Bibliothekssystem | , verfügen aber jeweils über | bibliothek* |
| [79] - Susanne Baudisch, El | 9,891 | 9,891 | : Innerhalb des Gesamtauftritts einer | Bibliothek | stellt der barrierefreie OPAC eine | bibliothek* |
| [79] - Susanne Baudisch, El | 9,907 | 9,907 | seinem Beispiel wird sich eine | Bibliothek | künftig messen lassen müssen , | bibliothek* |
| [79] - Susanne Baudisch, El | 10,017 | 10,017 | . Die Mehrheit der Öffentlichen | Bibliotheken | ( im Folgenden auch ÖB | bibliothek* |
| [79] - Susanne Baudisch, El | 10,087 | 10,087 | in der Regel für den | Bibliotheksnutzer | kostenfrei verfügbar sind , da | bibliothek* |
| [79] - Susanne Baudisch, El | 10,094 | 10,094 | verfügbar sind , da die | Bibliotheken | bzw . deren Träger die | bibliothek* |
| [79] - Susanne Baudisch, El | 10,116 | 10,116 | der registrierte Nutzer mit gültigem | Bibliotheksausweis | für diese Angebote nichts , | bibliothek* |
| [79] - Susanne Baudisch, El | 10,128 | 10,128 | von der Benutzungsgebühr für die | Bibliothek | sowie einem Internetanschluss und zugehörigen | bibliothek* |
| [79] - Susanne Baudisch, El | 10,147 | 10,147 | und nicht unmittelbar in der | Bibliothek | nutzen möchte . Ihr digitales | bibliothek* |
| [79] - Susanne Baudisch, El | 10,175 | 10,175 | über eMedien bis zu Digitale | Bibliothek | und vielem anderen reichen . | bibliothek* |
| [79] - Susanne Baudisch, El | 10,248 | 10,248 | was die originäre Leih-Funktion der | Bibliotheken | unterstreicht . Am Beispiel dieser | bibliothek* |
| [79] - Susanne Baudisch, El | 10,276 | 10,276 | die zentrale Aufgabe der Öffentlichen | Bibliotheken | , pWissen für Alle verfügbar | bibliothek* |
| [79] - Susanne Baudisch, El | 10,318 | 10,318 | führende digitale Ausleihplattform für Öffentliche | Bibliotheken | in Deutschland ; angeboten wird | bibliothek* |
| [79] - Susanne Baudisch, El | 10,343 | 10,343 | Aktuell nehmen mehr als 2.200 | Bibliotheken | in Deutschland , Österreich und | bibliothek* |
| [79] - Susanne Baudisch, El | 10,354 | 10,354 | der Schweiz teil ; weitere | Bibliotheken | in Dänemark , Italien und | bibliothek* |
| [79] - Susanne Baudisch, El | 10,386 | 10,386 | , allerdings erwirbt nicht jede | Bibliothek | das Komplettpaket für ihre Nutzer | bibliothek* |
| [79] - Susanne Baudisch, El | 10,470 | 10,470 | Onleihe zu den Werkzeugen Digitaler | Bibliotheken | und bietet gleichermaßen die digitalen | bibliothek* |
| [79] - Susanne Baudisch, El | 10,507 | 10,507 | über die Website der heimischen | Bibliothek | des Nutzers und wechselt danach | bibliothek* |
| [79] - Susanne Baudisch, El | 10,547 | 10,547 | auf der Plattform mit seinen | Bibliotheksdaten | ( Benutzernummer und Kennwort ) | bibliothek* |
| [79] - Susanne Baudisch, El | 10,564 | 10,564 | er bleibt beim Angebot seiner | Bibliothek | . Auf dieser Plattform finden | bibliothek* |
| [79] - Susanne Baudisch, El | 10,922 | 10,922 | User-Foren , Demo-Videos oder das | Bibliothekspersonal | vor Ort unterstützen , um | bibliothek* |
| [79] - Susanne Baudisch, El | 11,124 | 11,124 | Relevanz der barrierefreien Ausleihe öffentlicher | Bibliotheken | inklusive grober Aufwandsabschätzung zur Beseitigung | bibliothek* |
| [79] - Susanne Baudisch, El | 11,436 | 11,436 | Die größte Herausforderung an den | Bibliotheksnutzer | stellt das ' Abspielen ' | bibliothek* |
| [79] - Susanne Baudisch, El | 12,161 | 12,161 | Ausgehend von der Popularität Öffentlicher | Bibliotheken | sowie der Verbreitung und enormen | bibliothek* |
| [79] - Susanne Baudisch, El | 12,176 | 12,176 | das digitale Angebot der Öffentlichen | Bibliotheken | in Deutschland ist es dringend | bibliothek* |
| [79] - Susanne Baudisch, El | 12,274 | 12,274 | Thema der elektronischen Ausleihe von | Bibliotheken | bestätigt sich die bereits 2012 | bibliothek* |
| [79] - Susanne Baudisch, El | 12,315 | 12,315 | nicht miteinander kompatibel und aus | Bibliothekssicht | weder benutzerfreundlich noch barrierefrei sind | bibliothek* |
| [79] - Susanne Baudisch, El | 12,343 | 12,343 | verweisen , dass E-Books von | Bibliotheken | plattformneutral verfügbar zu machen und | bibliothek* |
| [79] - Susanne Baudisch, El | 12,427 | 12,427 | , wie sie für Digitale | Bibliotheken | etwa mit den Werkzeugen zum | bibliothek* |
| [79] - Susanne Baudisch, El | 12,455 | 12,455 | Inhalte , die in Digitalen | Bibliotheken | als mehr oder weniger eigenständige | bibliothek* |
| [79] - Susanne Baudisch, El | 12,487 | 12,487 | In der Praxis präsentieren Digitale | Bibliotheken | deutlich häufiger Medien anderer Anbieter | bibliothek* |
| [79] - Susanne Baudisch, El | 12,517 | 12,517 | gestreift werden , bei denen | Bibliotheken | als Kompetenzpartner oder Erwerber bzw | bibliothek* |
| [79] - Susanne Baudisch, El | 12,586 | 12,586 | Desideratum . Ein Arbeitsfeld der | Bibliotheken | besteht in der Unterstützung des | bibliothek* |
| [79] - Susanne Baudisch, El | 12,656 | 12,656 | hinaus erwerben bzw . lizenzieren | Bibliotheken | elektronische Medien in Form von | bibliothek* |
| [79] - Susanne Baudisch, El | 12,851 | 12,851 | im Folgenden medientypische Publikationsformen Digitaler | Bibliotheken | im Kontext zukunftsfähiger , barrierefreier | bibliothek* |
| [79] - Susanne Baudisch, El | 12,874 | 12,874 | was speziell ( Digitale ) | Bibliotheken | als Anbieter oder Medienhersteller auf | bibliothek* |
| [79] - Susanne Baudisch, El | 14,635 | 14,635 | Sehbehinderung bereitstellt . In Digitalen | Bibliotheken | sind PDF-Dokumente in nahezu allen | bibliothek* |
| [79] - Susanne Baudisch, El | 14,796 | 14,796 | von Repositorien - oftmals wissenschaftliche | Bibliotheken | in Verbindung mit Hochschulen und | bibliothek* |
| [79] - Susanne Baudisch, El | 15,141 | 15,141 | . So gibt die Digitale | Bibliothek | Thüringen in der Kategorie " | bibliothek* |
| [79] - Susanne Baudisch, El | 16,074 | 16,074 | exemplarisch am eigenen E-Book . | Bibliotheken | in Deutschland treten bisher eher | bibliothek* |
| [79] - Susanne Baudisch, El | 16,116 | 16,116 | gegenüber stellen Öffentliche wie Wissenschaftliche | Bibliotheken | in rasant steigender Zahl ihren | bibliothek* |
| [79] - Susanne Baudisch, El | 16,146 | 16,146 | Medien bieten . Bei Öffentlichen | Bibliotheken | erfolgt die Bereitstellung von E-Books | bibliothek* |
| [79] - Susanne Baudisch, El | 16,176 | 16,176 | das 2014 von circa 100 | Bibliotheken | in Deutschland genutzt wird ( | bibliothek* |
| [79] - Susanne Baudisch, El | 16,185 | 16,185 | wird ( zu E-Books in | Bibliotheken | vgl . Bibliotheksportal ) . | bibliothek* |
| [79] - Susanne Baudisch, El | 16,188 | 16,188 | E-Books in Bibliotheken vgl . | Bibliotheksportal | ) . Gleichfalls werden E-Books | bibliothek* |
| [79] - Susanne Baudisch, El | 16,196 | 16,196 | Gleichfalls werden E-Books von wissenschaftlichen | Bibliotheken | angeboten , als Einzeltitel oder | bibliothek* |
| [79] - Susanne Baudisch, El | 16,242 | 16,242 | das E-Book durch die jeweilige | Bibliothek | gebunden , die das Medium | bibliothek* |
| [79] - Susanne Baudisch, El | 16,395 | 16,395 | ' heimischen ' ; wissenschaftlichen | Bibliothek | wird die Ausleihfunktion realisiert ; | bibliothek* |
| [79] - Susanne Baudisch, El | 16,518 | 16,518 | auch Open E-Books an Wissenschaftliche | Bibliotheken | stellen , bietet etwa Rudolf | bibliothek* |
| [79] - Susanne Baudisch, El | 17,599 | 17,599 | zugehörige Plattform Bookshare eine Digitale | Bibliothek | mit barrierefreien , vorwiegend englischsprachigen | bibliothek* |
| [79] - Susanne Baudisch, El | 17,979 | 17,979 | Markt als unumgänglich erweist . | Bibliotheken | müssen hier auch die großen | bibliothek* |
| [79] - Susanne Baudisch, El | 18,024 | 18,024 | Einschätzung der künftigen Entwicklung von | Bibliotheksbeständen | heranzuziehen ist ( IFLA 2012 | bibliothek* |
| [79] - Susanne Baudisch, El | 18,073 | 18,073 | die beispielsweise die Deutsche Digitale | Bibliothek | gegenwärtig vereint , sind Retrodigitalisate | bibliothek* |
| [79] - Susanne Baudisch, El | 18,138 | 18,138 | betrachtet werden . In Digitalen | Bibliotheken | treten sie mehrheitlich in verschiedenen | bibliothek* |
| [79] - Susanne Baudisch, El | 18,489 | 18,489 | wissenschaftlichen Erbe in Archiven , | Bibliotheken | und Museen " manifestiert wurde | bibliothek* |
| [79] - Susanne Baudisch, El | 18,497 | 18,497 | " manifestiert wurde . Digitale | Bibliotheken | prägen in entscheidender Weise die | bibliothek* |
| [79] - Susanne Baudisch, El | 18,541 | 18,541 | wurde für elementare Bereiche Digitaler | Bibliotheken | - bezogen auf die digitalen | bibliothek* |
| [79] - Susanne Baudisch, El | 18,549 | 18,549 | auf die digitalen Angebote der | Bibliotheken | in Deutschland - gezeigt , | bibliothek* |
| [79] - Susanne Baudisch, El | 19,041 | 19,041 | 17 ) . Sofern hierbei | Bibliotheken | mit ihren digitalen Angeboten ihre | bibliothek* |
| [79] - Susanne Baudisch, El | 19,248 | 19,248 | . Auskünfte zu E-Books in | Bibliotheken | erteilten Dr . Sophia Manns-Süßbrich | bibliothek* |
| [79] - Susanne Baudisch, El | 19,331 | 19,331 | Vortragsfolien , 5 . Kongress | Bibliothek | & Information Deutschland in Leipzig | bibliothek* |
| [79] - Susanne Baudisch, El | 19,414 | 19,414 | > , http://www.gesetze-im-internet.de/bgg/ BibG - | Bibliotheksgesetz | . Musterentwurf des Deutschen Bibliotheksverbandes | bibliothek* |
| [79] - Susanne Baudisch, El | 19,419 | 19,419 | Bibliotheksgesetz . Musterentwurf des Deutschen | Bibliotheksverbandes | e.V . vom 9 . | bibliothek* |
| [79] - Susanne Baudisch, El | 20,321 | 20,321 | Rupert ( 2008 ) : | Bibliothekarisches | Grundwissen . 8 . , | bibliothek* |
| [79] - Susanne Baudisch, El | 20,770 | 20,770 | Elke Dittmer : Zugang zu | Bibliotheken | für Menschen mit Behinderungen - | bibliothek* |
| [79] - Susanne Baudisch, El | 21,060 | 21,060 | ) : E-Books in Wissenschaftlichen | Bibliotheken | . Vortrag und Blogbeitrag vom | bibliothek* |
| [79] - Susanne Baudisch, El | 21,193 | 21,193 | barrierefreie Gestaltung von Web-Angeboten in | Bibliotheken | . TU Dresden , Inst | bibliothek* |
| [79] - Susanne Baudisch, El | 21,266 | 21,266 | Design für Alle in Digitalen | Bibliotheken | . Projektblog , http://www.grenzenloslesen.de. Stiftung | bibliothek* |
| [79] - Susanne Baudisch, El | 21,348 | 21,348 | : Chancen und Potentiale der | bibliothekarischen | und kommerziellen Leihe elektronischer Bücher | bibliothek* |
| [79] - Susanne Baudisch, El | 21,379 | 21,379 | , Fak . Medien , | Bibliotheks- | und Informationswissenschaft , Leipzig . | bibliothek* |
| [79] - Susanne Baudisch, El | 21,461 | 21,461 | In : BuB - Forum | Bibliothek | und Information 63 / 1 | bibliothek* |
| [79] - Susanne Baudisch, El | 21,547 | 21,547 | ( Hrsg . ) : | Bibliotheken | bauen und ausstatten . Bad | bibliothek* |
| [80] - Alexandra Svantje Li | 1,327 | 1,327 | fasst in der Informations- und | Bibliothekswissenschaft | indes eine ganze Bandbreite an | bibliothek* |
| [80] - Alexandra Svantje Li | 1,990 | 1,990 | über die lokalen Kataloge der | Bibliothek | . Ein weiterer Aspekt ist | bibliothek* |
| [80] - Alexandra Svantje Li | 2,116 | 2,116 | lokaler Ebene wurden die jeweiligen | Bibliothekskataloge | untersucht , auf der OA-spezifischen | bibliothek* |
| [80] - Alexandra Svantje Li | 3,851 | 3,851 | und Hannover zentral gehostet vom | Bibliotheksservicezentrum | Baden-Württemberg . Zwischen den Dokumenten | bibliothek* |
| [80] - Alexandra Svantje Li | 4,913 | 4,913 | Eine Analyse des Open-Access-Diskurses deutscher | Bibliotheken | . [ online ] Zugriff | bibliothek* |
| [80] - Alexandra Svantje Li | 4,955 | 4,955 | Informationswissenschaft : Kölner Arbeitspapiere zur | Bibliotheks- | und Informationswissenschaft . Bd . | bibliothek* |
| [80] - Alexandra Svantje Li | 5,145 | 5,145 | Zur Rolle und Aufgabe von | Bibliotheken | . In : Perspektive Bibliothek | bibliothek* |
| [80] - Alexandra Svantje Li | 5,150 | 5,150 | Bibliotheken . In : Perspektive | Bibliothek | Bd . 2 ( 2013 | bibliothek* |
| [81] - Bernhard Mittermaier | 289 | 289 | Survey Die vom Verfasser geleitete | Bibliothek | steht mit vielen der in | bibliothek* |
| [81] - Bernhard Mittermaier | 303 | 303 | Verlagen in Geschäftsbeziehungen . Die | Bibliothek | verwaltet den Publikationsfonds des Forschungszentrums | bibliothek* |
| [81] - Bernhard Mittermaier | 2,364 | 2,364 | Vereinigung großer britischer und irischer | Bibliotheken | : „ Double-dipping adjustments or | bibliothek* |
| [81] - Bernhard Mittermaier | 2,661 | 2,661 | bleibt zwischen Verlagen einerseits und | Bibliotheken | , Forschungsorganisationen und Forschungsförderern andererseits | bibliothek* |
| [81] - Bernhard Mittermaier | 5,310 | 5,310 | 2 angenommen , dass eine | Bibliothek | die Zeitschriften zu einem niedrigeren | bibliothek* |
| [81] - Bernhard Mittermaier | 8,935 | 8,935 | von Wissenschaft , Forschungsförderern und | Bibliothekswelt | zu Recht kritisierten Double Dipping | bibliothek* |
| [81] - Bernhard Mittermaier | 9,236 | 9,236 | Publikation der Ergebnisse in einer | bibliothekarischen | Fachzeitschrift . Vielen Dank und | bibliothek* |
| [81] - Bernhard Mittermaier | 9,383 | 9,383 | . Fall 2 : Eine | Bibliothek | hat beide Zeitschriften für 900 | bibliothek* |
| [81] - Bernhard Mittermaier | 9,776 | 9,776 | der nächsten Zeitschriftenrechnung durch die | Bibliothek | unter Verwendung der OA-Rechnungen als | bibliothek* |
| [81] - Bernhard Mittermaier | 10,107 | 10,107 | oder Freibier für alle ? | Bibliothek | , Forschung und Praxis 37 | bibliothek* |
| [81] - Bernhard Mittermaier | 11,492 | 11,492 | / P > 54 Die | Bibliothek | des Verfassers subskribiert 2 dieser | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 9 | 9 | über das 7 . Wildauer | Bibliothekssymposium | vom 9 . Bis 10 | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 67 | 67 | Hochschule Wildau das 7 . | Bibliothekssymposium | statt . Standen die ersten | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 182 | 182 | zum Einsatz von RFID in | Bibliotheken | . In 16 Ländern wurden | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 192 | 192 | wurden u.a . 251 Öffentliche | Bibliotheken | und 107 Universitätsbibliotheken befragt . | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 210 | 210 | wird am häufigsten von öffentlichen | Bibliotheken | eingesetzt . Die meisten setzen | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 317 | 317 | RFID in knapp 80 öffentlichen | Bibliotheken | Berlins . Im ersten Vortrag | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 346 | 346 | Beispiel Krimiautomat ) außerhalb von | Bibliotheksgebäuden | bis hin zu barrierefreien Automaten | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 556 | 556 | Frommholz ( TH Wildau , | Bibliothek | ) präsentierten einen neuen RFID-Leser | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 625 | 625 | Frommholz und Jan Kissig ( | Bibliothek | der TH Wildau ) führten | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 636 | 636 | die Eigenentwicklung bei den morgendlichen | Bibliotheksführungen | vor . Mit Spannung erwartet | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 651 | 651 | von Nikolaus Berger aus der | Bibliothek | der Wirtschaftsuniversität Wien , die | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 661 | 661 | die als eine der wenigen | Bibliotheken | RFID-Lösungen im UHF-Bereich ( UltraHigh | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 797 | 797 | das Vademecum ' RFID für | Bibliothekare | ' ( Seeliger , 2012 | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 813 | 813 | sich Vorträge aus den vorherigen | Bibliothekssymposien | , wie etwa über die | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 834 | 834 | Indoor- Ortung oder die fluide | Bibliothek | . Ein Folgeband ist in | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 949 | 949 | Ideen sind gesucht , auch | Bibliotheken | erlebbarer zu machen , hinter | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 990 | 990 | 2014 ) . Die Wildauer | Bibliothek | ging in Klausur und formulierte | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 1,149 | 1,149 | noch konventionellen Leuchten in der | Bibliothek | Nordhausen , schilderte Ehling insbesondere | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 1,447 | 1,447 | Tagen stattfindenden Führungen durch die | Bibliothek | und die Vorführung des RFID-Inventurprogramms | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 1,804 | 1,804 | Kunden nicht gibt , kennen | Bibliotheken | nur zu gut , ebenso | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 1,978 | 1,978 | ohnehin kaum eine Bindung zur | Bibliothek | , außer dass sie als | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 1,999 | 1,999 | Die dahinterliegende gesellschaftliche Bedeutung einer | Bibliothek | als Beitrag für Demokratisierung von | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,081 | 2,081 | Berlin-Brandenburgischen Stiftung zur Förderung der | Bibliothekswissenschaft | , mit Sitz in Wildau | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,141 | 2,141 | dem Problem , dass an | Bibliotheken | verschiedene Statistiken und Nutzungsdaten in | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,221 | 2,221 | für Daten aus der Deutschen | Bibliotheksstatistik | ( DBS ) , Nutzungsstatistiken | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,317 | 2,317 | praktische Erfahrung mit RFID-Einsatz in | Bibliotheken | haben und sich dem Thema | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,339 | 2,339 | Gerade auch die Vorträge der | bibliotheksexternen | Referenten , die teilweise befürchteten | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,372 | 2,372 | , es hat nichts mit | Bibliothek | zu tun " ) , | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,386 | 2,386 | . Denn versteht man die | Bibliothek | als öffentlichen Raum , als | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,400 | 2,400 | , hat letztlich alles mit | Bibliothek | zu tun . Das inhaltliche | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,435 | 2,435 | und Referenten des 7 . | Bibliothekssymposiums | in Wildau schufen einen großen | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,481 | 2,481 | festhält und die Brücke zwischen | Bibliothekswelt | und dem Rest der Welt | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,521 | 2,521 | ' : 8 . Wildauer | Bibliothekssymposium | am 08 . / 09.09.2015 | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,561 | 2,561 | ( 2012 ) RFID für | Bibliothekare | : ein Vademecum . 2 | bibliothek* |
| [82] - Ute Engelkenmeier (2 | 2,609 | 2,609 | Wildauer Hochschulbibliothek . In : | Bibliotheksdienst | 48 , 8 / 9 | bibliothek* |
| [83] - Markus Trapp (2015). | 7 | 7 | TRAPP Wie kommt eine wissenschaftliche | Bibliothek | dazu , eine App entwickeln | bibliothek* |
| [83] - Markus Trapp (2015). | 395 | 395 | Teilnehmer mit , davon 13 | Bibliotheken | als ' Content Provider ' | bibliothek* |
| [83] - Markus Trapp (2015). | 616 | 616 | Test , ob es für | Bibliotheken | Sinn macht , den Nutzern | bibliothek* |
| [83] - Markus Trapp (2015). | 723 | 723 | nennen . Es geht der | Bibliothek | auch darum , Materialien zur | bibliothek* |
| [83] - Markus Trapp (2015). | 1,080 | 1,080 | und Mitarbeiter der Medienwerkstatt der | Bibliothek | mit . Für die Öffentlichkeitsarbeit | bibliothek* |
| [83] - Markus Trapp (2015). | 1,105 | 1,105 | . Zu klärende Fragen auf | bibliothekarischer | Seite waren : Materialauswahl / | bibliothek* |
| [83] - Markus Trapp (2015). | 1,563 | 1,563 | war zwar von Seiten der | Bibliothek | gewünscht , doch standen dazu | bibliothek* |
| [83] - Markus Trapp (2015). | 1,987 | 1,987 | Schulen wurden angeschrieben und im | bibliothekarischen | Kontext wurden von Mitgliedern des | bibliothek* |
| [83] - Markus Trapp (2015). | 2,009 | 2,009 | wurde nicht vernachlassigt . Die | Bibliothek | hatte das Glück , dass | bibliothek* |
| [83] - Markus Trapp (2015). | 2,247 | 2,247 | ( Android ) freuen die | Bibliothek | natürlich , genauso wie die | bibliothek* |
| [83] - Markus Trapp (2015). | 2,287 | 2,287 | Nutzer für die Angebote der | Bibliothek | interessiert werden . Die freien | bibliothek* |
| [83] - Markus Trapp (2015). | 2,335 | 2,335 | Hintergründe nicht und hatten der | Bibliothek | womöglich unterstellt , nur die | bibliothek* |
| [83] - Markus Trapp (2015). | 2,542 | 2,542 | Materialen gezeigt - stellt die | Bibliothek | in sehr großem , und | bibliothek* |
(Wir sehen in der Tabelle, wie auch anderswo, dass quanteda noch nicht mit dem «*innen» umgehen kann – ausser ich habe die «Einstellung» übersehen beziehungsweise hätte das mit einem eigenen «Lexikon» machen können, was wieder etwas länger gedauert hätte –, aber das wird nur eine Frage der Zeit sein.)
Die gleichen Tabellen lassen sich selbstverständlich auch für andere Begriffe erstellen. Hier zum Beispiel die zu «information», zu «open» – beides Worte, von denen wir jetzt wissen, dass sie im Korpus oft vorkamen – sowie zu «praxis», weil dies in einer Zeitschrift mit dem Namen Informationspraxis zu erwarten wäre.
| docname | from | to | pre | keyword | post | pattern |
|---|---|---|---|---|---|---|
| [1] - Karsten Schuldt (202 | 5,861 | 5,861 | Raum . Bibliothek Forschung und | Praxis | 45 , 1 , 125–134 | praxis* |
| [4] - Anette Cordts, Elias | 2,689 | 2,689 | ) Entwicklung von bedarfsorientierten und | praxisnahen | Handreichungen in Zusammenarbeit mit Expert | praxis* |
| [4] - Anette Cordts, Elias | 3,076 | 3,076 | von den Projekten in die | Praxis | zu befördern . Dass mehrere | praxis* |
| [6] - Nicolas Bach (2022). | 345 | 345 | im deutschsprachigen Raum kein ausreichend | praxisorientiertes | als auch offenes Handbuch für | praxis* |
| [7] - Tina Grahl (2021). S | 267 | 267 | nicht überall vollständig in der | Praxis | umgesetzt . ” ( Neschke | praxis* |
| [7] - Tina Grahl (2021). S | 2,457 | 2,457 | Themen Urheberrecht ; gute wissenschaftliche | Praxis | , Zitieren und Plagiatsprüfung und | praxis* |
| [7] - Tina Grahl (2021). S | 4,262 | 4,262 | Themen Urheberrecht ; gute wissenschaftliche | Praxis | , Zitieren und Plagiatsprüfung sowie | praxis* |
| [7] - Tina Grahl (2021). S | 4,294 | 4,294 | Themen Urheberrecht , gute wissenschaftliche | Praxis | , Zitieren und Plagiat einordnet | praxis* |
| [7] - Tina Grahl (2021). S | 4,329 | 4,329 | Plagiatsprüfung , das in der | Praxis | bereits mehrfach durch Promovierende nachgefragt | praxis* |
| [7] - Tina Grahl (2021). S | 5,315 | 5,315 | De Gruyter Saur . ( | Praxiswissen | ) . Hobohm , Hans-Christoph | praxis* |
| [8] - Sarah Dellmann, Arvi | 6,389 | 6,389 | Chance ? ! : Ein | Praxisbericht | aus der Universitätsbibliothek Kassel . | praxis* |
| [9] - Berfu Erdogan, Chris | 2,081 | 2,081 | eher wird dies in der | Praxis | wahrscheinlich sein . Als „ | praxis* |
| [10] - Grischa Fraumann, Ch | 2,012 | 2,012 | ) . Usability-Tests in der | Praxis | – ein Werkstattbericht des Projekts | praxis* |
| [12] - Jana Madlen Schütte | 915 | 915 | „ Schnittstelle von Wissenschaft und | Praxis | " definiert , eignet sie | praxis* |
| [12] - Jana Madlen Schütte | 948 | 948 | * innen berichten aus der | Praxis | und geben eine Bestandsaufnahme ihrer | praxis* |
| [12] - Jana Madlen Schütte | 1,330 | 1,330 | ein . Das Besondere dieses | Praxisbeispiels | ist die Organisation und Verantwortung | praxis* |
| [13] - Thomas Mutschler (20 | 4,801 | 4,801 | und Zugänglichkeit in der wissenschaftlichen | Praxis | . KIT Scientific Publishing , | praxis* |
| [15] - Wolf Christoph Seife | 7,449 | 7,449 | Publikationswesens . Bibliothek Forschung und | Praxis | 42 ( 1 ) , | praxis* |
| [15] - Wolf Christoph Seife | 7,598 | 7,598 | Vergangenheit . Bibliothek Forschung und | Praxis | 37 ( 1 ) , | praxis* |
| [16] - Martin Munke, Daniel | 7,866 | 7,866 | . Bibliotheken als Orte kuratorischer | Praxis | ( Bibliotheks- und Informationspraxis , | praxis* |
| [16] - Martin Munke, Daniel | 8,442 | 8,442 | Erbes in Sachsen . Ein | Praxisbericht | . In Bibliothek . Forschung | praxis* |
| [16] - Martin Munke, Daniel | 8,449 | 8,449 | In Bibliothek . Forschung & | Praxis | 44 , 3 , 339–347 | praxis* |
| [16] - Martin Munke, Daniel | 8,487 | 8,487 | In Bibliothek . Forschung & | Praxis | 38 , 1 , 83–92 | praxis* |
| [16] - Martin Munke, Daniel | 8,716 | 8,716 | ( Hg . ) . | Praxishandbuch | Open Access . Berlin / | praxis* |
| [16] - Martin Munke, Daniel | 9,647 | 9,647 | ( Hg . ) . | Praxishandbuch | Open Access . Berlin / | praxis* |
| [17] - Colette Knight, Tama | 2,798 | 2,798 | wie sie dies in der | Praxis | umsetzen können . Eine der | praxis* |
| [18] - Markus Putnings (202 | 685 | 685 | Ideen kann z.B . das | Praxishandbuch | Informationsmarketing ( Schade & Georgy | praxis* |
| [18] - Markus Putnings (202 | 1,121 | 1,121 | Hg . ) 2019 . | Praxishandbuch | Informationsmarketing : Konvergente Strategien , | praxis* |
| [20] - Stefanie Hanneken, A | 4,494 | 4,494 | nur schwer mit der verlegerischen | Praxis | der Frontlistproduktion vereinbaren lässt , | praxis* |
| [21] - Claudia Frick (2020) | 319 | 319 | wissenschaftliche Arbeiten und die wissenschaftliche | Praxis | angeht . Nicht zuletzt dank | praxis* |
| [21] - Claudia Frick (2020) | 3,290 | 3,290 | , durchaus der gängigen wissenschaftlichen | Praxis | des Peer-Reviews folgte , 6 | praxis* |
| [23] - Franziska Altemeier, | 251 | 251 | ersten Tages fanden Fortbildungsveranstaltungen und | Praxisworkshops | statt . Neben der jährlich | praxis* |
| [25] - Jens Bemme (2020). # | 3,230 | 3,230 | Gelegenheiten Publikationen gezielt als performative | Praxis | in der Wissenschaftskommunikation zu nutzen | praxis* |
| [26] - Stefanie Spiegelberg | 145 | 145 | 4 Fluide Bibliothek in der | Praxis | – Voraussetzungen und Auswirkungen 4.1 | praxis* |
| [26] - Stefanie Spiegelberg | 732 | 732 | Fluide Bibliothekskonzepte sind in der | Praxis | noch selten und auch in | praxis* |
| [26] - Stefanie Spiegelberg | 2,063 | 2,063 | Basis von bereits in der | Praxis | erprobten Umsetzungen fluider Bestandskonzepte - | praxis* |
| [26] - Stefanie Spiegelberg | 2,080 | 2,080 | Es gibt jedoch in der | Praxis | auch Bedenken gegenüber fluiden Aufstellungskonzepten | praxis* |
| [31] - Karsten Schuldt (202 | 3,537 | 3,537 | Aufgabe . Teilweise wird die | Praxisnähe | des jeweiligen Buches gelobt , | praxis* |
| [31] - Karsten Schuldt (202 | 10,769 | 10,769 | sichern . Bibliothek Forschung und | Praxis | 43 , 2 , 332–347 | praxis* |
| [33] - Christian Hauschke ( | 4,846 | 4,846 | all diesen Forderungen in der | Praxis | nachgekommen wird , bleibt abzuwarten | praxis* |
| [34] - Alessandro Blasetti, | 260 | 260 | Grundlagen 3 Zweitveröffentlichung in der | Praxis | 3.1 Projekt- und Metadatenakquise 3.1.1 | praxis* |
| [34] - Alessandro Blasetti, | 586 | 586 | . 2011 ) . Die | Praxis | zeigt , dass Open Access | praxis* |
| [34] - Alessandro Blasetti, | 1,113 | 1,113 | scheint es einen Mangel an | praxisnahen | Handreichungen oder gar Arbeitsanleitungen zu | praxis* |
| [34] - Alessandro Blasetti, | 2,245 | 2,245 | Lab organisierenden Einrichtungen in der | Praxis | herangezogen werden ; ergänzend sind | praxis* |
| [34] - Alessandro Blasetti, | 3,047 | 3,047 | Rahmenbedingungen . Erfahrungen aus der | Praxis | zeigen , dass Autor * | praxis* |
| [34] - Alessandro Blasetti, | 3,309 | 3,309 | Haftung liegt . In der | Praxis | hat sich gezeigt , dass | praxis* |
| [34] - Alessandro Blasetti, | 3,552 | 3,552 | Weise statt . In der | Praxis | werden u . a . | praxis* |
| [34] - Alessandro Blasetti, | 4,435 | 4,435 | einem flächendeckenden Zweitveröffentlichungsservice in der | Praxis | umsetzbar ist . Wurde keinerlei | praxis* |
| [34] - Alessandro Blasetti, | 4,866 | 4,866 | ist , dass in der | Praxis | nicht immer einfach zu entscheiden | praxis* |
| [34] - Alessandro Blasetti, | 4,971 | 4,971 | Verlagen verhandeln . In der | Praxis | sind derartige Verhandlungen jedoch eher | praxis* |
| [34] - Alessandro Blasetti, | 6,182 | 6,182 | zweitveröffentlicht wurde . In der | Praxis | kann die Dokumentation unterschiedlich umgesetzt | praxis* |
| [34] - Alessandro Blasetti, | 6,410 | 6,410 | 69 ) . In der | Praxis | nutzen einige Repositorienbetreiber als Grundlage | praxis* |
| [34] - Alessandro Blasetti, | 9,034 | 9,034 | sein , sind in der | Praxis | von Zweitveröffentlichungsservices aber eher überfordernd | praxis* |
| [34] - Alessandro Blasetti, | 9,436 | 9,436 | Bibliotheksurheberrecht : ein Lehrbuch für | Praxis | und Ausbildung . Bock + | praxis* |
| [34] - Alessandro Blasetti, | 10,132 | 10,132 | ( 2017 ) . „ | Praxishandbuch | Open Access ” . Berlin | praxis* |
| [34] - Alessandro Blasetti, | 10,334 | 10,334 | Winfried ( 2014 ) . | Praxiskommentar | zum Urheberrecht . 4 . | praxis* |
| [34] - Alessandro Blasetti, | 13,326 | 13,326 | . Dies wird in der | Praxis | bereits angewendet , siehe etwa | praxis* |
| [36] - Nicole Eichenberger | 3,294 | 3,294 | in größerem Maßstab in der | Praxis | umgesetzt werden , müssten daher | praxis* |
| [36] - Nicole Eichenberger | 3,402 | 3,402 | Bei einer Überführung in die | Praxis | müssten außerdem Fragen der ( | praxis* |
| [36] - Nicole Eichenberger | 4,109 | 4,109 | “ Information – Wissenschaft & | Praxis | 64 , 2-3 : 149-165 | praxis* |
| [38] - Christian Erlinger ( | 697 | 697 | aber dort Anleihe in technologischer | Praxis | bzw . hinsichtlich der Usabililty | praxis* |
| [40] - Christian Hauschke, | 2,699 | 2,699 | : Wissensorganisation für Theorie und | Praxis | . http://doi.org/10.5281/zenodo.1464145 Grundler , Mathias | praxis* |
| [41] - Joanna Einbock, Chri | 483 | 483 | wird vielfältig und in der | Praxis | oft unscharf verwendet . Es | praxis* |
| [41] - Joanna Einbock, Chri | 3,295 | 3,295 | 16 ) . In der | Praxis | stellt sich oft jedoch heraus | praxis* |
| [41] - Joanna Einbock, Chri | 4,537 | 4,537 | für die Forschung und die | Praxis | in diesem Feld an , | praxis* |
| [41] - Joanna Einbock, Chri | 4,734 | 4,734 | im akademischen Sektor in der | Praxis | auswirkt . Auch veränderte Ansprüche | praxis* |
| [42] - Adrian Pohl, Fabian | 2,222 | 2,222 | Autoren oder Schlagwörter , in | praxistauglicher | Art umzusetzen ( ohne URIs | praxis* |
| [44] - Christian Hauschke, | 154 | 154 | Architektur 4 Vitro in der | Praxis | 4.1 Vitro als Fundament für | praxis* |
| [45] - Karsten Schuldt, Azr | 4,357 | 4,357 | zu wenig genau für die | Praxis | formulieren , sodass beispielsweise beim | praxis* |
| [45] - Karsten Schuldt, Azr | 4,456 | 4,456 | , diese aber in der | Praxis | nicht wirklich zur Barrierefreiheit verhelfen | praxis* |
| [45] - Karsten Schuldt, Azr | 5,866 | 5,866 | und Beschäftigten im Spiegel der | Praxis | ‟ . Weinheim ; Basel | praxis* |
| [45] - Karsten Schuldt, Azr | 5,918 | 5,918 | . „ Forschungsmethoden in die | Praxisausbildung | einbinden ? Ansätze an der | praxis* |
| [46] - Karsten Schuldt, Rud | 1,014 | 1,014 | Projekt , welches Fachliteratur und | Praxis | miteinander verband . Der Text | praxis* |
| [46] - Karsten Schuldt, Rud | 1,742 | 1,742 | Makerspaces geäussert , in der | Praxis | schien jedoch oft das Interesse | praxis* |
| [46] - Karsten Schuldt, Rud | 8,212 | 8,212 | begreifen – in der bibliothekarischen | Praxis | das Lesen und Nutzen von | praxis* |
| [47] - Jakob Voß, Laura Bod | 509 | 509 | Methoden des Projektmanagements in die | Praxis | umzusetzen . Für das Sommersemester | praxis* |
| [49] - Jana Mersmann, Chris | 467 | 467 | Motto „ Forschungsinformationen in der | Praxis | “ , wobei die Förderung | praxis* |
| [50] - Christian Wilke, Reg | 1,214 | 1,214 | noch evaluiert werden . In | Praxissessions | hatten die Teilnehmer des Workshops | praxis* |
| [51] - Gabriele Fahrenkrog, | 779 | 779 | und Autoren berichten aus der | Praxis | und setzen sich in ihren | praxis* |
| [51] - Gabriele Fahrenkrog, | 995 | 995 | positives Fazit . In ihrem | Praxisbericht | zu Openness in den Künsten | praxis* |
| [51] - Gabriele Fahrenkrog, | 1,315 | 1,315 | in den Künsten - Ein | Praxisbericht | der Mediathek HGK FHNW Basel | praxis* |
| [52] - Eckhart Arnold, Stef | 116 | 116 | Einsatz von Permalinks in der | Praxis | : Erst Permalinks machen Internetquellen | praxis* |
| [52] - Eckhart Arnold, Stef | 218 | 218 | Wir schließen mit einem konkreten | Praxisbeispiel | , dem Aufbau des Publikationsservers | praxis* |
| [52] - Eckhart Arnold, Stef | 712 | 712 | ? 4 Permalinks in der | Praxis | : Worauf zu achten ist | praxis* |
| [52] - Eckhart Arnold, Stef | 761 | 761 | Maschinenlesbarkeit von Permalinks 6 Ein | Praxis-Beispiel | : Warum BV-Nummern nicht für | praxis* |
| [52] - Eckhart Arnold, Stef | 969 | 969 | einer Argumentation in der wissenschaftlichen | Praxis | erheblich vereinfachen und beschleunigen . | praxis* |
| [52] - Eckhart Arnold, Stef | 997 | 997 | digitale Publikation ? Und welchen | Praxis-Regeln | sollten Informationsdienste wie Bibliotheken , | praxis* |
| [52] - Eckhart Arnold, Stef | 1,658 | 1,658 | Inhalt verweist . In der | Praxis | existieren dabei Grauzonen , weil | praxis* |
| [52] - Eckhart Arnold, Stef | 4,383 | 4,383 | gilt es aber als gute | Praxis | DOIs als URL , d.h | praxis* |
| [52] - Eckhart Arnold, Stef | 6,053 | 6,053 | demgegenüber die noch weithin anzutreffende | Praxis | , beim Verweis auf Netzseiten | praxis* |
| [52] - Eckhart Arnold, Stef | 7,446 | 7,446 | eines elektronischen Dokuments . Die | Praxis | muss zeigen , ob das | praxis* |
| [52] - Eckhart Arnold, Stef | 8,931 | 8,931 | – auch durchaus in der | Praxis | auswirken können . Dieser Unsicherheiten | praxis* |
| [53] - Salome Zehnder (2017 | 3,405 | 3,405 | : Die Fotobefragung in der | Praxis | . Verfügbar unter : http://www.univie.ac.at/visuellesoziologie/Publikation2008/VisSozKolb.pdf | praxis* |
| [56] - Tabea Lurk, Jürgen E | 900 | 900 | Hinzu kommen Theorieinstitute zur Ästhetischen | Praxis | und Theorie sowie zu Experimentellen | praxis* |
| [57] - Christian Kaier (201 | 3,460 | 3,460 | . Bibliothek - Forschung und | Praxis | , 39 : 2 , | praxis* |
| [59] - Daniel Hürlimann, Al | 1,246 | 1,246 | Bernhard Mittermaier hat diese merkwürdige | Praxis | der “ Hybrid-Zeitschriften ” , | praxis* |
| [60] - Fabian Gail, Mark Ve | 11 | 11 | , Mark VETTER Der vorliegende | Praxisbericht | beschreibt die Methode des „ | praxis* |
| [60] - Fabian Gail, Mark Ve | 108 | 108 | ausgewertet . Abschließend werden im | Praxisbericht | zentrale Ergebnisse dieser Interviews vorgestellt | praxis* |
| [60] - Fabian Gail, Mark Ve | 441 | 441 | von Forschung und guter wissenschaftlicher | Praxis | sind daher Anstrengungen notwendig , | praxis* |
| [60] - Fabian Gail, Mark Ve | 5,814 | 5,814 | Bereich Medizin , die wenig | Praxis | im Verfassen wissenschaftlicher Veröffentlichungen hätten | praxis* |
| [60] - Fabian Gail, Mark Ve | 7,196 | 7,196 | zur Datensicherung hinausgehen ; die | Praxis | würde von den jeweiligen Arbeitsgruppen | praxis* |
| [62] - Beat Mattmann (2016) | 73 | 73 | immer unproblematisch . In der | Praxis | zeigt sich jedoch ein kreativer | praxis* |
| [62] - Beat Mattmann (2016) | 684 | 684 | auf die Hürden der alltäglichen | Praxis | eröffnen und durchaus auch Wege | praxis* |
| [62] - Beat Mattmann (2016) | 2,361 | 2,361 | gibt es jedoch in der | Praxis | regelmässig Unsicherheiten und damit auch | praxis* |
| [63] - Karsten Schuldt (201 | 6,985 | 6,985 | Volksschulgesetz keine Bedeutung für die | Praxis | in den Schulen hat . | praxis* |
| [64] - Daniel Beucke, Arvid | 87 | 87 | ergänzen kann . In diesem | Praxisbeitrag | soll über Entstehung und Ablauf | praxis* |
| [64] - Daniel Beucke, Arvid | 244 | 244 | eingereichten Abstracts auf Innovation , | Praxisrelevanz | , Vernetzung und Interdisziplinarität sowie | praxis* |
| [65] - Armin Talke (2016). | 1,063 | 1,063 | Versand auszuschließen , in der | Praxis | nicht angewandt wird , weil | praxis* |
| [65] - Armin Talke (2016). | 1,198 | 1,198 | , dass Schrankenregeln in der | Praxis | auch genutzt werden können . | praxis* |
| [65] - Armin Talke (2016). | 1,777 | 1,777 | Verwaisten Werken als in der | Praxis | zu aufwendig herausgestellt hat , | praxis* |
| [66] - Dörte Böhner, Gabrie | 419 | 419 | , die in ihrem Arbeitsalltag | praxisrelevante | Erfahrungen gesammelt haben , die | praxis* |
| [66] - Dörte Böhner, Gabrie | 653 | 653 | Barrierefreiheit zur Routine machen – | Praxisfall | : Digitale Bibliothek . In | praxis* |
| [66] - Dörte Böhner, Gabrie | 752 | 752 | : Stand der Dinge aus | Praxissicht | . In : Informationspraxis 2 | praxis* |
| [67] - Tim Schumann (2016). | 228 | 228 | Bibliothek , Makerspace Garten 5 | Praxisprojekt | „ Urban Gardening und Öffentliche | praxis* |
| [67] - Tim Schumann (2016). | 7,043 | 7,043 | an der TH Köln als | Praxisprojekt | im Rahmen des Studiums des | praxis* |
| [68] - Gabriele Fahrenkrog | 1,985 | 1,985 | sich mit einem Blog der | Praxis | digital-offener Bildungsmedien8 und mit Hilfe | praxis* |
| [68] - Gabriele Fahrenkrog | 3,565 | 3,565 | aus und für die bibliothekarische | Praxis | künftig auf einer Plattform17 erschlossen | praxis* |
| [68] - Gabriele Fahrenkrog | 6,008 | 6,008 | ( OER ) – ein | Praxisbeispiel | . In : Bibliotheksdienst . | praxis* |
| [68] - Gabriele Fahrenkrog | 6,459 | 6,459 | ( OER ) in der | Praxis | . Berlin : mabb . | praxis* |
| [69] - Simon Schultze (2016 | 3,468 | 3,468 | : Gaming und Bibliotheken . | Praxiswissen | . Berlin : De Gruyter | praxis* |
| [72] - Martin Wollschläger- | 2,433 | 2,433 | einem fachlichen Kontext wird ein | Praxisbezug | hergestellt . Dieser Praxisbezug konstruiert | praxis* |
| [72] - Martin Wollschläger- | 2,437 | 2,437 | ein Praxisbezug hergestellt . Dieser | Praxisbezug | konstruiert die Sinnhaftigkeit der Thematik | praxis* |
| [72] - Martin Wollschläger- | 6,897 | 6,897 | : Monographien zu Forschung und | Praxis | , 1 ) . Taylor | praxis* |
| [73] - Corinna Haas, Rudolf | 1,142 | 1,142 | möglichst eigenständig und kritisch ein | praxisrelevantes | Thema zu bearbeiten . Ein | praxis* |
| [73] - Corinna Haas, Rudolf | 10,679 | 10,679 | an die jeweils moderne und | praxisorientierte | Lehre . Das Thema „ | praxis* |
| [73] - Corinna Haas, Rudolf | 10,752 | 10,752 | intellektuell als Herausforderung als auch | praxisorientiert | für Entscheidungen über die zukünftige | praxis* |
| [73] - Corinna Haas, Rudolf | 12,306 | 12,306 | Bibliothekscafé als dritter Ort : | Praxis-Untersuchungen | über den Zusammenhang und die | praxis* |
| [73] - Corinna Haas, Rudolf | 12,763 | 12,763 | In : Bibliothek Forschung und | Praxis | 38 ( 2014 ) 2 | praxis* |
| [73] - Corinna Haas, Rudolf | 13,393 | 13,393 | ) . Forschungsmethoden in die | Praxisausbildung | einbinden ? : Ansätze an | praxis* |
| [74] - Rudolf Mumenthaler, | 282 | 282 | diesem wird eine zeitgemässe und | praxisrelevante | Ausbildung umgesetzt . Aufgrund sich | praxis* |
| [74] - Rudolf Mumenthaler, | 291 | 291 | Aufgrund sich ändernder Anforderungen der | Praxis | sollte das Curriculum also gerade | praxis* |
| [75] - Christian Hauschke, | 27 | 27 | Quellen wiederzuverwenden . In der | Praxis | kann man dabei auf Konvertierungsprobleme | praxis* |
| [76] - Jens Ambacher, Gabri | 2,595 | 2,595 | möchten . Es wurde die | Praxis | genannt , bei dem sich | praxis* |
| [77] - Dörte Böhner, Gabrie | 789 | 789 | Tagungs- und Werkstattberichte aus der | Praxis | , um die fachliche Diskussion | praxis* |
| [78] - Rudolf Mumenthaler, | 3,973 | 3,973 | : Bibliothek . Forschung und | Praxis | 36 ( 2012 ) 1 | praxis* |
| [79] - Susanne Baudisch, El | 1,690 | 1,690 | erstellt auf der Grundlage von | Praxistests | und im Austausch mit den | praxis* |
| [79] - Susanne Baudisch, El | 3,450 | 3,450 | Webdesigns hat sich in der | Praxis | Digitaler Bibliotheken mit dem Open | praxis* |
| [79] - Susanne Baudisch, El | 4,949 | 4,949 | breitgefächerte Einblicke in Theorie und | Praxis | barrierefreier Gestaltung öffentlicher Kultur- und | praxis* |
| [79] - Susanne Baudisch, El | 5,372 | 5,372 | Und dennoch werden in der | Praxis | einige Bibliotheken unterschiedlichster Träger selbst | praxis* |
| [79] - Susanne Baudisch, El | 5,682 | 5,682 | . Anhand von Testergebnissen und | Praxisbeispielen | sollen der aktuelle Stand der | praxis* |
| [79] - Susanne Baudisch, El | 7,949 | 7,949 | und zumindest anteilig in der | Praxis | angekommen ist . Zunehmend kommen | praxis* |
| [79] - Susanne Baudisch, El | 9,193 | 9,193 | Design für Alle in der | Praxis | . ( Online- ) Kataloge | praxis* |
| [79] - Susanne Baudisch, El | 12,484 | 12,484 | im Netz . In der | Praxis | präsentieren Digitale Bibliotheken deutlich häufiger | praxis* |
| [79] - Susanne Baudisch, El | 12,560 | 12,560 | können lediglich Impulse aufgrund von | Praxistests | und Erfahrungswerten vermittelt werden , | praxis* |
| [79] - Susanne Baudisch, El | 13,647 | 13,647 | von Multimedia ; in der | Praxis | finden sich für EPUB 3 | praxis* |
| [79] - Susanne Baudisch, El | 13,679 | 13,679 | zum gegenwärtigen Zeitpunkt in der | Praxis | am ehesten in der zweiten | praxis* |
| [79] - Susanne Baudisch, El | 13,980 | 13,980 | ein solcher Herstellungsprozess in der | Praxis | einer OA-Zeitschrift umgesetzt werden kann | praxis* |
| [79] - Susanne Baudisch, El | 14,605 | 14,605 | in ihrer PDF-Werkstatt ) neben | Praxistipps | und Angeboten zum Erstellen barrierefreier | praxis* |
| [79] - Susanne Baudisch, El | 15,412 | 15,412 | . Ein Blick in die | Praxis | wissenschaftlichen Arbeitens zeigt aber auch | praxis* |
| [79] - Susanne Baudisch, El | 16,962 | 16,962 | hervorzubringen vermag . In der | Praxis | setzt sich EPUB 3 indes | praxis* |
| [79] - Susanne Baudisch, El | 17,516 | 17,516 | Erstellen barrierefreier E-Books in der | Praxis | umzusetzen , ist beispielsweise das | praxis* |
| [79] - Susanne Baudisch, El | 18,255 | 18,255 | inzwischen umfangreiche Projekterfahrungen vor , | Praxisberichte | anhand ausgewählter Bestände hierzu bietet | praxis* |
| [79] - Susanne Baudisch, El | 18,358 | 18,358 | zu generieren . In der | Praxis | jedoch stellt das Textarchiv ein | praxis* |
| [79] - Susanne Baudisch, El | 18,532 | 18,532 | und -produktion . Ausgehend von | Praxistests | und empirischen Erfahrungswerten wurde für | praxis* |
| [79] - Susanne Baudisch, El | 18,687 | 18,687 | werden . Dies bestätigen die | Praxistests | an den digitalen Angeboten im | praxis* |
| [79] - Susanne Baudisch, El | 19,125 | 19,125 | Durchführung bzw . Begleitung verschiedenster | Praxistests | ( Testpaket 1 ; Tests | praxis* |
| [79] - Susanne Baudisch, El | 21,484 | 21,484 | in XML . Grundlagen , | Praxis | , Referenz . 7 . | praxis* |
| [79] - Susanne Baudisch, El | 21,976 | 21,976 | und Verbandsklagen in Theorie und | Praxis | thematisiert ein Tagungsband ( Weltli | praxis* |
| [80] - Alexandra Svantje Li | 5,054 | 5,054 | . Nutzerorientierung in Wissenschaft und | Praxis | . Heidelberg : Akademische Verlagsgesellschaft | praxis* |
| [81] - Bernhard Mittermaier | 9,166 | 9,166 | Umsetzung der No-Double-Dipping-Policy in der | Praxis | aussieht . Sie können Ihre | praxis* |
| [81] - Bernhard Mittermaier | 10,111 | 10,111 | ? Bibliothek , Forschung und | Praxis | 37 ( 1 ) , | praxis* |
| [82] - Ute Engelkenmeier (2 | 403 | 403 | in unterhaltsamer Weise aus der | Praxis | was bei einem so großen | praxis* |
| [82] - Ute Engelkenmeier (2 | 1,322 | 1,322 | . Ein Beispiel aus der | Praxis | veranschaulichte die Anwendbarkeit : 3D | praxis* |
| [82] - Ute Engelkenmeier (2 | 2,451 | 2,451 | , guten Konzepten aus der | Praxis | , Erkenntnisse aus externer Sicht | praxis* |
| docname | from | to | pre | keyword | post | pattern |
|---|---|---|---|---|---|---|
| [2] - Stefan Schmeja, Ulri | 45 | 45 | Zeitschrift nicht im Directory of | Open | Access Journals ( DOAJ ) | open |
| [2] - Stefan Schmeja, Ulri | 99 | 99 | question of the quality of | Open | Access journals arises at the | open |
| [2] - Stefan Schmeja, Ulri | 128 | 128 | listed in the Directory of | Open | Access Journals ( DOAJ ) | open |
| [2] - Stefan Schmeja, Ulri | 167 | 167 | experience in the assessment . | open | access journals , predatory journals | open |
| [2] - Stefan Schmeja, Ulri | 174 | 174 | journals , predatory journals , | open | access consulting , open access | open |
| [2] - Stefan Schmeja, Ulri | 178 | 178 | , open access consulting , | open | access funding Veröffentlichung : 05.02.2023 | open |
| [2] - Stefan Schmeja, Ulri | 252 | 252 | beiden Fällen das Directory of | Open | Access Journals ( DOAJ , | open |
| [2] - Stefan Schmeja, Ulri | 366 | 366 | und soll im Directory of | Open | Access Journals gelistet sein . | open |
| [2] - Stefan Schmeja, Ulri | 1,113 | 1,113 | nicht beurteilen , außer bei | Open | Peer Review5 oder anhand von | open |
| [2] - Stefan Schmeja, Ulri | 1,768 | 1,768 | “ Action Plan for Diamond | Open | Access ” ) befürwortet wird | open |
| [3] - Frank Waldschmidt-Di | 965 | 965 | drängt sich die Analogie zu | Open | Access auf : Der Bibtag | open |
| [4] - Anette Cordts, Elias | 47 | 47 | zur Beschleunigung der Transformation zu | Open | Access geförderten Projekte B ! | open |
| [4] - Anette Cordts, Elias | 75 | 75 | , Scholar-Led Journals , Diamond | Open | Access , Recommender In a | open |
| [4] - Anette Cordts, Elias | 103 | 103 | to accelerate the transformation to | open | access , B ! SON | open |
| [4] - Anette Cordts, Elias | 128 | 128 | with the expert public . | Open | Access Transformation , Scholar-Led Journals | open |
| [4] - Anette Cordts, Elias | 136 | 136 | , Scholar-Led Journals , Diamond | Open | Access , Recommender Veröffentlichung : | open |
| [4] - Anette Cordts, Elias | 177 | 177 | des wissenschaftlichen Publikationswesens hin zu | Open | Access voranzutreiben . Fünf dieser | open |
| [4] - Anette Cordts, Elias | 298 | 298 | aus dem CODRIA-Projekt zu Diamond | Open | Access und Erkenntnissen aus dem | open |
| [4] - Anette Cordts, Elias | 483 | 483 | Verzeichnis von Instanzen der Software | Open | Journal Systems ( OJS ) | open |
| [4] - Anette Cordts, Elias | 504 | 504 | verschiedener Datenquellen ( Directory of | Open | Access Journals ( DOAJ ) | open |
| [4] - Anette Cordts, Elias | 1,138 | 1,138 | . B ! SON wird | Open | Source zur Verfügung gestellt , | open |
| [4] - Anette Cordts, Elias | 1,595 | 1,595 | konsortiale Lösungen zur Finanzierung von | Open | Access etablieren . Ziel ist | open |
| [4] - Anette Cordts, Elias | 1,801 | 1,801 | ( ggf . APC-freien ) | Open | Access erscheinen , als auch | open |
| [4] - Anette Cordts, Elias | 1,900 | 1,900 | beitragen , Qualitätsstandards im Bereich | Open | Access zu etablieren und weiterzuentwickeln | open |
| [4] - Anette Cordts, Elias | 2,191 | 2,191 | von OPTIMETA entwickelten Plugins für | Open | Journal Systems gewidmet , die | open |
| [4] - Anette Cordts, Elias | 2,276 | 2,276 | z.B . Wikidata oder dem | Open | Research Knowledge Graph , veröffentlicht | open |
| [4] - Anette Cordts, Elias | 3,169 | 3,169 | ( 2022 ) . Diamond | Open | Access Journals Germany ( DOAG | open |
| [4] - Anette Cordts, Elias | 3,269 | 3,269 | : OPTIMETA – Strengthening the | Open | Access publishing system through open | open |
| [4] - Anette Cordts, Elias | 3,274 | 3,274 | Open Access publishing system through | open | citations and spatiotemporal metadata . | open |
| [4] - Anette Cordts, Elias | 3,328 | 3,328 | Marcel ( 2021 ) . | Open | Access , aber nicht umsonst | open |
| [4] - Anette Cordts, Elias | 3,377 | 3,377 | and funding options to make | open | access journals sustainable . Zenodo | open |
| [5] - Maxi Kindling, Dorot | 1,651 | 1,651 | preparation . ARCHE uses an | open | source ticket management system ( | open |
| [5] - Maxi Kindling, Dorot | 2,830 | 2,830 | Berlin ) . It is | open | for participation by interested colleagues | open |
| [6] - Nicolas Bach (2022). | 124 | 124 | Living Handbook , Bibliotheks-IT , | Open | Access Publizieren , Bericht In | open |
| [6] - Nicolas Bach (2022). | 174 | 174 | , and supported by the | Open | Access Publication Fund of the | open |
| [6] - Nicolas Bach (2022). | 203 | 203 | remains collectively updatable via an | open | source publishing pipeline . This | open |
| [6] - Nicolas Bach (2022). | 260 | 260 | , Library Information Technology , | Open | Access Publishing , Insight Report | open |
| [6] - Nicolas Bach (2022). | 5,723 | 5,723 | . Hackathons and other participatory | open | science formats . Research Ideas | open |
| [7] - Tina Grahl (2021). S | 582 | 582 | , die aktuelle Themen wie | Open | Access , Forschungsdatenmanagement oder kollaboratives | open |
| [7] - Tina Grahl (2021). S | 1,933 | 1,933 | über frei zugängliche Informationen ( | Open | Access ) ( 10 ) | open |
| [7] - Tina Grahl (2021). S | 2,156 | 2,156 | haben bereits eine Publikation als | Open | Access veröffentlicht . Die drei | open |
| [7] - Tina Grahl (2021). S | 2,320 | 2,320 | , da die Qualität von | Open | Data “ erst langsam auf | open |
| [7] - Tina Grahl (2021). S | 2,525 | 2,525 | ) ( 5 ) , | Open | Science ( Open Educational Resources | open |
| [7] - Tina Grahl (2021). S | 2,528 | 2,528 | ) , Open Science ( | Open | Educational Resources , Open Data | open |
| [7] - Tina Grahl (2021). S | 2,532 | 2,532 | ( Open Educational Resources , | Open | Data ) ( 5 ) | open |
| [7] - Tina Grahl (2021). S | 2,591 | 2,591 | Publikationsstrategie ( 4 ) , | Open | Access Publizieren ( 4 ) | open |
| [7] - Tina Grahl (2021). S | 3,736 | 3,736 | Tools wie das Browser Add-On | Open | Access Button oder die Website | open |
| [7] - Tina Grahl (2021). S | 4,592 | 4,592 | und Arbeiten wurde zum Thema | Open | Science ein hoher Schulungs- , | open |
| [7] - Tina Grahl (2021). S | 5,242 | 5,242 | Rahmenbedingungen von den Hochschulleitungen bei | Open | Access und Open Educational Resources | open |
| [7] - Tina Grahl (2021). S | 5,245 | 5,245 | Hochschulleitungen bei Open Access und | Open | Educational Resources . o-bib 6 | open |
| [8] - Sarah Dellmann, Arvi | 125 | 125 | grüner Weg , Workflowentwicklung , | Open | Access During the Open Access | open |
| [8] - Sarah Dellmann, Arvi | 129 | 129 | , Open Access During the | Open | Access Week 2020 , Kassel | open |
| [8] - Sarah Dellmann, Arvi | 283 | 283 | . Self-Archiving services , Green | Open | Access , Repositories , Workflow | open |
| [8] - Sarah Dellmann, Arvi | 291 | 291 | Repositories , Workflow development , | Open | Access Veröffentlichung : 23.12.2021 in | open |
| [8] - Sarah Dellmann, Arvi | 319 | 319 | prominenten “ Wege ” des | Open | Access . Auch wenn er | open |
| [8] - Sarah Dellmann, Arvi | 342 | 342 | durch die DFG Förderprogramme “ | Open | Access Publizieren ” ( 2010–2020 | open |
| [8] - Sarah Dellmann, Arvi | 407 | 407 | Artikel , die im grünen | Open | Access verfügbar sind , überdurchschnittlich | open |
| [8] - Sarah Dellmann, Arvi | 1,628 | 1,628 | Eintrag auf der Website der | Open | Access Week ( Deppe 2020 | open |
| [8] - Sarah Dellmann, Arvi | 3,543 | 3,543 | Bewusstsein unter wissenschaftlichem Personal für | Open | Access und die Unterschiede im | open |
| [8] - Sarah Dellmann, Arvi | 3,587 | 3,587 | Politiken der Verlage hinsichtlich nachträglichem | Open | Access sind . Das wird | open |
| [8] - Sarah Dellmann, Arvi | 6,068 | 6,068 | für den grünen Weg des | Open | Access [ online ] . | open |
| [8] - Sarah Dellmann, Arvi | 6,355 | 6,355 | ) : Stärkung des grünen | Open | Access [ online ] . | open |
| [8] - Sarah Dellmann, Arvi | 6,421 | 6,421 | Najko ( 2021 ) : | Open | is not forever : a | open |
| [8] - Sarah Dellmann, Arvi | 6,430 | 6,430 | : a study of vanished | open | access journals . Journal of | open |
| [8] - Sarah Dellmann, Arvi | 6,515 | 6,515 | the prevalence and impact of | Open | Access articles . PeerJ 6 | open |
| [8] - Sarah Dellmann, Arvi | 6,536 | 6,536 | Sarah ( 2020 ) : | Open | Access an der Universität Kassel | open |
| [8] - Sarah Dellmann, Arvi | 6,699 | 6,699 | ( 2020 ) : “ | Open | Access Woche 2020 ” . | open |
| [9] - Berfu Erdogan, Chris | 1,816 | 1,816 | * in den Einsatz von | Open | Journal Systems , bietet die | open |
| [10] - Grischa Fraumann, Ch | 607 | 607 | Daten entwickelt : ImpactViz – | Open | Impact Visualizer . Das Tool | open |
| [10] - Grischa Fraumann, Ch | 639 | 639 | auf Artikelebene in OJS ( | Open | Journal Systems , vgl . | open |
| [10] - Grischa Fraumann, Ch | 659 | 659 | ) . OJS wird als | Open | Source Software von den Herausgebenden | open |
| [10] - Grischa Fraumann, Ch | 1,987 | 1,987 | Research Discovery . Journal of | Open | Source Software 4 ( 39 | open |
| [10] - Grischa Fraumann, Ch | 2,067 | 2,067 | ) . Reference implementation for | open | scientometric indicators ( ROSI ) | open |
| [10] - Grischa Fraumann, Ch | 2,550 | 2,550 | John ( 2005 ) . | Open | Journal Systems . Library Hi | open |
| [11] - Christian Hauschke, | 144 | 144 | various other topics around the | open | source software VIVO , research | open |
| [11] - Christian Hauschke, | 731 | 731 | . Veranstaltungsorte können mittels Linked | Open | Data mit externen Quellen ( | open |
| [11] - Christian Hauschke, | 1,411 | 1,411 | in einem englischsprachigen Vortrag National | Open | Research Analytics ( NORA6 ) | open |
| [11] - Christian Hauschke, | 2,597 | 2,597 | research discovery . Journal of | Open | Source Software , 4 ( | open |
| [11] - Christian Hauschke, | 2,667 | 2,667 | , March ) . National | Open | Research Analytics ( NORA ) | open |
| [11] - Christian Hauschke, | 2,680 | 2,680 | present and future of developing | open | research analytics at countrylevel , | open |
| [12] - Jana Madlen Schütte | 171 | 171 | committed themselves to promoting the | Open | Access transformation . The libraries | open |
| [12] - Jana Madlen Schütte | 214 | 214 | “ Regional Libraries and the | Open | Access Transformation ” , which | open |
| [12] - Jana Madlen Schütte | 249 | 249 | opportunities . Regional Libraries , | Open | Access Transformation , Open Access | open |
| [12] - Jana Madlen Schütte | 253 | 253 | , Open Access Transformation , | Open | Access Publishing Veröffentlichung : 10.08.2021 | open |
| [12] - Jana Madlen Schütte | 277 | 277 | Dienstleistungen rund um das Thema | Open | Access in den Serviceportfolios der | open |
| [12] - Jana Madlen Schütte | 305 | 305 | bis vor Kurzem in der | Open | Access-Bewegung wenig in Erscheinung . | open |
| [12] - Jana Madlen Schütte | 319 | 319 | weder aktiv am Diskus der | Open | Access-Community noch bieten sie Beratungen | open |
| [12] - Jana Madlen Schütte | 340 | 340 | ist eine stärkere Bewusstseinsbildung für | Open | Access-Themen im Kreis der Regionalbibliotheken | open |
| [12] - Jana Madlen Schütte | 402 | 402 | , sich mit dem Thema | Open | Access auseinanderzusetzen . Spezifische Angebote | open |
| [12] - Jana Madlen Schütte | 501 | 501 | einen Vortrag zum Thema „ | Open | Access – mehr als Pay-to-publish | open |
| [12] - Jana Madlen Schütte | 601 | 601 | zu einem Workshop zum Thema | Open | Access in Regionalbibliotheken – Ideenbörse | open |
| [12] - Jana Madlen Schütte | 1,098 | 1,098 | an Aufgeschlossenheit gegenüber dem Thema | Open | Access in den befragten Einrichtungen | open |
| [12] - Jana Madlen Schütte | 1,136 | 1,136 | Hochschulschriftenserver zum Publikationsfonds – Die | Open | Access-Transformation an der Thüringer Universitäts- | open |
| [12] - Jana Madlen Schütte | 1,163 | 1,163 | und fragt danach , inwiefern | Open | Access ein Thema für Regionalbibliotheken | open |
| [12] - Jana Madlen Schütte | 1,381 | 1,381 | Betrag „ Vom Retrodigitalisat zu | Open | Access . Landeshistorische Literatur zu | open |
| [12] - Jana Madlen Schütte | 1,452 | 1,452 | , diese mit Qucosa.Journals in | Open | Access zu überführen . Qucosa.Journals | open |
| [12] - Jana Madlen Schütte | 1,475 | 1,475 | die Überführung bestehender Subskriptionsmodelle in | Open | Access . Im Bereich der | open |
| [12] - Jana Madlen Schütte | 1,524 | 1,524 | Darstellung unterschiedlicher Facetten des Themas | Open | Access und Regionalbibliotheken kann mit | open |
| [12] - Jana Madlen Schütte | 1,645 | 1,645 | Adreas ( 2019 ) : | Open | Access – mehr als Pay-to-publish | open |
| [12] - Jana Madlen Schütte | 1,681 | 1,681 | ) : Vom Retrodigitalisat zu | Open | Access . Landeshistorische Literatur zu | open |
| [12] - Jana Madlen Schütte | 1,714 | 1,714 | Hochschulschriftenserver zum Publikationsfonds – Die | Open | Access-Transformation an der Thüringer Universitäts- | open |
| [13] - Thomas Mutschler (20 | 12 | 12 | Artikel lotet das Potenzial von | Open | Access für Regionalbibliotheken aus . | open |
| [13] - Thomas Mutschler (20 | 41 | 41 | Jena die unterschiedlichen Facetten von | Open | Access vorgestellt . Die Aspekte | open |
| [13] - Thomas Mutschler (20 | 65 | 65 | kultureller Überlieferung bis hin zu | Open | Access-Publikationsfonds und Forschungsdaten . Einschätzungen | open |
| [13] - Thomas Mutschler (20 | 80 | 80 | für Regionalbibliotheken im Kontext der | Open | Access-Transformation runden den Beitrag ab | open |
| [13] - Thomas Mutschler (20 | 87 | 87 | runden den Beitrag ab . | Open | Access , Elektronisches Publizieren , | open |
| [13] - Thomas Mutschler (20 | 102 | 102 | article explores the potential of | Open | Access for regional libraries . | open |
| [13] - Thomas Mutschler (20 | 125 | 125 | functions the different facets of | Open | Access are introduced on the | open |
| [13] - Thomas Mutschler (20 | 165 | 165 | digitization of cultural heritage , | Open | Access funds and research data | open |
| [13] - Thomas Mutschler (20 | 187 | 187 | regional libraries face in the | Open | Access transformation . Open Access | open |
| [13] - Thomas Mutschler (20 | 191 | 191 | the Open Access transformation . | Open | Access , Electronic Publishing , | open |
| [13] - Thomas Mutschler (20 | 219 | 219 | 2021 ) Die Idee von | Open | Access , Forschungsoutput im World | open |
| [13] - Thomas Mutschler (20 | 277 | 277 | der Umsetzung von Angeboten zum | Open | Access-Publizieren . An den Regionalbibliotheken | open |
| [13] - Thomas Mutschler (20 | 286 | 286 | den Regionalbibliotheken scheint das Thema | Open | Access indes weitgehend vorbeigegangen zu | open |
| [13] - Thomas Mutschler (20 | 307 | 307 | haben , treten in der | Open | Access-Bewegung bislang wenig in Erscheinung | open |
| [13] - Thomas Mutschler (20 | 340 | 340 | Stadtbibliotheken , auf denen sich | Open | Access-Policies bis auf wenige Ausnahmen | open |
| [13] - Thomas Mutschler (20 | 414 | 414 | sowie auf einzelne Sammlungen – | Open | Access ist hier , bislang | open |
| [13] - Thomas Mutschler (20 | 460 | 460 | zu bewerten , das Thema | Open | Access unter den Regionalbibliotheken stärker | open |
| [13] - Thomas Mutschler (20 | 490 | 490 | , welche im Rahmen der | Open | Access-Tage 2019 erstmalig zu einer | open |
| [13] - Thomas Mutschler (20 | 500 | 500 | einer Ideenbörse in Sachen „ | Open | Access in Regionalbibliotheken " eingeladen | open |
| [13] - Thomas Mutschler (20 | 541 | 541 | ein Bekenntnis zur Förderung der | Open | Access-Transformation enthält ( vgl . | open |
| [13] - Thomas Mutschler (20 | 566 | 566 | beobachtende Öffnung der Regionalbibliotheken gegenüber | Open | Access fordert regelrecht dazu heraus | open |
| [13] - Thomas Mutschler (20 | 585 | 585 | Herausforderungen sich im Kontext der | Open | Access-Transformation für die Regionalbibliotheken konkret | open |
| [13] - Thomas Mutschler (20 | 595 | 595 | konkret identifizieren lassen . Stellt | Open | Access auch für Regionalbibliotheken ein | open |
| [13] - Thomas Mutschler (20 | 615 | 615 | ist , welche Facetten von | Open | Access sind für Regionalbibliotheken relevant | open |
| [13] - Thomas Mutschler (20 | 693 | 693 | . Wenn im Folgenden von | Open | Access die Rede ist , | open |
| [13] - Thomas Mutschler (20 | 711 | 711 | und der goldene Weg des | Open | Access-Publizierens , sondern der Begriff | open |
| [13] - Thomas Mutschler (20 | 725 | 725 | des umfassender angelegten Konzepts von | Open | Science zu gelten , im | open |
| [13] - Thomas Mutschler (20 | 750 | 750 | " meint im Kontext von | Open | Access die Erstveröffentlichung von Forschungsergebnissen | open |
| [13] - Thomas Mutschler (20 | 757 | 757 | die Erstveröffentlichung von Forschungsergebnissen in | Open | Access-Medien , meist Zeitschriften , | open |
| [13] - Thomas Mutschler (20 | 790 | 790 | der in diesem Beitrag verwendete | Open | Access-Begriff sowohl digitalisierte Quellen und | open |
| [13] - Thomas Mutschler (20 | 823 | 823 | in Thüringen steht das Thema | Open | Access seit mehreren Jahren auf | open |
| [13] - Thomas Mutschler (20 | 839 | 839 | Wissenschaftspolitik . Dabei stellt die | Open | Access-Transformation für die Thüringer Universitäts- | open |
| [13] - Thomas Mutschler (20 | 881 | 881 | Insofern bildet sich das Thema | Open | Access hier in zahlreichen Facetten | open |
| [13] - Thomas Mutschler (20 | 907 | 907 | Forschungsdaten . Den Beginn der | Open | Access-Transformation an der Thüringer Universitäts- | open |
| [13] - Thomas Mutschler (20 | 1,073 | 1,073 | Rechenzentrum auf der Basis der | Open | Source Software MyCoRe ( https://www.mycore.de/ | open |
| [13] - Thomas Mutschler (20 | 1,237 | 1,237 | , das meiste davon im | Open | Access . Bald nach der | open |
| [13] - Thomas Mutschler (20 | 1,390 | 1,390 | einen zentralen Baustein innerhalb der | Open | Access-Aktivitäten der ThULB Jena bildet | open |
| [13] - Thomas Mutschler (20 | 1,409 | 1,409 | Plattform für die Veröffentlichung eigener | Open | Access-Zeitschriften . Voraussetzung für die | open |
| [13] - Thomas Mutschler (20 | 1,754 | 1,754 | Die Entwicklungen im Bereich des | Open | Access-Publizierens aktueller Forschungsbeiträge und Veröffentlichungen | open |
| [13] - Thomas Mutschler (20 | 1,783 | 1,783 | erheblich . Im Kontext des | Open | Access-Publizierens kamen nicht nur neue | open |
| [13] - Thomas Mutschler (20 | 1,933 | 1,933 | können perspektivisch jedoch auch im | Open | Access freigeschaltet werden , wenn | open |
| [13] - Thomas Mutschler (20 | 1,954 | 1,954 | Thüringer Landespolitik nimmt das Thema | Open | Access seit einigen Jahren stärker | open |
| [13] - Thomas Mutschler (20 | 1,966 | 1,966 | den Fokus . So war | Open | Access Verhandlungsgegenstand der in Thüringen | open |
| [13] - Thomas Mutschler (20 | 1,991 | 1,991 | an : „ Gemäß dem | Open | Access-Ansatz sollen zukünftig insbesondere wissenschaftliche | open |
| [13] - Thomas Mutschler (20 | 2,048 | 2,048 | stärkere Hinwendung des Landes zum | Open | Access markierte an der Thüringer | open |
| [13] - Thomas Mutschler (20 | 2,067 | 2,067 | für den Aufbau eines landesweiten | Open | Access-Monitoring-Systems , sondern auch für | open |
| [13] - Thomas Mutschler (20 | 2,076 | 2,076 | auch für die Einrichtung eines | Open | Access-Publikationsfonds , der Mitgliedern der | open |
| [13] - Thomas Mutschler (20 | 2,108 | 2,108 | Wissenschaftler * innen in genuinen | Open | Access-Medien , vor allem Zeitschriften | open |
| [13] - Thomas Mutschler (20 | 2,169 | 2,169 | Wie sich zeigt , drang | Open | Access auf sehr vielfältige Weise | open |
| [13] - Thomas Mutschler (20 | 2,244 | 2,244 | . Knowledge Unlatched sowie weitreichende | Open | Access-Komponenten im Rahmen laufender Lizenzverträge | open |
| [13] - Thomas Mutschler (20 | 2,264 | 2,264 | 2004 abgeschlossen worden waren . | Open | Access-Komponenten in Lizenzverträgen beziehen sowohl | open |
| [13] - Thomas Mutschler (20 | 2,302 | 2,302 | Ergänzt wird das Angebot zu | Open | Access-Medien durch die Übernahme von | open |
| [13] - Thomas Mutschler (20 | 2,310 | 2,310 | die Übernahme von Titeldaten zu | Open | Access-Publikationen externer Provenienz ( z | open |
| [13] - Thomas Mutschler (20 | 2,335 | 2,335 | . Der begonnene Ausbau der | Open | Access-Förderung sowohl an der Thüringer | open |
| [13] - Thomas Mutschler (20 | 2,415 | 2,415 | konstituierten Kooperationsverbunds Thüringer Hochschulbibliotheken bildet | Open | Access neben der Lizenzierung elektronischer | open |
| [13] - Thomas Mutschler (20 | 2,493 | 2,493 | bibliothekarische Dienste und Beratungsangebote . | Open | Access-Publizieren wird sowohl auf dem | open |
| [13] - Thomas Mutschler (20 | 2,525 | 2,525 | und Landesbibliothek Jena hat der | Open | Access-Transformationsprozess besonders seit Abschluss der | open |
| [13] - Thomas Mutschler (20 | 2,560 | 2,560 | Umstieg vom Subskriptionsmodell zum publikationsanzahlbasierten | Open | Access-Geschäftsmodell im Kontext von Zeitschrifteninhalten | open |
| [13] - Thomas Mutschler (20 | 2,572 | 2,572 | Gezahlt werden soll in der | Open | Access-Welt nicht mehr für den | open |
| [13] - Thomas Mutschler (20 | 2,605 | 2,605 | sich der Umstieg auf das | Open | Access-Publikationsmodell nicht sofort realisieren lässt | open |
| [13] - Thomas Mutschler (20 | 2,617 | 2,617 | erfolgt der Umstieg darauf via | Open | Access-Transformationsverträge , welche in Jena | open |
| [13] - Thomas Mutschler (20 | 2,689 | 2,689 | umfasst , möglichst in Gold | Open | Access-Zeitschriften überführt werden . Viele | open |
| [13] - Thomas Mutschler (20 | 2,751 | 2,751 | . Eine weitere Facette von | Open | Access bilden Forschungsdaten und Angebote | open |
| [13] - Thomas Mutschler (20 | 2,767 | 2,767 | . Hier bilden die als | Open | Access-Publikationen verfügbaren digitalisierten Quellen und | open |
| [13] - Thomas Mutschler (20 | 3,055 | 3,055 | Veränderungen brachte und bringt die | Open | Access-Transformation auch für die Organisation | open |
| [13] - Thomas Mutschler (20 | 3,124 | 3,124 | sondern auch im Rahmen von | Open | Access-Publikationsprozessen : Pro Artikel müssen | open |
| [13] - Thomas Mutschler (20 | 3,159 | 3,159 | wird mit der Einführung von | Open | Access kleinteiliger . Insofern waren | open |
| [13] - Thomas Mutschler (20 | 3,263 | 3,263 | die im Zusammenhang mit der | Open | Access-Transformation kontinuierlich fließenden Innovationen auch | open |
| [13] - Thomas Mutschler (20 | 3,291 | 3,291 | beim Blick auf das Thema | Open | Access gut nachvollziehen lässt , | open |
| [13] - Thomas Mutschler (20 | 3,339 | 3,339 | Artikel beschrieb den Stand der | Open | Access-Transformation an der Thüringer Universitäts- | open |
| [13] - Thomas Mutschler (20 | 3,398 | 3,398 | kultureller Überlieferung bis hin zu | Open | Access-Publikationsfonds , neuen Lizenzmodellen und | open |
| [13] - Thomas Mutschler (20 | 3,415 | 3,415 | der bibliothekarischen Arbeitsprozesse hat die | Open | Access-Transformation erhebliche Auswirkungen . Das | open |
| [13] - Thomas Mutschler (20 | 3,427 | 3,427 | der Ausführungen zum Stand der | Open | Access-Transformation an der Thüringer Universitäts- | open |
| [13] - Thomas Mutschler (20 | 3,441 | 3,441 | bestand darin aufzuzeigen , dass | Open | Access eine inzwischen hochkomplexe Thematik | open |
| [13] - Thomas Mutschler (20 | 3,477 | 3,477 | gestellte Frage zurückzukommen , inwiefern | Open | Access ein Thema für Regionalbibliotheken | open |
| [13] - Thomas Mutschler (20 | 3,516 | 3,516 | Frage nach der Bedeutung von | Open | Access für Regionalbibliotheken hinsichtlich jeglicher | open |
| [13] - Thomas Mutschler (20 | 3,525 | 3,525 | hinsichtlich jeglicher autor * innenbasierter | Open | Access-Geschäftsmodelle der Verlage und Anbieter | open |
| [13] - Thomas Mutschler (20 | 3,575 | 3,575 | auch den grünen Weg des | Open | Access-Publizierens weitgehend aus , sofern | open |
| [13] - Thomas Mutschler (20 | 3,594 | 3,594 | Hinzu kommt , dass die | Open | Access-Transformationsverträge , bislang zumindest , | open |
| [13] - Thomas Mutschler (20 | 3,886 | 3,886 | Erschließung " können Regionalbibliotheken die | Open | Access-Transformation ebenfalls aktiv unterstützen , | open |
| [13] - Thomas Mutschler (20 | 3,906 | 3,906 | zum anderen mittels Erschließung regionalspezifischer | Open | Access-Publikationen . Im Bereich geistes- | open |
| [13] - Thomas Mutschler (20 | 3,922 | 3,922 | wie Monographien und Sammelbänden ist | Open | Access ebenso ein Thema . | open |
| [13] - Thomas Mutschler (20 | 3,993 | 3,993 | eingesetzt , wie Subscribe to | Open | , das eine fortlaufende Subskription | open |
| [13] - Thomas Mutschler (20 | 4,051 | 4,051 | Ein weiteres Projekt , die | Open | Library of Humanities ( OLH | open |
| [13] - Thomas Mutschler (20 | 4,072 | 4,072 | die Herausgabe geisteswissenschaftlicher Zeitschriften in | Open | Access ( vgl . Satzinger | open |
| [13] - Thomas Mutschler (20 | 4,197 | 4,197 | zu wenig mit dem Thema | Open | Access assoziiert , digitalisierte Quellen | open |
| [13] - Thomas Mutschler (20 | 4,206 | 4,206 | digitalisierte Quellen zu wenig als | Open | Access-Angebote wahrgenommen . Regionalbibliotheken sollten | open |
| [13] - Thomas Mutschler (20 | 4,578 | 4,578 | . Macht der Siegeszug des | Open | Access Bibliotheken arbeitslos ? : | open |
| [13] - Thomas Mutschler (20 | 4,721 | 4,721 | ) : Zwischen DEAL , | Open | Access und klassischer Subskription . | open |
| [14] - Roberto Cozatl, Dani | 127 | 127 | the first steps of the | Open | Access transformation process . The | open |
| [14] - Roberto Cozatl, Dani | 188 | 188 | , to improve the way | Open | Access matters are communicated in | open |
| [14] - Roberto Cozatl, Dani | 214 | 214 | of this transformation process . | Open | Access movement , Saxony-Anhalt , | open |
| [14] - Roberto Cozatl, Dani | 223 | 223 | Saxony-Anhalt , University libraries , | Open | Access publishing Veröffentlichung : 11.08.2021 | open |
| [14] - Roberto Cozatl, Dani | 424 | 424 | hat sich die Förderung von | Open | Science im Allgemeinen und Open | open |
| [14] - Roberto Cozatl, Dani | 429 | 429 | Open Science im Allgemeinen und | Open | Access im Besonderen1 zur Aufgabe | open |
| [14] - Roberto Cozatl, Dani | 1,146 | 1,146 | ihre Schriftenreihen mithilfe der ULB | Open | Access publizieren möchte . Eine | open |
| [14] - Roberto Cozatl, Dani | 1,501 | 1,501 | Wissenschaftler von den Vorteilen von | Open | Access und die finanziellen und | open |
| [14] - Roberto Cozatl, Dani | 1,676 | 1,676 | da die Arbeit im Bereich | Open | Science unmittelbar abhängig von IT-Prozessen | open |
| [14] - Roberto Cozatl, Dani | 1,901 | 1,901 | routinemäßig zu unterstützen . Das | Open | Science Team bildet dabei eine | open |
| [14] - Roberto Cozatl, Dani | 2,273 | 2,273 | erarbeitet und vereinbart . 3.2.1 | Open | Access Policy Die Open Access | open |
| [14] - Roberto Cozatl, Dani | 2,277 | 2,277 | 3.2.1 Open Access Policy Die | Open | Access Policy der MLU Halle-Wittenberg6 | open |
| [14] - Roberto Cozatl, Dani | 2,310 | 2,310 | diese Einrichtungen zur Unterstützung von | Open | Access gemäß der Berliner Erklärung | open |
| [14] - Roberto Cozatl, Dani | 2,765 | 2,765 | zu administrieren . OJS Das | Open | Journal System der ULB wurde | open |
| [14] - Roberto Cozatl, Dani | 2,779 | 2,779 | technischen und redaktionellen Betreuung von | Open | Access-Zeitschriften bereits 2016 eingerichtet und | open |
| [14] - Roberto Cozatl, Dani | 2,789 | 2,789 | und ermöglicht die Erstellung von | Open | Access Zeitschriften inklusive der Abbildung | open |
| [14] - Roberto Cozatl, Dani | 2,893 | 2,893 | wird , zur Herausgabe der | Open | Access Zeitschrift „ NAL-Live " | open |
| [14] - Roberto Cozatl, Dani | 3,024 | 3,024 | Fachwissen für die Publikation von | Open | Access und der Nutzung geeigneter | open |
| [14] - Roberto Cozatl, Dani | 3,257 | 3,257 | die ULB ihren Service um | Open | Monograph Press für Schriftenreihen erweitern | open |
| [14] - Roberto Cozatl, Dani | 3,292 | 3,292 | für Universitäten und Verlage in | Open | Source anbieten zu können . | open |
| [14] - Roberto Cozatl, Dani | 3,309 | 3,309 | weitere 10 neue Schriftenreihen in | Open | Access verfügbar gemacht und ein | open |
| [14] - Roberto Cozatl, Dani | 3,556 | 3,556 | stattfinden . Gezielt unterstützt das | Open | Science Team der ULB bei | open |
| [14] - Roberto Cozatl, Dani | 3,779 | 3,779 | Artikeln in bereits bestehenden Gold | Open | Access-Zeitschriften und als OA-Monografien als | open |
| [14] - Roberto Cozatl, Dani | 3,806 | 3,806 | regelmäßig und transparent über die | Open | APC Initiative veröffentlicht16 und zeigen | open |
| [14] - Roberto Cozatl, Dani | 3,824 | 3,824 | Steigung des Anteiles an Gold | Open | Access Publikationen von 22 % | open |
| [14] - Roberto Cozatl, Dani | 4,261 | 4,261 | Bewusstsein für die Bedeutung von | Open | Access zu schaffen und die | open |
| [14] - Roberto Cozatl, Dani | 4,679 | 4,679 | Solomon , David 2012 . | Open | access versus subscription journals : | open |
| [14] - Roberto Cozatl, Dani | 4,712 | 4,712 | . a . 2019 . | Open | Science und die Bibliothek – | open |
| [14] - Roberto Cozatl, Dani | 4,797 | 4,797 | , Christian 2018 . Von | Open | Access zu Open Science : | open |
| [14] - Roberto Cozatl, Dani | 4,800 | 4,800 | . Von Open Access zu | Open | Science : Zum Wandel digitaler | open |
| [14] - Roberto Cozatl, Dani | 4,830 | 4,830 | wissenschaftliche Bibliotheken : Das Beispiel | Open | Science Lab . o-bib . | open |
| [14] - Roberto Cozatl, Dani | 4,871 | 4,871 | of academic libraries in propagating | open | science : A qualitative literature | open |
| [14] - Roberto Cozatl, Dani | 4,990 | 4,990 | Suber , Peter 2012 . | Open | access . MIT Press , | open |
| [14] - Roberto Cozatl, Dani | 5,009 | 5,009 | Suber , Peter 2004 . | Open | Access Overview . http://legacy.earlham.edu/~peters/fos/overview.htm. Willinsky | open |
| [14] - Roberto Cozatl, Dani | 5,019 | 5,019 | Willinsky , John 2005 . | Open | Journal Systems : An example | open |
| [14] - Roberto Cozatl, Dani | 5,026 | 5,026 | Systems : An example of | open | source software for journal management | open |
| [14] - Roberto Cozatl, Dani | 5,055 | 5,055 | 2003 . Berlin Declaration on | Open | Access to Knowledge in the | open |
| [14] - Roberto Cozatl, Dani | 5,100 | 5,100 | sowohl um den regelmäßig stattfindenden | Open | Science-Workshop , der in der | open |
| [14] - Roberto Cozatl, Dani | 5,134 | 5,134 | auch verschiedene gezielte Schulungsangebote zu | Open | Access und anderen Themen . | open |
| [15] - Wolf Christoph Seife | 89 | 89 | As a result of the | Open | Access Transformation , regional libraries | open |
| [15] - Wolf Christoph Seife | 155 | 155 | outlines the status of the | Open | Access transformation in regional libraries | open |
| [15] - Wolf Christoph Seife | 180 | 180 | project . regional library , | Open | Access transformation , services , | open |
| [15] - Wolf Christoph Seife | 202 | 202 | . 1 ( 2021 ) | Open | Access ist für den deutschen | open |
| [15] - Wolf Christoph Seife | 331 | 331 | Bibliotheken wird das Feld ‚ | Open | Access und neue Formen der | open |
| [15] - Wolf Christoph Seife | 705 | 705 | Meinungsbild und eine Bestandsaufnahme der | Open | Access Services an Regionalbibliotheken angestrebt | open |
| [15] - Wolf Christoph Seife | 1,629 | 1,629 | nachhaltige und dauerhafte Förderung der | Open | Access Transformation , in dem | open |
| [15] - Wolf Christoph Seife | 1,800 | 1,800 | nachhaltigen und dauerhaften Förderung von | Open | Access in der Fläche " | open |
| [15] - Wolf Christoph Seife | 2,495 | 2,495 | Strukturen , die das Thema | Open | Access betreffen , sind in | open |
| [15] - Wolf Christoph Seife | 2,551 | 2,551 | hin : Dass das Thema | Open | Access an Universitätsbibliotheken , die | open |
| [15] - Wolf Christoph Seife | 2,720 | 2,720 | Mitarbeiter * innen im Bereich | Open | Access ausbilden ( lassen ) | open |
| [15] - Wolf Christoph Seife | 2,752 | 2,752 | Mitarbeiter * innen zum Thema | Open | Access geschult . Auch wenn | open |
| [15] - Wolf Christoph Seife | 3,286 | 3,286 | Auch Beratungsangebote zur Publikation im | Open | Access sind an den UBs | open |
| [15] - Wolf Christoph Seife | 3,383 | 3,383 | sind , zu Publikationsmöglichkeiten in | Open | Access ( Werte gerundet ) | open |
| [15] - Wolf Christoph Seife | 3,403 | 3,403 | Infrastrukturangeboten für die Publikation im | Open | Access wie etwa dem Hosting | open |
| [15] - Wolf Christoph Seife | 3,940 | 3,940 | , generelle Bewertungen zum Thema | Open | Access im Allgemeinen und zum | open |
| [15] - Wolf Christoph Seife | 4,072 | 4,072 | bewertet den generellen Stellenwert von | Open | Access als hoch und eher | open |
| [15] - Wolf Christoph Seife | 4,256 | 4,256 | Bibliotheken die Entwicklungen im Bereich | Open | Access noch am Anfang zu | open |
| [15] - Wolf Christoph Seife | 4,360 | 4,360 | sein , der dem Thema | Open | Access generell in Regionalbibliotheken eingeräumt | open |
| [15] - Wolf Christoph Seife | 4,443 | 4,443 | im Allgemeinen und dem Arbeitsgebiet | Open | Access im Besonderen aufgeschlossen gegenüber | open |
| [15] - Wolf Christoph Seife | 4,697 | 4,697 | Herausforderung bei der Entwicklung von | Open | Access-Services – vor allem auf | open |
| [15] - Wolf Christoph Seife | 5,130 | 5,130 | Blick auf die Etablierung von | Open | Access veränderten Aufgaben und Tätigkeitsfeldern | open |
| [15] - Wolf Christoph Seife | 5,327 | 5,327 | nachhaltigen und dauerhaften Förderung von | Open | Access in der Fläche " | open |
| [15] - Wolf Christoph Seife | 5,554 | 5,554 | Strukturen , die das Thema | Open | Access betreffen , sind in | open |
| [15] - Wolf Christoph Seife | 5,604 | 5,604 | MitarbeiterInnen , eigene Publikationen im | Open | Access zu veröffentlichen . / | open |
| [15] - Wolf Christoph Seife | 5,617 | 5,617 | schult die eigenen MitarbeiterInnen zu | Open | Access oder lässt MitarbeiterInnen in | open |
| [15] - Wolf Christoph Seife | 5,988 | 5,988 | sind , zu Publikationsmöglichkeiten in | Open | Access . Bitte wählen Sie | open |
| [15] - Wolf Christoph Seife | 6,583 | 6,583 | Wir bieten Informationen zum Thema | Open | Access auf unserer Homepage an | open |
| [15] - Wolf Christoph Seife | 6,614 | 6,614 | gedrucktes Informations- und Schulungsmaterial zu | Open | Access bereit . Bitte wählen | open |
| [15] - Wolf Christoph Seife | 6,643 | 6,643 | Organisationen und Institutionen im Bereich | Open | Access . Bitte wählen Sie | open |
| [15] - Wolf Christoph Seife | 6,670 | 6,670 | mit anderen Institutionen im Bereich | Open | Access . Bitte wählen Sie | open |
| [15] - Wolf Christoph Seife | 6,730 | 6,730 | mit anderen Institutionen im Bereich | Open | Access . ] ) 6 | open |
| [15] - Wolf Christoph Seife | 7,028 | 7,028 | der weiteren Perspektiven im Bereich | Open | Access . 1 . Wie | open |
| [15] - Wolf Christoph Seife | 7,046 | 7,046 | sein , der dem Thema | Open | Access generell in Regionalbibliotheken eingeräumt | open |
| [15] - Wolf Christoph Seife | 7,431 | 7,431 | Elmar ( 2018 ) : | Open | Access : Wissenschaft , Verlage | open |
| [16] - Martin Munke, Daniel | 71 | 71 | unter Nutzung offener Systeme ( | Open | Journal Systems ) zu einer | open |
| [16] - Martin Munke, Daniel | 81 | 81 | einer möglichst offenen Erscheinungsweise ( | Open | Access ) zu bringen . | open |
| [16] - Martin Munke, Daniel | 89 | 89 | zu bringen . Landesbibliothek , | Open | Access , Open Journal Systems | open |
| [16] - Martin Munke, Daniel | 92 | 92 | Landesbibliothek , Open Access , | Open | Journal Systems , Fachzeitschrift , | open |
| [16] - Martin Munke, Daniel | 156 | 156 | make these journals available as | open | as possible ( Open Access | open |
| [16] - Martin Munke, Daniel | 160 | 160 | as open as possible ( | Open | Access ) , using also | open |
| [16] - Martin Munke, Daniel | 166 | 166 | Access ) , using also | open | systems ( Open Journal Systems | open |
| [16] - Martin Munke, Daniel | 169 | 169 | using also open systems ( | Open | Journal Systems ) . regional | open |
| [16] - Martin Munke, Daniel | 177 | 177 | ) . regional library , | Open | Access , Open Journal Systems | open |
| [16] - Martin Munke, Daniel | 180 | 180 | library , Open Access , | Open | Journal Systems , journal , | open |
| [16] - Martin Munke, Daniel | 203 | 203 | 1 ( 2021 ) Die | Open | Access-Transformation macht auch vor den | open |
| [16] - Martin Munke, Daniel | 620 | 620 | die Steigerung der Anteile von | Open | Access-Publikationen ( vgl . Rösch | open |
| [16] - Martin Munke, Daniel | 773 | 773 | anschließend die konkreten Schritte zur | Open | Access-Stellung skizziert ( Abschnitt 5 | open |
| [16] - Martin Munke, Daniel | 1,606 | 1,606 | und von der SLUB weiterentwickelten | Open | Source-Discovery-Lösung , typo3find ’ nutzbar | open |
| [16] - Martin Munke, Daniel | 3,235 | 3,235 | Forschungsarbeiten , bevorzugt unter einer | Open | Access-kompatiblen Creative Commons-Lizenz . So | open |
| [16] - Martin Munke, Daniel | 3,831 | 3,831 | , die den Auftakt zur | Open | Access-Stellung durch die SLUB bilden | open |
| [16] - Martin Munke, Daniel | 5,221 | 5,221 | die Überführung bestehender Subskriptionsmodelle in | Open | Access . Als Service werden | open |
| [16] - Martin Munke, Daniel | 5,348 | 5,348 | basiert auf der Open-Source-Software , | Open | Journal Systems ’ ( OJS | open |
| [16] - Martin Munke, Daniel | 5,413 | 5,413 | einzusetzen . So können neben | Open | Access-Zeitschriften gleichfalls andere Veröffentlichungsmodelle verwaltet | open |
| [16] - Martin Munke, Daniel | 5,428 | 5,428 | beispielsweise erst verzögert ( Delayed | Open | Access ) oder gänzlich abonnementgestützt | open |
| [16] - Martin Munke, Daniel | 5,537 | 5,537 | für die infrastrukturellen Voraussetzungen von | Open | Access ( vgl . Oberländer | open |
| [16] - Martin Munke, Daniel | 5,576 | 5,576 | als subskriptionspflichtige Printmedien erhältlich . | Open | Access als wichtige Bibliotheksstrategie weiter | open |
| [16] - Martin Munke, Daniel | 5,617 | 5,617 | von der Retrodigitalisierung hin zur | Open | Access-Veröffentlichung solcher Journale . Mit | open |
| [16] - Martin Munke, Daniel | 5,726 | 5,726 | in diesem Fall der Delayed | Open | Access mit einem digitalen Zugang | open |
| [16] - Martin Munke, Daniel | 5,765 | 5,765 | SHB und NASG als Delayed | Open | Access-Publikationen digital veröffentlicht , wobei | open |
| [16] - Martin Munke, Daniel | 5,819 | 5,819 | der derzeitigen Herausgeber , in | Open | Access überführt , was den | open |
| [16] - Martin Munke, Daniel | 5,887 | 5,887 | Ziel der Bibliothek . Eine | Open | Access-Veröffentlichung dieser landeskundlichen Publikationen samt | open |
| [16] - Martin Munke, Daniel | 6,052 | 6,052 | Herausgeber * innen und an | Open | Access Interessierte darüber hinaus hinsichtlich | open |
| [16] - Martin Munke, Daniel | 6,123 | 6,123 | sich hinter dem Begriffspaar „ | Open | Access und Recht “ . | open |
| [16] - Martin Munke, Daniel | 6,136 | 6,136 | einer Erstveröffentlichung von Werken in | Open | Access-Zeitschriften Autor * innen ( | open |
| [16] - Martin Munke, Daniel | 6,331 | 6,331 | etwaige Vorbehalte gegenüber dem Modell | Open | Access abzubauen . Bessere Sichtbarkeit | open |
| [16] - Martin Munke, Daniel | 6,353 | 6,353 | Langzeitspeicherung sind als Argumente pro | Open | Access ( vgl . Brinken | open |
| [16] - Martin Munke, Daniel | 6,413 | 6,413 | „ Grüne Weg " des | Open | Access-Publizierens nicht notwendigerweise unwirtschaftlich sein | open |
| [16] - Martin Munke, Daniel | 6,536 | 6,536 | vom Retrodigitalisat der Zeitschriftenausgabe zur | Open | Access-Publikation auf , Qucosa.Journals ’ | open |
| [16] - Martin Munke, Daniel | 6,774 | 6,774 | Retrodigitalisierung als auch in der | Open | Access-Veröffentlichung landeshistorisch relevanter Literatur lassen | open |
| [16] - Martin Munke, Daniel | 6,888 | 6,888 | die Bibliothek das Bekenntnis zu | Open | Science – und besonders Open | open |
| [16] - Martin Munke, Daniel | 6,893 | 6,893 | Open Science – und besonders | Open | Access als einem wichtigen Aspekt | open |
| [16] - Martin Munke, Daniel | 6,945 | 6,945 | daran , landeshistorische Zeitschriften in | Open | Access zu überführen , entsprechende | open |
| [16] - Martin Munke, Daniel | 7,012 | 7,012 | sowie künftiger Ausgaben im Delayed | Open | Access von ‚ Sächsischen Heimatblättern | open |
| [16] - Martin Munke, Daniel | 7,088 | 7,088 | * innen für das Modell | Open | Access zu gewinnen , zu | open |
| [16] - Martin Munke, Daniel | 7,133 | 7,133 | Einfluss freier Zugänglichkeit im Delayed | Open | Access auf klassische Subskriptionsmodelle zu | open |
| [16] - Martin Munke, Daniel | 7,245 | 7,245 | und weitere Schritte hin zum | Open | Access zu gehen . Archiv | open |
| [16] - Martin Munke, Daniel | 7,841 | 7,841 | Martin ( 2021 ) . | Open | Citizen Science . Leitbild für | open |
| [16] - Martin Munke, Daniel | 8,275 | 8,275 | ) : 10 Gründe für | Open | Access . In open-access.network . | open |
| [16] - Martin Munke, Daniel | 8,542 | 8,542 | : so gut wie kein | Open | Access . In Archivalia . | open |
| [16] - Martin Munke, Daniel | 8,561 | 8,561 | Klaus ( 2021b ) . | Open | Access bei den führenden deutschen | open |
| [16] - Martin Munke, Daniel | 8,691 | 8,691 | Thomas ( 2017 ) . | Open | Access rechtlich absichern - warum | open |
| [16] - Martin Munke, Daniel | 8,717 | 8,717 | Hg . ) . Praxishandbuch | Open | Access . Berlin / Boston | open |
| [16] - Martin Munke, Daniel | 9,625 | 9,625 | 2017 ) . Förderung von | Open | Access über institutionelle Infrastrukturen , | open |
| [16] - Martin Munke, Daniel | 9,648 | 9,648 | Hg . ) . Praxishandbuch | Open | Access . Berlin / Boston | open |
| [16] - Martin Munke, Daniel | 9,690 | 9,690 | John ( 2005 ) , | Open | Journal Systems : An example | open |
| [16] - Martin Munke, Daniel | 9,697 | 9,697 | Systems : An example of | open | source software for journal management | open |
| [17] - Colette Knight, Tama | 37 | 37 | vorübergehend auf Online-Lehre umzustellen . | Open | Educational Resources ( OER ) | open |
| [17] - Colette Knight, Tama | 98 | 98 | Beitrag beschreiben wir Beispiele von | Open | Education Resources , die an | open |
| [17] - Colette Knight, Tama | 119 | 119 | , die gemacht wurden . | Open | Educational Resources ( OER ) | open |
| [17] - Colette Knight, Tama | 161 | 161 | , at least temporarily . | Open | Educational Resources ( OER ) | open |
| [17] - Colette Knight, Tama | 217 | 217 | article we describe examples of | Open | Education Resources that have been | open |
| [17] - Colette Knight, Tama | 242 | 242 | learned during their implementation . | Open | Educational Resources ( OER ) | open |
| [17] - Colette Knight, Tama | 472 | 472 | neuen Anforderungen gerecht werden . | Open | Educational Resources ( OER ) | open |
| [17] - Colette Knight, Tama | 537 | 537 | Papier beschreiben wir Beispiele von | Open | Education Resources , die an | open |
| [17] - Colette Knight, Tama | 4,296 | 4,296 | International Review of Research in | Open | and Distributed Learning , 16 | open |
| [17] - Colette Knight, Tama | 4,323 | 4,323 | ( 2015 ) : Whitepaper | Open | Educational Resources ( OER ) | open |
| [17] - Colette Knight, Tama | 4,383 | 4,383 | In : The Online , | Open | and Flexible Higher Education Conference | open |
| [17] - Colette Knight, Tama | 4,447 | 4,447 | Jöran ( 2018 ) : | Open | Educational Resources in Germany State | open |
| [18] - Markus Putnings (202 | 38 | 38 | anhand vier Bereiche gegliedert : | Open | Science , Software , Kommunikation | open |
| [18] - Markus Putnings (202 | 136 | 136 | divided into four areas : | open | science , software , communication | open |
| [18] - Markus Putnings (202 | 1,173 | 1,173 | Autors als Leiter des Referats | Open | Access geprägt . Siehe auch | open |
| [19] - Irene Barbers, Sonja | 18 | 18 | 2010 stellt das DFG-Programm „ | Open | Access Publizieren “ ein zentrales | open |
| [19] - Irene Barbers, Sonja | 29 | 29 | Instrument zur institutionellen Förderung von | Open | Access-Publikationen an deutschen Universitäten dar | open |
| [19] - Irene Barbers, Sonja | 97 | 97 | angesiedelten Publikationsfonds verfügen . Das | Open | Access-Publizieren ist Trend an deutschen | open |
| [19] - Irene Barbers, Sonja | 110 | 110 | wie die Verzehnfachung der Gold | Open | Access-Quote an den geförderten und | open |
| [19] - Irene Barbers, Sonja | 128 | 128 | zeigt . Von einer vollständigen | Open | Access-Transformation ist das deutsche universitäre | open |
| [19] - Irene Barbers, Sonja | 199 | 199 | am Ende des Beitrags . | Open | Access ; Open Access Monitoring | open |
| [19] - Irene Barbers, Sonja | 202 | 202 | Beitrags . Open Access ; | Open | Access Monitoring ; DFG ; | open |
| [19] - Irene Barbers, Sonja | 220 | 220 | , the funding programme „ | Open | Access Publishing “ , offered | open |
| [19] - Irene Barbers, Sonja | 245 | 245 | for the institutional funding of | Open | Access publications at German universities | open |
| [19] - Irene Barbers, Sonja | 307 | 307 | funded universities . These include | Open | Access publication funds , which | open |
| [19] - Irene Barbers, Sonja | 321 | 321 | by the university libraries . | Open | Access publishing has become a | open |
| [19] - Irene Barbers, Sonja | 342 | 342 | tenfold increase in the Gold | Open | Access rate of both funded | open |
| [19] - Irene Barbers, Sonja | 391 | 391 | a thorough transition towards an | Open | Access system . With a | open |
| [19] - Irene Barbers, Sonja | 452 | 452 | conducting future monitoring processes . | Open | Access ; Open Access Monitoring | open |
| [19] - Irene Barbers, Sonja | 455 | 455 | processes . Open Access ; | Open | Access Monitoring ; DFG ; | open |
| [19] - Irene Barbers, Sonja | 473 | 473 | Einleitung : Das DFG-Förderprogramm „ | Open | Access Publizieren “ 2 Methodik | open |
| [19] - Irene Barbers, Sonja | 508 | 508 | of Science 2.4 Ermittlung des | Open | Access-Status und Zuordnung zu Verlagen | open |
| [19] - Irene Barbers, Sonja | 586 | 586 | geförderte Universitäten im Vergleich 4 | Open | Access als Trend , Preissteigerungen | open |
| [19] - Irene Barbers, Sonja | 612 | 612 | Weltweit treiben wissenschaftspolitische Rahmenbedingungen die | Open | Access-Transformation voran . Große Förderprogramme | open |
| [19] - Irene Barbers, Sonja | 625 | 625 | 2020 der Europäischen Union , | Open | Access Policies auf Landesebene sowie | open |
| [19] - Irene Barbers, Sonja | 646 | 646 | flächendeckende Akzeptanz und Etablierung von | Open | Access befördern . 1 Für | open |
| [19] - Irene Barbers, Sonja | 727 | 727 | Publikationszahlen und -kosten für goldenes | Open | Access an den geförderten Universitäten | open |
| [19] - Irene Barbers, Sonja | 1,990 | 1,990 | eines Datenabzugs von Unpaywall10 der | Open | Access-Status ermittelt . Dabei wurden | open |
| [19] - Irene Barbers, Sonja | 2,097 | 2,097 | Der Artikel ist in einem | Open | Access-Journal ( DOAJ-indexiert13 ) veröffentlicht | open |
| [19] - Irene Barbers, Sonja | 2,148 | 2,148 | false Der Artikel hat eine | Open | Access-Lizenz und ist in einer | open |
| [19] - Irene Barbers, Sonja | 2,164 | 2,164 | Hybrid : Free under an | open | license in a toll access | open |
| [19] - Irene Barbers, Sonja | 2,200 | 2,200 | , hat aber keine nachgewiesene | Open | Access-Lizenz . Unknown is_oa = | open |
| [19] - Irene Barbers, Sonja | 2,233 | 2,233 | : Schema zur Ermittlung des | Open | Access-Status im Unpaywall-Datenbestand . Die | open |
| [19] - Irene Barbers, Sonja | 2,294 | 2,294 | anschließend mit dem Datenbestand des | Open | Access Monitors des Forschungszentrums Jülich15 | open |
| [19] - Irene Barbers, Sonja | 2,360 | 2,360 | die Entwicklung von Publikationszahlen und | Open | Access-Quoten präsentiert . Die Daten | open |
| [19] - Irene Barbers, Sonja | 2,892 | 2,892 | , gefolgt von den genuinen | Open | Access-Verlagen Public Library of Science | open |
| [19] - Irene Barbers, Sonja | 3,486 | 3,486 | Zuordnung zu den Zeitschriften : | Open | Access Monitor des Forschungszentrums Jülich | open |
| [19] - Irene Barbers, Sonja | 3,544 | 3,544 | Vergleich anhand der Publikationszahlen und | Open | Access-Quoten zeigt , dass in | open |
| [19] - Irene Barbers, Sonja | 3,573 | 3,573 | 7 die Anteile der goldenen | Open | Access-Publikationen an allen Publikationen der | open |
| [19] - Irene Barbers, Sonja | 3,588 | 3,588 | geförderten Einrichtungen dargestellt ( Gold | Open | Access-Quote ) . Dabei zeigt | open |
| [19] - Irene Barbers, Sonja | 3,599 | 3,599 | sich , dass die Gold | Open | Access-Quote der geförderten Universitäten meist | open |
| [19] - Irene Barbers, Sonja | 3,647 | 3,647 | Abbildungen ist die Entwicklung von | Open | Access in geförderten und nicht | open |
| [19] - Irene Barbers, Sonja | 3,667 | 3,667 | Verteilung von Closed Access- und | Open | Access-Anteilen ( in den verschiedenen | open |
| [19] - Irene Barbers, Sonja | 3,701 | 3,701 | die Varianten Closed Access sowie | Open | Access in den Ausprägungen bronze | open |
| [19] - Irene Barbers, Sonja | 3,762 | 3,762 | . Eine Erhöhung des gesamten | Open | Access-Anteils ist sowohl bei den | open |
| [19] - Irene Barbers, Sonja | 3,788 | 3,788 | Verhältnis von Closed Access zu | Open | Access am Ende des Betrachtungszeitraums | open |
| [19] - Irene Barbers, Sonja | 3,812 | 3,812 | Einrichtungen gleichermaßen , dass hybrider | Open | Access insbesondere zwischen 2011 und | open |
| [19] - Irene Barbers, Sonja | 3,842 | 3,842 | präsentiert die Entwicklung der verschiedenen | Open | Access-Kategorien der geförderten Universitäten für | open |
| [19] - Irene Barbers, Sonja | 3,860 | 3,860 | die Quote für den grünen | Open | Access ziemlich konstant bleibt , | open |
| [19] - Irene Barbers, Sonja | 3,873 | 3,873 | bis 2016 für den bronzenen | Open | Access ab . Die Quote | open |
| [19] - Irene Barbers, Sonja | 3,882 | 3,882 | Die Quote für den hybriden | Open | Access steigt bis 2016 mit | open |
| [19] - Irene Barbers, Sonja | 3,906 | 3,906 | die Quote für den goldenen | Open | Access ziemlich kontinuierlich an und | open |
| [19] - Irene Barbers, Sonja | 3,925 | 3,925 | zeigt , wie sich die | Open | Access-Quoten der nicht geförderten Universitäten | open |
| [19] - Irene Barbers, Sonja | 3,943 | 3,943 | Sowohl die Entwicklung des hybriden | Open | Access als auch des grünen | open |
| [19] - Irene Barbers, Sonja | 3,949 | 3,949 | Access als auch des grünen | Open | Access vollzieht sich wie bei | open |
| [19] - Irene Barbers, Sonja | 3,966 | 3,966 | die Abwärtskurve für die bronzene | Open | Access-Quote der nicht geförderten Universitäten | open |
| [19] - Irene Barbers, Sonja | 4,000 | 4,000 | die Quote für den goldenen | Open | Access an , wobei zwischen | open |
| [19] - Irene Barbers, Sonja | 4,037 | 4,037 | einen Beitrag zum Voranschreiten der | Open | Access-Transformation leisten , dass Hürden | open |
| [19] - Irene Barbers, Sonja | 4,047 | 4,047 | Hürden für die Publikation in | Open | Access-Zeitschriften gesenkt werden . Als | open |
| [19] - Irene Barbers, Sonja | 4,064 | 4,064 | Entwicklung des Anteils der Gold | Open | Access-Publikationen verstanden werden . Tabelle | open |
| [19] - Irene Barbers, Sonja | 4,074 | 4,074 | Tabelle 5 stellt die Gold | Open | Access-Quoten der Gruppen „ geförderte | open |
| [19] - Irene Barbers, Sonja | 4,146 | 4,146 | % Tabelle 5 : Gold | Open | Access-Quote in ausgewählten Jahren In | open |
| [19] - Irene Barbers, Sonja | 4,158 | 4,158 | Einrichtungen hat sich die Gold | Open | Access-Quote zwischen 2006 und 2017 | open |
| [19] - Irene Barbers, Sonja | 4,199 | 4,199 | . Der Anstieg der Gold | Open | Access-Quoten zeigt , dass sich | open |
| [19] - Irene Barbers, Sonja | 4,205 | 4,205 | Access-Quoten zeigt , dass sich | Open | Access in Deutschland durchzusetzen beginnt | open |
| [19] - Irene Barbers, Sonja | 4,238 | 4,238 | Universitäten , was ihre Gold | Open | Access-Quoten betrifft , nicht weiter | open |
| [19] - Irene Barbers, Sonja | 4,307 | 4,307 | + 5 % ) Gold | Open | Access zwar zunehmende Marktanteile behaupten | open |
| [19] - Irene Barbers, Sonja | 4,330 | 4,330 | Transformation des Publikationswesens in den | Open | Access – aber noch weit | open |
| [19] - Irene Barbers, Sonja | 4,661 | 4,661 | wie sich das DFG-Programm „ | Open | Access Publizieren “ auf Einrichtungsebene | open |
| [19] - Irene Barbers, Sonja | 4,729 | 4,729 | DFG-Programms auf die Zahl der | Open | Access-Publikationen nachgewiesen werden kann . | open |
| [19] - Irene Barbers, Sonja | 4,925 | 4,925 | . Wie lässt sich ein | Open | Access-Monitoring künftig so gestalten , | open |
| [19] - Irene Barbers, Sonja | 5,111 | 5,111 | für ein lückenloses Kosten-Monitoring von | Open | Access-Publikationen dar : Datum Erläuterung | open |
| [19] - Irene Barbers, Sonja | 5,388 | 5,388 | Namensliste ( perspektivisch durch den | Open | Access-Monitor31 ) erleichtert werden . | open |
| [19] - Irene Barbers, Sonja | 5,539 | 5,539 | welche Daten für ein umfängliches | Open | Access-Monitoring erfasst werden sollen , | open |
| [19] - Irene Barbers, Sonja | 5,587 | 5,587 | automatisierten Hochschulbibliographien und Forschungsinformationssystemen für | Open | Access-Monitoringzwecke diskutiert , bereits eingesetzt | open |
| [19] - Irene Barbers, Sonja | 5,616 | 5,616 | Anforderungen an ein Berichtswesen im | Open | Access-Publizieren nachkommen zu können . | open |
| [19] - Irene Barbers, Sonja | 5,634 | 5,634 | Einrichtungen , die ein lokales | Open | Access-Monitoring betreiben , durch ein | open |
| [19] - Irene Barbers, Sonja | 5,682 | 5,682 | Monitoring-Systeme wie OpenAPC und den | Open | Access Monitor möglich ist . | open |
| [19] - Irene Barbers, Sonja | 5,807 | 5,807 | Arbeiten im Rahmen der Global | Open | Knowledgebase ( GOKb ) 38 | open |
| [19] - Irene Barbers, Sonja | 5,837 | 5,837 | die Bearbeitung von Gebühren für | Open | Access-Publikationen vollständig über die Bibliothek | open |
| [19] - Irene Barbers, Sonja | 6,036 | 6,036 | einem möglichst lückenlosen Kosten-Monitoring im | Open | Access ebnet . Danowski , | open |
| [19] - Irene Barbers, Sonja | 6,051 | 6,051 | 2019 . AT2OA Report : | Open | Access Monitoring – Approaches and | open |
| [19] - Irene Barbers, Sonja | 6,073 | 6,073 | Forschungsgemeinschaft 2019 . Förderprogramm „ | Open | Access Publizieren “ . URL | open |
| [19] - Irene Barbers, Sonja | 6,197 | 6,197 | . 2020 . Das DFG-Förderprogramm | Open | Access Publizieren : Bericht über | open |
| [19] - Irene Barbers, Sonja | 6,230 | 6,230 | and Price Insensitivity : An | Open | Access Sequel to the Serials | open |
| [19] - Irene Barbers, Sonja | 6,287 | 6,287 | u.a . 2018 . Der | Open | Access Monitor Deutschland . o-bib | open |
| [19] - Irene Barbers, Sonja | 6,396 | 6,396 | Pampel , Heinz 2019 . | Open | Access an wissenschaftlichen Einrichtungen in | open |
| [19] - Irene Barbers, Sonja | 6,443 | 6,443 | the prevalence and impact of | Open | Access articles . PeerJ 6 | open |
| [19] - Irene Barbers, Sonja | 6,570 | 6,570 | the necessary large-scale transformation to | open | access . URL : http://dx.doi.org/10.17617/1.3 | open |
| [19] - Irene Barbers, Sonja | 6,586 | 6,586 | Tobias , Regine 2019 . | Open | Access in einer Forschungseinrichtung : | open |
| [19] - Irene Barbers, Sonja | 6,773 | 6,773 | der Schweizerische Nationalfonds sowie das | Open | Access Mandat des FWF in | open |
| [19] - Irene Barbers, Sonja | 7,027 | 7,027 | Piwowar u.a . 2018 15 | Open | Access Monitor . https://open-access-monitor.de/#/ ; | open |
| [19] - Irene Barbers, Sonja | 7,350 | 7,350 | an Rechnungsdaten , die in | Open | Access-Monitoringberichte einfließen sollten , liefern | open |
| [19] - Irene Barbers, Sonja | 7,382 | 7,382 | Selbstverständnis umfasst sie allerdings nur | Open | Access-Publikationsgebühren . 35 Zur Heterogenität | open |
| [19] - Irene Barbers, Sonja | 7,416 | 7,416 | für den Einsatz für ein | Open | Access-Monitoring ( vgl . Danowski | open |
| [19] - Irene Barbers, Sonja | 7,499 | 7,499 | mit der Möglichkeit eines integrierten | Open | Access-Monitorings ( vgl . Scheffler | open |
| [19] - Irene Barbers, Sonja | 7,532 | 7,532 | das Problem der Vollständigkeit von | Open | Access-Publikationsdaten in den sozial- und | open |
| [19] - Irene Barbers, Sonja | 7,565 | 7,565 | auch aus dem Bedarf eines | Open | Access-Kostenmonitorings ergaben , ist unklar | open |
| [20] - Stefanie Hanneken, A | 138 | 138 | Verlages im Jahr 2020 . | Open | Access , Geschäftsmodell , Wissenschaftliches | open |
| [20] - Stefanie Hanneken, A | 161 | 161 | project “ National Contact Point | Open | Access OA2020-DE ” is to | open |
| [20] - Stefanie Hanneken, A | 302 | 302 | front list in 2020 . | open | access , business models , | open |
| [20] - Stefanie Hanneken, A | 369 | 369 | der Anteil an unmittelbar im | Open | Access veröffentlichten Zeitschriften und -artikeln | open |
| [20] - Stefanie Hanneken, A | 692 | 692 | die mehr oder weniger unsystematisch | Open | Access zur Verfügung gestellt werden | open |
| [20] - Stefanie Hanneken, A | 707 | 707 | sind Rechtsfragen in Zusammenhang mit | Open | Access , etwa im Bereich | open |
| [20] - Stefanie Hanneken, A | 1,236 | 1,236 | ist bspw . die transcript | OPEN | Library Politikwissenschaft , die darauf | open |
| [20] - Stefanie Hanneken, A | 1,261 | 1,261 | ( transcript ) unmittelbar im | Open | Access zu publizieren . Dafür | open |
| [20] - Stefanie Hanneken, A | 1,312 | 1,312 | wie das Modell der transcript | OPEN | Library Politikwissenschaft zusammengesetzt ist und | open |
| [20] - Stefanie Hanneken, A | 1,410 | 1,410 | basiert das Open-Access-Geschäftsmodell der transcript | OPEN | Library auch auf diesem Modell | open |
| [20] - Stefanie Hanneken, A | 1,442 | 1,442 | die Bereitstellung der Literatur im | Open | Access . Eine Frontlist ist | open |
| [20] - Stefanie Hanneken, A | 1,502 | 1,502 | können . Für die transcript | OPEN | Library Politikwissenschaft bedeutet das , | open |
| [20] - Stefanie Hanneken, A | 1,521 | 1,521 | Verlages des Jahres 2019 im | Open | Access erscheinen . Statt wie | open |
| [20] - Stefanie Hanneken, A | 1,711 | 1,711 | . 2018 ) und dass | Open | Access somit einen zusätzlichen Vertriebskanal | open |
| [20] - Stefanie Hanneken, A | 1,747 | 1,747 | Natives . Um die Frontlist | Open | Access zu publizieren , kann | open |
| [20] - Stefanie Hanneken, A | 1,781 | 1,781 | ist . Für das transcript | OPEN | Library Modell wurde ein informelles | open |
| [20] - Stefanie Hanneken, A | 2,097 | 2,097 | wissenschaftspolitischer Anforderungen ( Etablierung von | Open | Access als Standard im wissenschaftlichen | open |
| [20] - Stefanie Hanneken, A | 2,122 | 2,122 | die Autorin zustimmt , wird | Open | Access als Standard-Publikationsmodus gesetzt . | open |
| [20] - Stefanie Hanneken, A | 2,179 | 2,179 | Dies geschieht bei der transcript | OPEN | Library durch folgende Maßnahmen : | open |
| [20] - Stefanie Hanneken, A | 2,478 | 2,478 | Bedingungen teilzunehmen . Das transcript | OPEN | Library Politikwissenschaft Modell wurde im | open |
| [20] - Stefanie Hanneken, A | 2,881 | 2,881 | lernen . Das Modell transcript | OPEN | Library Politikwissenschaften eignet sich in | open |
| [20] - Stefanie Hanneken, A | 3,126 | 3,126 | von den bisherigen Erwerbungsmodellen zu | Open | Access ohne die Dimension der | open |
| [20] - Stefanie Hanneken, A | 3,843 | 3,843 | Risiko nicht nur für das | OPEN | Library Modell , sondern für | open |
| [20] - Stefanie Hanneken, A | 3,919 | 3,919 | eignet sich das Modell transcript | OPEN | Library Politikwissenschaft vor allem für | open |
| [20] - Stefanie Hanneken, A | 4,056 | 4,056 | Mandat vorliegt16 . Das transcript | OPEN | Library Politikwissenschaft lässt sich dennoch | open |
| [20] - Stefanie Hanneken, A | 4,309 | 4,309 | Teilnahme an dem Pilotprojekt „ | OPEN | Library Politikwissenschaft " entschieden ? | open |
| [20] - Stefanie Hanneken, A | 4,337 | 4,337 | eigenen WissenschaftlerInnen ein Angebot für | Open | Access in den Geistes- und | open |
| [20] - Stefanie Hanneken, A | 4,348 | 4,348 | Sozialwissenschaften machen . Alle schätzen | Open | Access als eine wichtige Entwicklung | open |
| [20] - Stefanie Hanneken, A | 4,717 | 4,717 | . Weiterentwicklung des Pilotprojektes transcript | OPEN | Library Politikwissenschaft sind 73 % | open |
| [20] - Stefanie Hanneken, A | 4,783 | 4,783 | Ergebnis zur Frage : Den | Open | Access Flip welcher weiteren Fachbereiche | open |
| [20] - Stefanie Hanneken, A | 4,805 | 4,805 | ) Das Modell der transcript | OPEN | Library wurde von den AutorInnen | open |
| [20] - Stefanie Hanneken, A | 4,959 | 4,959 | eine erfolgreiche Fortführung der transcript | OPEN | Library Politikwissenschaft für die Frontlist | open |
| [20] - Stefanie Hanneken, A | 5,891 | 5,891 | Publikationslandschaft radikal zu verändern . | Open | Access verfolgt das Ziel , | open |
| [20] - Stefanie Hanneken, A | 5,998 | 5,998 | two different strategies to achieve | Open | Access . http://amelica.org/index.php/en/2019/02/10/amelica-vs-plan-s-same-target-two-different-strategies-to-achieve-open-access/ [ Stand | open |
| [20] - Stefanie Hanneken, A | 6,095 | 6,095 | OA Effect : How does | Open | Access Affect the Usage of | open |
| [20] - Stefanie Hanneken, A | 6,148 | 6,148 | OAPEN-NL - A Project Exploring | Open | Access Monograph Publishing in the | open |
| [20] - Stefanie Hanneken, A | 6,178 | 6,178 | . OAPEN-CH - Auswirkungen von | Open | Access auf wissenschaftliche Monographien in | open |
| [20] - Stefanie Hanneken, A | 6,346 | 6,346 | [ Stand 2020-02-13 ] . | Open | Access 2020 . Today’s Scholarly | open |
| [20] - Stefanie Hanneken, A | 6,353 | 6,353 | 2020 . Today’s Scholarly Journals | Open | , Re-Usable . https://oa2020.org/ [ | open |
| [20] - Stefanie Hanneken, A | 6,477 | 6,477 | a . 2018 . OPERAS | Open | Access Business Models White Paper | open |
| [20] - Stefanie Hanneken, A | 6,492 | 6,492 | 2020-02-13 ] . Transcript . | Open | Library Politikwissenschaft – FAQ . | open |
| [20] - Stefanie Hanneken, A | 6,544 | 6,544 | 2019 . Society Publishers Accelerating | Open | Access and Plan S - | open |
| [20] - Stefanie Hanneken, A | 6,573 | 6,573 | – Making full and immediate | Open | Access a reality . https://www.coalition-s.org/ | open |
| [20] - Stefanie Hanneken, A | 6,580 | 6,580 | a reality . https://www.coalition-s.org/ ↩ | Open | Access 2020 – Today’s scholarly | open |
| [20] - Stefanie Hanneken, A | 6,587 | 6,587 | 2020 – Today’s scholarly journals | open | , re-usable , sustainable . | open |
| [20] - Stefanie Hanneken, A | 7,013 | 7,013 | , diese in Form von | Open | Textbooks zu erstellen und zu | open |
| [20] - Stefanie Hanneken, A | 7,026 | 7,026 | Als Beispiele seien hier die | Open | Textbook Library ( https://open.umn.edu/opentextbooks ) | open |
| [20] - Stefanie Hanneken, A | 7,034 | 7,034 | ( https://open.umn.edu/opentextbooks ) , die | Open | Textbook Initiative ( https://aimath.org/textbooks/ ) | open |
| [20] - Stefanie Hanneken, A | 7,043 | 7,043 | https://aimath.org/textbooks/ ) und das UK | Open | Textbook Project ( http://ukopentextbooks.org/ ) | open |
| [21] - Claudia Frick (2020) | 48 | 48 | Aufmerksamkeit erhalten . Dieses spezielle | Open | Peer-Review-Verfahren wird analysiert , um | open |
| [21] - Claudia Frick (2020) | 104 | 104 | organisiert sein . Peer-Review , | Open | Peer-Review , Interne Wissenschaftskommunikation , | open |
| [21] - Claudia Frick (2020) | 112 | 112 | Interne Wissenschaftskommunikation , Preprint , | Open | Science The coronavirus pandemic in | open |
| [21] - Claudia Frick (2020) | 161 | 161 | of attention . This particular | open | peer review process is being | open |
| [21] - Claudia Frick (2020) | 226 | 226 | terms . Peer Review , | Open | Peer Review , Scholarly Communication | open |
| [21] - Claudia Frick (2020) | 235 | 235 | Scholarly Communication , Preprint , | Open | Science Veröffentlichung : 28.09.2020 in | open |
| [21] - Claudia Frick (2020) | 568 | 568 | dazugehörenden Gutachten , die als | Open | Peer-Reviews erschienen sind , eingegangen | open |
| [21] - Claudia Frick (2020) | 1,369 | 1,369 | , und 3 ) das | Open | Peer-Review-Verfahren ( Mittermaier , 2020 | open |
| [21] - Claudia Frick (2020) | 1,430 | 1,430 | Veröffentlichung der Peer-Reviews als sogenannte | Open | Peer-Reviews und das bereits angesprochene | open |
| [21] - Claudia Frick (2020) | 1,447 | 1,447 | , 2019 ) . Bei | Open | Peer-Review-Verfahren bei Verlagen wird in | open |
| [21] - Claudia Frick (2020) | 1,479 | 1,479 | , Verknüpfung und Veröffentlichung der | Open | Peer-Reviews sein . Als Beispiele | open |
| [21] - Claudia Frick (2020) | 1,519 | 1,519 | dezentrale Ansätze zur Bündelung von | Open | Peer-Reviews , wie zum Beispiel | open |
| [21] - Claudia Frick (2020) | 1,605 | 1,605 | haben . Dieses und dessen | Open | Peer-Reviews stehen im Fokus dieses | open |
| [21] - Claudia Frick (2020) | 1,697 | 1,697 | dieses zu lesen und einem | Open | Peer-Review zu unterziehen . Das | open |
| [21] - Claudia Frick (2020) | 1,730 | 1,730 | nicht bei einem Verlag mit | Open | Peer-Review-Verfahren vorveröffentlicht , noch erfolgte | open |
| [21] - Claudia Frick (2020) | 1,973 | 1,973 | veröffentlicht und zur Grundlage der | Open | Peer-Reviews wurde . P2 erschien | open |
| [21] - Claudia Frick (2020) | 2,013 | 2,013 | die überarbeitete Version aufgrund der | Open | Peer-Reviews , welche im Folgendem | open |
| [21] - Claudia Frick (2020) | 2,105 | 2,105 | des Auffindens der dazu verfassten | Open | Peer-Reviews . Diese verteilen sich | open |
| [21] - Claudia Frick (2020) | 2,149 | 2,149 | von Peer-Reviews , egal ob | Open | oder Closed , bereitgestellt wurde | open |
| [21] - Claudia Frick (2020) | 2,277 | 2,277 | Zitate . Zur Identifikation der | Open | Peer-Reviews wurde daher in dieser | open |
| [21] - Claudia Frick (2020) | 2,293 | 2,293 | : 1 ) Das bekannteste | Open | Peer-Review von McConway & Spiegelhalter | open |
| [21] - Claudia Frick (2020) | 2,308 | 2,308 | ) zitiert seinerseits vier weitere | Open | Peer-Reviews . 2 ) Drosten | open |
| [21] - Claudia Frick (2020) | 2,412 | 2,412 | Diese Liste aus insgesamt sechs | Open | Peer-Reviews zu P1 , und | open |
| [21] - Claudia Frick (2020) | 2,456 | 2,456 | Versionen des Preprints noch der | Open | Peer-Reviews , vorgenommen . Der | open |
| [21] - Claudia Frick (2020) | 2,487 | 2,487 | . Entsprechend sind die sechs | Open | Peer-Reviews mit einigen Rahmendaten aufgeführt | open |
| [21] - Claudia Frick (2020) | 2,538 | 2,538 | der ersten Veröffentlichung des jeweiligen | Open | Peer-Reviews dargestellt . Bei den | open |
| [21] - Claudia Frick (2020) | 2,618 | 2,618 | bis auf R1 , alle | Open | Peer-Reviews auf Preprint-Servern veröffentlicht , | open |
| [21] - Claudia Frick (2020) | 2,730 | 2,730 | P1 und dem Erscheinen der | Open | Peer-Reviews lässt sich am ehesten | open |
| [21] - Claudia Frick (2020) | 2,803 | 2,803 | ) . Die hier dargestellten | Open | Peer-Reviews wurden alle innerhalb von | open |
| [21] - Claudia Frick (2020) | 2,859 | 2,859 | und Verknüpfungen zwischen den verschiedenen | Open | Peer-Reviews machen . Dafür bedarf | open |
| [21] - Claudia Frick (2020) | 3,114 | 3,114 | der in Tabelle 2 gelisteten | Open | Peer-Reviews gab es weitere Kommentare | open |
| [21] - Claudia Frick (2020) | 3,225 | 3,225 | , benannten die hier vorgestellten | Open | Peer-Reviews zwar klar die Probleme | open |
| [21] - Claudia Frick (2020) | 3,316 | 3,316 | , dass es mindestens sechs | Open | Peer-Reviews und einen fundierten direkten | open |
| [21] - Claudia Frick (2020) | 3,337 | 3,337 | . Des Weiteren waren die | Open | Peer-Reviews nicht anonym und hatten | open |
| [21] - Claudia Frick (2020) | 3,367 | 3,367 | 8 Im Gegensatz zu verlagsgebundenen | Open | Peer-Reviews , waren die hier | open |
| [21] - Claudia Frick (2020) | 3,399 | 3,399 | die Frage stellen , wie | Open | ein Open Peer-Review ist , | open |
| [21] - Claudia Frick (2020) | 3,401 | 3,401 | stellen , wie Open ein | Open | Peer-Review ist , wenn er | open |
| [21] - Claudia Frick (2020) | 3,441 | 3,441 | Peer-Review nicht vorstellbar , bei | Open | Peer-Review durchaus . Das ist | open |
| [21] - Claudia Frick (2020) | 3,528 | 3,528 | Preprints und den Veröffentlichungen der | Open | Peer-Reviews sowie die Interaktion und | open |
| [21] - Claudia Frick (2020) | 3,549 | 3,549 | Ende dieses im Rampenlicht stattgefundenen | Open | Peer-Reviews steht das überarbeitete und | open |
| [21] - Claudia Frick (2020) | 3,601 | 3,601 | ohne koordinierende Stelle , abgelaufenen | Open | Peer-Review noch liefern wird . | open |
| [21] - Claudia Frick (2020) | 3,612 | 3,612 | Die Nachverfolgbarkeit des Verlaufs des | Open | Peer-Reviews , wie es in | open |
| [21] - Claudia Frick (2020) | 3,636 | 3,636 | nie und in nicht verlagsgebundenen | Open | Peer-Review-Verfahren eher selten gegeben . | open |
| [21] - Claudia Frick (2020) | 3,658 | 3,658 | . Die hohe Anzahl der | Open | Peer-Reviews und das mediale Echo | open |
| [21] - Claudia Frick (2020) | 3,668 | 3,668 | Echo machen das hier betrachtete | Open | Peer-Review-Verfahren zudem zu einem besonders | open |
| [21] - Claudia Frick (2020) | 3,685 | 3,685 | prominente Fallbeispiel bestätigt , dass | Open | Peer-Review-Verfahren zum einen funktionieren und | open |
| [21] - Claudia Frick (2020) | 3,720 | 3,720 | mit Vorveröffentlichungen und direkt veröffentlichten | Open | Peer-Reviews arbeiten können . Auf | open |
| [21] - Claudia Frick (2020) | 3,783 | 3,783 | 2020 ) während das eigentliche | Open | Peer-Review-Verfahren der Vorveröffentlichung nachgelagert wird | open |
| [21] - Claudia Frick (2020) | 3,799 | 3,799 | Vor- aber auch Nachteilen von | Open | Peer-Reviews , fanden sich in | open |
| [21] - Claudia Frick (2020) | 3,848 | 3,848 | Peers hat sich erweitert und | Open | Peer-Reviews wurden selbst wie Preprints | open |
| [21] - Claudia Frick (2020) | 4,036 | 4,036 | Problematik der schwierigen Auffindbarkeit der | Open | Peer-Reviews im Fallbeispiel aufgrund einer | open |
| [21] - Claudia Frick (2020) | 4,063 | 4,063 | fragen , wie offen ein | Open | Peer-Review-Prozess ist , bei dem | open |
| [21] - Claudia Frick (2020) | 4,164 | 4,164 | dafür ist eine neu entwickelte | Open | Peer-Review-Plattform für Preprints , die | open |
| [21] - Claudia Frick (2020) | 4,194 | 4,194 | zwischen Akteuren , Preprint und | Open | Peer-Reviews und die Versionierungen von | open |
| [21] - Claudia Frick (2020) | 4,202 | 4,202 | die Versionierungen von Preprint und | Open | Peer-Reviews weisen noch weiter , | open |
| [21] - Claudia Frick (2020) | 4,511 | 4,511 | oder vielleicht gerade weil das | Open | Peer-Review sich nicht an alte | open |
| [21] - Claudia Frick (2020) | 4,647 | 4,647 | the dangers of fast , | open | science . LSE Impact Blog | open |
| [21] - Claudia Frick (2020) | 4,693 | 4,693 | Henning ( 2020 ) . | Open | Science , aber richtig ! | open |
| [21] - Claudia Frick (2020) | 5,029 | 5,029 | Daniela ( 2020 ) . | Open | peer-review platform for COVID-19 preprints | open |
| [21] - Claudia Frick (2020) | 5,362 | 5,362 | 2020 , R3 ) . | Open | Review Report of Jones et | open |
| [21] - Claudia Frick (2020) | 5,611 | 5,611 | 2019 ) . What is | open | peer review ? A systematic | open |
| [21] - Claudia Frick (2020) | 6,525 | 6,525 | abhebt . Durchweg haben die | Open | Peer-Reviews jedoch einen Titel , | open |
| [21] - Claudia Frick (2020) | 6,558 | 6,558 | . ↩ Auch wenn die | Open | Peer-Reviews vermutlich nicht zur Begutachtung | open |
| [23] - Franziska Altemeier, | 108 | 108 | Technology ( TIB ) the | open | source research information system VIVO | open |
| [23] - Franziska Altemeier, | 2,515 | 2,515 | . Mit UMBIKO in Richtung | Open | Research Analytics . TIB Blog | open |
| [24] - Jana Hentschke, Sylv | 1,430 | 1,430 | und Übertragung mit der Software | Open | Broadcaster Software ( OBS ) | open |
| [24] - Jana Hentschke, Sylv | 2,254 | 2,254 | einen Experimentier-Slot mit Lightning-Talks und | Open | Space um auszuprobieren , ob | open |
| [24] - Jana Hentschke, Sylv | 2,586 | 2,586 | werden . Beim Programmteil “ | Open | Space ” wollten wir den | open |
| [24] - Jana Hentschke, Sylv | 2,906 | 2,906 | willigen TeilnehmerInnen am Ende des | Open | Space – was nebenbei auch | open |
| [25] - Jens Bemme (2020). # | 95 | 95 | Verbindung mit Wissenschaftskommunikation , digitaler | Open | Data- und Kommunikationsmethoden für den | open |
| [25] - Jens Bemme (2020). # | 108 | 108 | Landeskunde , Citizen Science , | Open | Data , Wikidata , Sachsen | open |
| [25] - Jens Bemme (2020). # | 199 | 199 | field of civil sciences with | open | data . Due to the | open |
| [25] - Jens Bemme (2020). # | 225 | 225 | with science communication , digital | open | data and communication methods for | open |
| [25] - Jens Bemme (2020). # | 238 | 238 | became clearer . saxony , | open | data , wikidata , wiksiource | open |
| [25] - Jens Bemme (2020). # | 544 | 544 | Landesgeschichte und offene Kulturdaten ( | Open | GLAM ) verstehen wir als | open |
| [25] - Jens Bemme (2020). # | 1,653 | 1,653 | zu experimentieren . Mit Linked | Open | Storytelling - Wikidata ( Q66631860 | open |
| [25] - Jens Bemme (2020). # | 2,426 | 2,426 | für derlei Hilfen ? Linked | Open | Storytelling als Aufgabe in der | open |
| [25] - Jens Bemme (2020). # | 2,557 | 2,557 | , um Grundlagen für Linked | Open | Data-Projekte zu schaffen : Vorteilhaft | open |
| [25] - Jens Bemme (2020). # | 3,033 | 3,033 | . Sie ließen sich linked | open | präsentieren und zugleich als Bildungsressource | open |
| [25] - Jens Bemme (2020). # | 3,111 | 3,111 | werden , die grundlegend über | Open | GLAM-Anwendungen i.V.m . Wikidata hinausgehen | open |
| [25] - Jens Bemme (2020). # | 3,179 | 3,179 | am 15 . Juni im | Open | Peer Review-Verfahren veröffentlicht , das | open |
| [25] - Jens Bemme (2020). # | 3,222 | 3,222 | und als Baustein für Linked | Open | Storytelling zusätzliche Gelegenheiten Publikationen gezielt | open |
| [25] - Jens Bemme (2020). # | 3,263 | 3,263 | , der i.S.v . Linked | Open | Data durch zusätzliche Bezüge kontextualisiert | open |
| [26] - Stefanie Spiegelberg | 85 | 85 | significant issues , effects and | open | questions in the realisation of | open |
| [27] - Sophie Schneider (20 | 4,426 | 4,426 | / oder informationswissenschaftlichem Fokus publizieren | Open | Access ( 027.7 o.J . | open |
| [27] - Sophie Schneider (20 | 4,719 | 4,719 | Am häufigsten waren die Themenbereiche | Open | Science , Bibliotheks- & Informationswissenschaft | open |
| [27] - Sophie Schneider (20 | 5,174 | 5,174 | D liegt der Schwerpunkt auf | Open | Science aber auch computer- und | open |
| [27] - Sophie Schneider (20 | 5,932 | 5,932 | und Informationswissenschaften waren die Bereiche | Open | Science sowie Bildung und Kommunikation | open |
| [27] - Sophie Schneider (20 | 5,973 | 5,973 | Zeitschriften auf Twitter publizieren primär | Open | Access . Neben den bibliotheks- | open |
| [27] - Sophie Schneider (20 | 6,218 | 6,218 | Forschenden auf Twitter darstellen – | Open | Science , Wissenschaftskommunikation und die | open |
| [27] - Sophie Schneider (20 | 6,913 | 6,913 | ) : Gephi : An | Open | Source Software for Exploring and | open |
| [28] - Heinz-Jürgen Bove, J | 1,779 | 1,779 | die Digitalisierung von Publikationsformen oder | Open | Access massiven Einfluss auf die | open |
| [28] - Heinz-Jürgen Bove, J | 4,867 | 4,867 | Owncloud-Instanz12 mit angeschlossenem Onlyoffice13 ( | Open | Source Office im Browser ) | open |
| [29] - Heinz-Jürgen Bove, J | 1,561 | 1,561 | Fraglos wäre zwar die dauerhafte | Open | Access-Verfügbarkeit der angesprochenen Inhalte einer | open |
| [29] - Heinz-Jürgen Bove, J | 1,743 | 1,743 | die Digitalisierung von Publikationsformen oder | Open | Access massiven Einfluss auf die | open |
| [29] - Heinz-Jürgen Bove, J | 4,832 | 4,832 | Owncloud-Instanz13 mit angeschlossenem Onlyoffice14 ( | Open | Source Office im Browser ) | open |
| [30] - Barbara Knorn, Erich | 261 | 261 | der lizenzierten Angebote . Die | Open | Access-Angebote ( Artikel und Monografien | open |
| [31] - Karsten Schuldt (202 | 192 | 192 | 20 years . Disaster , | Open | Access , Disaster Planning , | open |
| [33] - Christian Hauschke ( | 4,409 | 4,409 | data collection and analytical processes | open | and transparent , so that | open |
| [33] - Christian Hauschke ( | 6,513 | 6,513 | New York , London : | Open | University Press . Müller , | open |
| [33] - Christian Hauschke ( | 7,060 | 7,060 | responsible metrics and evaluation for | Open | Science . Report of the | open |
| [34] - Alessandro Blasetti, | 43 | 43 | für den grünen Weg des | Open | Access . Er adressiert Einrichtungen | open |
| [34] - Alessandro Blasetti, | 120 | 120 | herangezogen werden können . Schlüsselwörter | Open | Access , Grüner Weg , | open |
| [34] - Alessandro Blasetti, | 152 | 152 | in the field of Green | Open | Access . It addresses institutions | open |
| [34] - Alessandro Blasetti, | 242 | 242 | self-archiving service . Keywords Green | Open | Access , Self-archiving , Service | open |
| [34] - Alessandro Blasetti, | 567 | 567 | oder die Wissenschaftler * in | Open | Access ( OA ) gegenüber | open |
| [34] - Alessandro Blasetti, | 590 | 590 | Die Praxis zeigt , dass | Open | Access aufseiten der Forschung nicht | open |
| [34] - Alessandro Blasetti, | 627 | 627 | angesichts der zunehmenden Kommerzialisierung des | Open | Access äußerst bedauerlich ist ( | open |
| [34] - Alessandro Blasetti, | 684 | 684 | Preprints bereits eine Form von | Open | Access umgesetzt wird und dass | open |
| [34] - Alessandro Blasetti, | 931 | 931 | gegründet und bieten Schulungen zu | Open | Access und urheberrechtlichen Fragen an | open |
| [34] - Alessandro Blasetti, | 956 | 956 | und eine umfassende Aufklärungsarbeit zu | Open | Access ein immer wichtigeres Betätigungsfeld | open |
| [34] - Alessandro Blasetti, | 2,564 | 2,564 | Vor allem die Berücksichtigung von | Open | Access in Berufungsverfahren und in | open |
| [34] - Alessandro Blasetti, | 5,019 | 5,019 | Nationale Lizenzierung “ und „ | Open | Access “ der Schwerpunktinitiative „ | open |
| [34] - Alessandro Blasetti, | 5,228 | 5,228 | berechtigten Artikel zu identifizieren und | Open | Access zu stellen . Internationale | open |
| [34] - Alessandro Blasetti, | 9,302 | 9,302 | Nationale Lizenzierung “ und „ | Open | Access “ der Schwerpunktinitiative „ | open |
| [34] - Alessandro Blasetti, | 9,400 | 9,400 | and Researcher Caution in Achieving | Open | Access “ . Publications 6 | open |
| [34] - Alessandro Blasetti, | 9,531 | 9,531 | 2016 ) . How gold | open | access make things worse.Björn Brembs | open |
| [34] - Alessandro Blasetti, | 9,551 | 9,551 | ( 2017 ) . „ | Open | access outreach : SMASH vs | open |
| [34] - Alessandro Blasetti, | 9,595 | 9,595 | – What scientists think about | open | access “ . https://arxiv.org/abs/1101.5260. Galvan | open |
| [34] - Alessandro Blasetti, | 9,652 | 9,652 | Around Article Publication Costs For | Open | Access “ . Knowledge Exchange | open |
| [34] - Alessandro Blasetti, | 9,671 | 9,671 | ( 2018 ) . „ | Open | Access and Symbolic Gift Giving | open |
| [34] - Alessandro Blasetti, | 9,689 | 9,689 | ( Hrsg . ) : | Open | Divide ? Critical Studies on | open |
| [34] - Alessandro Blasetti, | 9,695 | 9,695 | Divide ? Critical Studies on | Open | Access , Litwin Books , | open |
| [34] - Alessandro Blasetti, | 9,810 | 9,810 | 2017 ) . „ Collecting | Open | Access information using OpenRefine and | open |
| [34] - Alessandro Blasetti, | 9,834 | 9,834 | ( 2018 ) . „ | Open | Access 2016-2017 EUA Survey Results | open |
| [34] - Alessandro Blasetti, | 9,964 | 9,964 | ( 2014 ) . „ | Open | and Shut ? : Interview | open |
| [34] - Alessandro Blasetti, | 9,980 | 9,980 | Director of the Confederation of | Open | Access Repositories “ . Open | open |
| [34] - Alessandro Blasetti, | 9,985 | 9,985 | Open Access Repositories “ . | Open | and Shut ? ( Blog | open |
| [34] - Alessandro Blasetti, | 10,108 | 10,108 | Input Faculty Works “ . | Open | Repositories 2018 Conference , 2018 | open |
| [34] - Alessandro Blasetti, | 10,133 | 10,133 | 2017 ) . „ Praxishandbuch | Open | Access ” . Berlin , | open |
| [34] - Alessandro Blasetti, | 10,219 | 10,219 | ( 2013 ) . „ | Open | Access – The true cost | open |
| [34] - Alessandro Blasetti, | 11,359 | 11,359 | nicht einschätzbar Werkzeug Vorteile Nachteile | Open | Access Button https://openaccessbutton.org/ großer Index | open |
| [34] - Alessandro Blasetti, | 11,682 | 11,682 | Nationale Lizenzierung “ und „ | Open | Access “ der Schwerpunktinitiative „ | open |
| [34] - Alessandro Blasetti, | 12,811 | 12,811 | Repositorienlandschaft bietet das Directory of | Open | Access Repositories ( OpenDOAR ) | open |
| [34] - Alessandro Blasetti, | 12,928 | 12,928 | die auf der Seite des | Open | Library Badge unter „ Open-Access-Potenziale | open |
| [35] - Fabian Steeg, Adrian | 97 | 97 | Web-APIs , JSON-LD , Linked | Open | Data , OpenRefine , lobid | open |
| [35] - Fabian Steeg, Adrian | 204 | 204 | APIs , JSON-LD , Linked | Open | Data , OpenRefine , lobid | open |
| [38] - Christian Erlinger ( | 60 | 60 | die Recherche und Speicherung von | Open | Access Artikeln über die REST-API | open |
| [38] - Christian Erlinger ( | 76 | 76 | Service ; Instant Messaging ; | Open | Access Abstract Instant Messenger are | open |
| [38] - Christian Erlinger ( | 144 | 144 | of openaccessbutton.org to search for | Open | Access Articles and deliver the | open |
| [38] - Christian Erlinger ( | 160 | 160 | Service ; Instant Messaging ; | Open | Access 1 Instant Messaging und | open |
| [38] - Christian Erlinger ( | 504 | 504 | oder durch Titel-String-Suche nach wissenschaftlichen | Open | Access Artikeln zu recherchieren und | open |
| [38] - Christian Erlinger ( | 677 | 677 | Engagement gerade im Bereich des | Open | Access Akzente setzen , eine | open |
| [38] - Christian Erlinger ( | 730 | 730 | von großem Nutzen sein . | Open | Access Button ist eine Plattform | open |
| [38] - Christian Erlinger ( | 739 | 739 | eine Plattform , die verschiedene | Open | Access Verzeichnisse oder Repositorien ( | open |
| [38] - Christian Erlinger ( | 788 | 788 | gesuchte Artikel nicht in einer | Open | Access Version verfügbar sind . | open |
| [38] - Christian Erlinger ( | 819 | 819 | Version des Artikels publizieren . | Open | Access Button bietet auch eine | open |
| [38] - Christian Erlinger ( | 952 | 952 | , wird eine Suche im | Open | Access Button Datensatz ausgelöst . | open |
| [38] - Christian Erlinger ( | 966 | 966 | Abb . 2 ) Bei | Open | Access Verfügbarkeit eines Artikels erscheint | open |
| [38] - Christian Erlinger ( | 1,023 | 1,023 | nicht mit einer der in | Open | Access Button verwendeten Ressourcen gefunden | open |
| [38] - Christian Erlinger ( | 1,047 | 1,047 | beinhaltet , um auf der | Open | Access Button Website einen bereits | open |
| [38] - Christian Erlinger ( | 1,160 | 1,160 | Der Quellcode des hier gezeigten | Open | Access Button Chatbots ist auf | open |
| [38] - Christian Erlinger ( | 1,189 | 1,189 | dafür entwickelte Telegram-API-Library8 . Die | Open | Access Button API9 wird über | open |
| [38] - Christian Erlinger ( | 1,198 | 1,198 | wird über die REST-Schnittstelle von | Open | Access Button genutzt , um | open |
| [38] - Christian Erlinger ( | 1,233 | 1,233 | könnte auch ein Abzug der | Open | Access Button Daten lokal genutzt | open |
| [38] - Christian Erlinger ( | 1,355 | 1,355 | . Je nach Antwort der | Open | Access Button REST-Schnittstelle wird eine | open |
| [38] - Christian Erlinger ( | 1,547 | 1,547 | beispielsweise Metadaten , die im | Open | Graph Format11 hinterlegt sind , | open |
| [38] - Christian Erlinger ( | 1,597 | 1,597 | . Für Publikationswebseiten wurden im | Open | Graph Protocol eigene Objekte für | open |
| [38] - Christian Erlinger ( | 1,835 | 1,835 | gezeigt , in Kombination mit | Open | Access Datenbeständen aufgebaut wird . | open |
| [39] - Gabriele Fahrenkrog, | 1,478 | 1,478 | für Lehrerinnen und Lehrer als | Open | Educational Resource ( OER ) | open |
| [40] - Christian Hauschke, | 434 | 434 | einem Vortrag über “ Linked | Open | Data for Scholarship : The | open |
| [40] - Christian Hauschke, | 1,274 | 1,274 | und weiterer Universitäten sowie Linked | Open | Data ( LOD ) der | open |
| [40] - Christian Hauschke, | 1,605 | 1,605 | die aktuellen VIVO-Entwicklungen aus dem | Open | Science Lab ( OSL ) | open |
| [40] - Christian Hauschke, | 2,631 | 2,631 | ( 2018 ) . Linked | Open | Data for Scholarship : The | open |
| [40] - Christian Hauschke, | 2,754 | 2,754 | 2018 ) . Nach außen | Open | Source , nach innen kommerziell | open |
| [41] - Joanna Einbock, Chri | 159 | 159 | . Forschungsinformationen , Forschungsinformationssystem , | Open | Source This article summarizes and | open |
| [41] - Joanna Einbock, Chri | 255 | 255 | article offers a comparison of | open | source systems with proprietary RIS | open |
| [41] - Joanna Einbock, Chri | 279 | 279 | experiences , and acceptance of | open | source solutions as an alternative | open |
| [41] - Joanna Einbock, Chri | 358 | 358 | 3.3 Wissenschaftlich tätige Ansprechpersonen 4 | Open | Source , Eigenentwicklung oder kommerzieller | open |
| [41] - Joanna Einbock, Chri | 369 | 369 | Dienst ? 5 Diskussion 5.1 | Open | Source 5.2 Infrastrukturelle Anforderungen 5.3 | open |
| [41] - Joanna Einbock, Chri | 3,759 | 3,759 | müssen die Begrifflichkeiten Eigenentwicklung und | Open | Source scharf getrennt werden . | open |
| [41] - Joanna Einbock, Chri | 3,795 | 3,795 | , also Free / Libre | Open | Source Software ( FLOSS ) | open |
| [41] - Joanna Einbock, Chri | 3,804 | 3,804 | FLOSS ) . Das Kriterium | Open | Source ist für einige Einrichtungen | open |
| [41] - Joanna Einbock, Chri | 3,890 | 3,890 | allerdings , dass die Begrifflichkeiten | Open | Source überwiegend mit Eigenentwicklungen gleichgesetzt | open |
| [42] - Adrian Pohl, Fabian | 39 | 39 | " steht für „ Linking | Open | Bibliographic Data “ . lobid | open |
| [42] - Adrian Pohl, Fabian | 151 | 151 | der Dienste . Schlüsselwörter Linked | Open | Data , JSON-LD , Web | open |
| [42] - Adrian Pohl, Fabian | 175 | 175 | central hub for the linked | open | data services provided by the | open |
| [42] - Adrian Pohl, Fabian | 195 | 195 | lobid stands for " linking | open | bibliographic data " . It | open |
| [42] - Adrian Pohl, Fabian | 334 | 334 | the services . Keywords Linked | Open | Data , JSON-LD , Web | open |
| [42] - Adrian Pohl, Fabian | 394 | 394 | Verfügung , die auf Linked | Open | Data ( LOD ) basieren | open |
| [42] - Adrian Pohl, Fabian | 538 | 538 | Auflösung des Akronyms " linking | open | bibliographic data " . Zunächst | open |
| [42] - Adrian Pohl, Fabian | 1,095 | 1,095 | und installiert werden . Linked | Open | Usable Data ( LOUD ) | open |
| [42] - Adrian Pohl, Fabian | 1,140 | 1,140 | für die Bereitstellung von Linked | Open | Usable Data ( LOUD ) | open |
| [42] - Adrian Pohl, Fabian | 1,422 | 1,422 | damit die Anforderungen an Linked | Open | Usable Data umfassender erfüllt werden | open |
| [42] - Adrian Pohl, Fabian | 3,070 | 3,070 | Entwicklung von lobid organisieren . | Open | Source Wir entwickeln die lobid-Dienste | open |
| [42] - Adrian Pohl, Fabian | 3,077 | 3,077 | Wir entwickeln die lobid-Dienste als | Open | Source Software auf GitHub . | open |
| [42] - Adrian Pohl, Fabian | 4,597 | 4,597 | und Entwicklungen im Bereich Linked | Open | Data und APIs bietet lobid | open |
| [42] - Adrian Pohl, Fabian | 4,924 | 4,924 | Adrian ( 2010 ) : | Open | Data im hbz-Verbund . In | open |
| [42] - Adrian Pohl, Fabian | 4,995 | 4,995 | Community Challenges For Practical Linked | Open | Data [ online ] . | open |
| [43] - Oliver Sievi, Andrea | 118 | 118 | , ihre Vokabulare als Linked | Open | Data zu veröffentlichen und welchen | open |
| [43] - Oliver Sievi, Andrea | 269 | 269 | publishing their vocabularies as Linked | Open | Data and their contribution to | open |
| [43] - Oliver Sievi, Andrea | 907 | 907 | nicht mit dem Thema Linked | Open | Data . Durch das gemeinsame | open |
| [43] - Oliver Sievi, Andrea | 1,300 | 1,300 | BARTOC-Team einen Server mit der | Open | Source Software “ Skosmos ” | open |
| [43] - Oliver Sievi, Andrea | 1,555 | 1,555 | aufzuschliessen ” und als Linked | Open | Data im Semantic Web nutzbar | open |
| [43] - Oliver Sievi, Andrea | 2,912 | 2,912 | https://help.poolparty.biz/doc/user-guide-for-knowledge-engineers/basic-features/import-exportand-reporting-with-poolparty/poolparty-excel-import-export-overview/the-poolparty-excel-format ↩ Auch mit der | Open | Source Software “ SKOS Play | open |
| [44] - Christian Hauschke, | 82 | 82 | Ontologie-Entwicklung In this article the | open | source software Vitro is described | open |
| [44] - Christian Hauschke, | 1,867 | 1,867 | von Objekten als Linked ( | Open | ) Data im Web gewährleisten | open |
| [46] - Karsten Schuldt, Rud | 363 | 363 | 6 ) with the still | open | question , what the objectives | open |
| [47] - Jakob Voß, Laura Bod | 437 | 437 | Inhalte von BARTOC stehen als | Open | Data in verschiedenen Formaten zur | open |
| [47] - Jakob Voß, Laura Bod | 937 | 937 | Zukunft aus dem Verzeichnis Linked | Open | Vocabularies ( LOV ) 5 | open |
| [47] - Jakob Voß, Laura Bod | 1,764 | 1,764 | knapp 600 Ontologien aus Linked | Open | Vocabularies im Mai 2017 . | open |
| [47] - Jakob Voß, Laura Bod | 2,693 | 2,693 | Term Bases And Linguistic Linked | Open | Data . Frederiksberg : Copenhagen | open |
| [48] - Nicole Eichenberger, | 3,706 | 3,706 | and the ease with which | Open | Data can be made available | open |
| [49] - Jana Mersmann, Chris | 1,713 | 1,713 | visualizations and reports , and | open | ways such as data publication | open |
| [50] - Christian Wilke, Reg | 12 | 12 | Christian WILKE Bericht zum Linked | Open | Citation Database Workshop an der | open |
| [50] - Christian Wilke, Reg | 27 | 27 | . November 2017 . Linked | Open | Data ; Zitation ; Semantic | open |
| [50] - Christian Wilke, Reg | 40 | 40 | Workshop Report on the Linked | Open | Citation Database Workshop at the | open |
| [50] - Christian Wilke, Reg | 54 | 54 | , November 7th 2017 linked | open | data ; citation ; semantic | open |
| [50] - Christian Wilke, Reg | 162 | 162 | stand im Mittelpunkt des Linked | Open | Citation Database Workshops am 07.11.2017 | open |
| [50] - Christian Wilke, Reg | 179 | 179 | der Halbzeit ihres DFG-Projekts Linked | Open | Citation Database ( LOC-DB ) | open |
| [50] - Christian Wilke, Reg | 270 | 270 | einer Datenbank und als Linked | Open | Data zur Verfügung gestellt . | open |
| [50] - Christian Wilke, Reg | 415 | 415 | ; dank der Initiative for | Open | Citations I4OC ( https://i4oc.org/ ) | open |
| [50] - Christian Wilke, Reg | 2,437 | 2,437 | April 2017 gestarteten Initiative for | Open | Citations ( I4OC ) , | open |
| [51] - Gabriele Fahrenkrog, | 34 | 34 | die Einhaltung der Prinzipien der | Open | Science : nachvollziehbare Resultate durch | open |
| [51] - Gabriele Fahrenkrog, | 48 | 48 | Forschungsdaten , transparente Qualitätssicherung durch | Open | Peer Review sowie frei zugängliche | open |
| [51] - Gabriele Fahrenkrog, | 58 | 58 | zugängliche Publikation im Sinne des | Open | Access . Die freie Veröffentlichung | open |
| [51] - Gabriele Fahrenkrog, | 254 | 254 | Bürgerwissenschaften “ greift auch die | Open | Collaboration auf , deren wohl | open |
| [51] - Gabriele Fahrenkrog, | 294 | 294 | Prinzip , das auch bei | Open | Educational Resources aufgegriffen wird , | open |
| [51] - Gabriele Fahrenkrog, | 465 | 465 | Systemanbietern . Die Implementierung von | Open | Standards führt zudem zu einem | open |
| [51] - Gabriele Fahrenkrog, | 482 | 482 | wiederum neue Synergien wie etwa | Open | Services ermöglicht . Darunter versteht | open |
| [51] - Gabriele Fahrenkrog, | 524 | 524 | Repositorien . Der Übergang zu | Open | Infrastructure , also der Bereitstellung | open |
| [51] - Gabriele Fahrenkrog, | 570 | 570 | Prinzipien einer offenen Wissenschaft verlangt | Open | Government die Nachvollziehbarkeit politischer Entscheidungen | open |
| [51] - Gabriele Fahrenkrog, | 615 | 615 | Informationsversorgung der Öffentlichkeit . Über | Open | Data Portale versuchen inzwischen zahlreiche | open |
| [51] - Gabriele Fahrenkrog, | 807 | 807 | der Gegenwart “ , der | Open | Access als Geschäftsmodell eines akademischen | open |
| [51] - Gabriele Fahrenkrog, | 842 | 842 | Dass auch große kommerzielle Verlage | Open | Access als Geschäftsmodell für sich | open |
| [51] - Gabriele Fahrenkrog, | 861 | 861 | , nicht als Argument gegen | Open | Access verwendet werden . Die | open |
| [51] - Gabriele Fahrenkrog, | 868 | 868 | verwendet werden . Die Frage | Open | Access als Utopie ? Beantworten | open |
| [51] - Gabriele Fahrenkrog, | 887 | 887 | und legen dar , dass | Open | Access und eine kommerzielle Verwertung | open |
| [51] - Gabriele Fahrenkrog, | 947 | 947 | Das Fazit zur Implementierung des | Open | Source-Produktes Koha lautet , dass | open |
| [51] - Gabriele Fahrenkrog, | 1,018 | 1,018 | wie durch gezielte Integration von | Open | Access-Publikationen und offenen kulturellen Inhalten | open |
| [51] - Gabriele Fahrenkrog, | 1,072 | 1,072 | die britische Regierung eine umstrittene | Open | Access-Strategie , die zentral gesteuerte | open |
| [51] - Gabriele Fahrenkrog, | 1,101 | 1,101 | ? “ - Top-down implementierter | Open | Access im britischen Hochschulsystem die | open |
| [51] - Gabriele Fahrenkrog, | 1,138 | 1,138 | beschäftigt sich mit dem Thema | Open | Data an Wissenschaftlichen Bibliotheken in | open |
| [51] - Gabriele Fahrenkrog, | 1,231 | 1,231 | ; Hürlimann , Daniel : | Open | Access als Utopie ? In | open |
| [51] - Gabriele Fahrenkrog, | 1,251 | 1,251 | https://dx.doi.org/10.11588/ip.2017.1.33687. Humbel , Marco : | Open | Data an Wissenschaftlichen Bibliotheken der | open |
| [51] - Gabriele Fahrenkrog, | 1,284 | 1,284 | & ldquo ? Top-down implementierter | Open | Access im britischen Hochschulsystem . | open |
| [52] - Eckhart Arnold, Stef | 941 | 941 | dass sie – zumindest bei | Open | Access Publikationen – unmittelbar verfügbar | open |
| [52] - Eckhart Arnold, Stef | 9,117 | 9,117 | report - Science as an | open | enterprise , hrsg . Von | open |
| [52] - Eckhart Arnold, Stef | 9,260 | 9,260 | . Wie die Uni Frankfurt | Open | Access beschädigt , Archivalia Blog | open |
| [54] - Christian Koller (20 | 17 | 17 | Strategie des forcierten Übergangs zu | Open | Access . Die auf der | open |
| [54] - Christian Koller (20 | 103 | 103 | managementgesteuerten britischen Hochschulsystem verstärkt . | Open | Access , Großbritannien , Hochschulpolitik | open |
| [54] - Christian Koller (20 | 130 | 130 | strategy of pushed transformation towards | Open | Access since 2011 . This | open |
| [54] - Christian Koller (20 | 164 | 164 | This article analyses the British | open | access strategy’s background and contexts | open |
| [54] - Christian Koller (20 | 218 | 218 | at management-driven British universities . | Open | Access , Great Britain , | open |
| [54] - Christian Koller (20 | 257 | 257 | auf die verschiedenen Stakeholder 5 | Open | Access und das Research Excellence | open |
| [54] - Christian Koller (20 | 307 | 307 | . Das unmissverständliche Bekenntnis zu | Open | Access des mit dem Spitznamen | open |
| [54] - Christian Koller (20 | 367 | 367 | forcierten und implementierten Wegs zu | Open | Access . Er verdeutlicht insbesondere | open |
| [54] - Christian Koller (20 | 917 | 917 | den Vorjahren intensiv diskutierte Thema | Open | Access mit keiner Silbe . | open |
| [54] - Christian Koller (20 | 1,059 | 1,059 | bleibt und also den analogen | Open | Access sogar Studierenden und Forschenden | open |
| [54] - Christian Koller (20 | 1,153 | 1,153 | ein gemeinsames Positionspapier zum Thema | Open | Access publizierten . Darin begrüßten | open |
| [54] - Christian Koller (20 | 1,177 | 1,177 | institutionellen Akteuren die Weiterentwicklung von | Open | Access an . 8 Eine | open |
| [54] - Christian Koller (20 | 1,281 | 1,281 | Politik des beschleunigten Übergangs zu | Open | Access aus und ließ klare | open |
| [54] - Christian Koller (20 | 1,389 | 1,389 | sie ein gemeinsames Statement zur | Open | Access Policy , das folgendes | open |
| [54] - Christian Koller (20 | 1,428 | 1,428 | of achieving this is through | Open | Access . The RCUK [ | open |
| [54] - Christian Koller (20 | 1,440 | 1,440 | Councils UK ] Policy on | Open | Access aims to achieve immediate | open |
| [54] - Christian Koller (20 | 1,520 | 1,520 | with the RCUK policy on | Open | Access . “ 12 Dies | open |
| [54] - Christian Koller (20 | 1,574 | 1,574 | either mandatory archiving , or | open | access publication “ macht . | open |
| [54] - Christian Koller (20 | 1,591 | 1,591 | den Research Councils finanzierten Forschungsergebnisse | Open | Access publiziert werden , wobei | open |
| [54] - Christian Koller (20 | 1,784 | 1,784 | Fällen , bei denen goldener | Open | Access vom Verlag grundsätzlich nicht | open |
| [54] - Christian Koller (20 | 1,919 | 1,919 | . 17 Anhänger des Grünen | Open | Access haben denn auch den | open |
| [54] - Christian Koller (20 | 1,983 | 1,983 | Auf der einen Seite entlastet | Open | Access die Budgets von den | open |
| [54] - Christian Koller (20 | 2,446 | 2,446 | Forschungsinstitutionen hat der top-down implementierte | Open | Access zu einer weiteren Zentralisierung | open |
| [54] - Christian Koller (20 | 3,119 | 3,119 | Was auf dem goldenen Weg | Open | Access publiziert werden darf , | open |
| [54] - Christian Koller (20 | 3,200 | 3,200 | deliver the RCUK Policy on | Open | Access in a transparent way | open |
| [54] - Christian Koller (20 | 3,696 | 3,696 | ) . 40 Sowohl der | Open | Access zu universitärer Bildung als | open |
| [54] - Christian Koller (20 | 3,721 | 3,721 | vom Recht der Steuerzahlenden auf | Open | Access zu wissenschaftlichen Forschungsergebnissen wird | open |
| [54] - Christian Koller (20 | 3,753 | 3,753 | goldenen Weg zur Verbreitung von | Open | Access darstellt . Nicht nur | open |
| [54] - Christian Koller (20 | 3,799 | 3,799 | . Der britische Weg zu | Open | Access wäre , würde er | open |
| [54] - Christian Koller (20 | 4,137 | 4,137 | Hochschullandschaft Gefahr , die hinter | Open | Access stehende Philosophie der freien | open |
| [54] - Christian Koller (20 | 4,172 | 4,172 | advocates have always argued that | open | access is inevitable and optimal | open |
| [54] - Christian Koller (20 | 4,190 | 4,190 | the issue is not whether | open | access will become a reality | open |
| [54] - Christian Koller (20 | 4,218 | 4,218 | how does one create an | open | culture ? Is it better | open |
| [54] - Christian Koller (20 | 4,238 | 4,238 | people in a debate about | open | access , telling them about | open |
| [54] - Christian Koller (20 | 4,409 | 4,409 | Eve , Martin Paul : | Open | Access and the Humanities : | open |
| [54] - Christian Koller (20 | 4,569 | 4,569 | , Paul : REF 2020 | open | access rules not ‘ scary | open |
| [54] - Christian Koller (20 | 4,650 | 4,650 | : Double Dipping beim Hybrid | Open | Access – Chimäre oder Realität | open |
| [54] - Christian Koller (20 | 4,673 | 4,673 | URL : http://dx.doi.org/10.11588/ip.2015.1.18274. Policy for | open | access in the post-2014 Research | open |
| [54] - Christian Koller (20 | 4,708 | 4,708 | . pdf . Oxford University | Open | Access Glossary . URL : | open |
| [54] - Christian Koller (20 | 4,719 | 4,719 | http://openaccess.ox.ac.uk/glossary. Poynder , Richard : | Open | Access and the Research Excellence | open |
| [54] - Christian Koller (20 | 4,767 | 4,767 | universities to aid drives to | open | access to research outputs ( | open |
| [54] - Christian Koller (20 | 4,782 | 4,782 | : http://www.rcuk.ac.uk/media/news/121108. RCUK Policy on | Open | Access ( April 2013 ) | open |
| [54] - Christian Koller (20 | 4,982 | 4,982 | Paul N . Edwards : | Open | Access : Publishing , Commerce | open |
| [54] - Christian Koller (20 | 5,191 | 5,191 | . ↩ RCUK Policy on | Open | Access ( April 2013 ) | open |
| [54] - Christian Koller (20 | 5,209 | 5,209 | ↩ The Leverhulme Trust : | Open | access publishing . URL : | open |
| [54] - Christian Koller (20 | 5,220 | 5,220 | https://www.leverhulme.ac.uk/funding/open-access-publishing. ↩ RCUK Policy on | Open | Access . ↩ Review of | open |
| [54] - Christian Koller (20 | 5,233 | 5,233 | of the RCUK Policy on | Open | Access ( März 2015 ) | open |
| [54] - Christian Koller (20 | 5,251 | 5,251 | http://www.rcuk.ac.uk/documents/documents/openaccessreport-pdf. ↩ RCUK Policy on | Open | Access . ↩ Review of | open |
| [54] - Christian Koller (20 | 5,264 | 5,264 | of the RCUK Policy on | Open | Access , S . 11-13 | open |
| [54] - Christian Koller (20 | 5,338 | 5,338 | universities to aid drives to | open | access to research outputs ( | open |
| [54] - Christian Koller (20 | 5,360 | 5,360 | of the RCUK Policy on | Open | Access , S . 7 | open |
| [54] - Christian Koller (20 | 5,399 | 5,399 | : Counting the Costs of | Open | Access ( November 2014 ) | open |
| [54] - Christian Koller (20 | 5,419 | 5,419 | of the RCUK Policy on | Open | Access , S . 17f | open |
| [54] - Christian Koller (20 | 5,440 | 5,440 | Meera und Paul Kirby : | Open | Access : HEFCE , REF2020 | open |
| [54] - Christian Koller (20 | 5,464 | 5,464 | ; Poynder , Richard : | Open | Access and the Research Excellence | open |
| [54] - Christian Koller (20 | 5,519 | 5,519 | http://blogs.lse.ac.uk/impactofsocialsciences/2017/02/09/the-importance-of-being-ref-able-academic-writing-under-pressure-from-a-culture-of-counting/ . ↩ Policy for | open | access in the post-2014 Research | open |
| [54] - Christian Koller (20 | 5,556 | 5,556 | . ↩ RCUK Policy on | Open | Access . ↩ Hagner , | open |
| [54] - Christian Koller (20 | 5,579 | 5,579 | Eve , Martin Paul : | Open | Access and the Humanities : | open |
| [54] - Christian Koller (20 | 5,606 | 5,606 | Konstanze : Why not ? | Open | Access in den Geisteswissenschaften , | open |
| [54] - Christian Koller (20 | 5,663 | 5,663 | , Paul : REF 2020 | open | access rules not ‘ scary | open |
| [54] - Christian Koller (20 | 5,736 | 5,736 | : Double Dipping beim Hybrid | Open | Access – Chimäre oder Realität | open |
| [54] - Christian Koller (20 | 5,760 | 5,760 | : http://dx.doi.org/10.11588/ip.2015.1.18274. ↩ Oxford University | Open | Access Glossary . URL : | open |
| [54] - Christian Koller (20 | 5,781 | 5,781 | Osborne on the state of | Open | Access : Where are we | open |
| [54] - Christian Koller (20 | 5,892 | 5,892 | ↩ Poynder , Richard : | Open | Access and the Research Excellence | open |
| [55] - Marco Humbel (2017). | 13 | 13 | Marco HUMBEL Unter dem Stichwort | Open | Data wird unter anderem die | open |
| [55] - Marco Humbel (2017). | 43 | 43 | nächsten Jahren vermehrt Konzepte von | Open | Data umsetzen werden . Im | open |
| [55] - Marco Humbel (2017). | 63 | 63 | Frage wie die Umsetzung von | Open | Data und im speziellen von | open |
| [55] - Marco Humbel (2017). | 69 | 69 | Data und im speziellen von | Open | Content in Wissenschaftlichen Bibliotheken der | open |
| [55] - Marco Humbel (2017). | 111 | 111 | Untersuchung Amongst others the term | Open | Data refers to the appropriation | open |
| [55] - Marco Humbel (2017). | 121 | 121 | appropriation of digitized content under | open | licences . National and international | open |
| [55] - Marco Humbel (2017). | 138 | 138 | will adopt increased concepts of | Open | Data . In context of | open |
| [55] - Marco Humbel (2017). | 155 | 155 | investigated how the implementation of | Open | Data and particularly Open Content | open |
| [55] - Marco Humbel (2017). | 159 | 159 | of Open Data and particularly | Open | Content looks like in Swiss | open |
| [55] - Marco Humbel (2017). | 202 | 202 | Qualitative Research 1 Einleitung 2 | Open | Data , Open Content und | open |
| [55] - Marco Humbel (2017). | 205 | 205 | Einleitung 2 Open Data , | Open | Content und das Urheberrecht 2.1 | open |
| [55] - Marco Humbel (2017). | 211 | 211 | Content und das Urheberrecht 2.1 | Open | Data und Open Content 2.2 | open |
| [55] - Marco Humbel (2017). | 214 | 214 | Urheberrecht 2.1 Open Data und | Open | Content 2.2 Das Urheberrecht und | open |
| [55] - Marco Humbel (2017). | 260 | 260 | Handlungsempfehlung für die Umsetzung von | Open | Data 7.1 Grundsätzliche Voraussetzungen zur | open |
| [55] - Marco Humbel (2017). | 268 | 268 | Grundsätzliche Voraussetzungen zur Umsetzung von | Open | Data 7.2 Mit kleinen Schritten | open |
| [55] - Marco Humbel (2017). | 448 | 448 | Bereich der digitalisierten Überlieferungsobjekte bietet | Open | Data die Chance mit anderen | open |
| [55] - Marco Humbel (2017). | 463 | 463 | die Benutzer stärker einzubinden ( | Open | Knowledge 2016 ) . Der | open |
| [55] - Marco Humbel (2017). | 485 | 485 | Wissenschaftliche Bibliotheken sich vermehrt der | Open | Philosophie anschliessen , um einen | open |
| [55] - Marco Humbel (2017). | 521 | 521 | vertritt die Meinung , dass | Open | Data für die Bibliotheken heutzutage | open |
| [55] - Marco Humbel (2017). | 560 | 560 | Kulturgütern verfügen über Elemente von | Open | Data . Für eine konsequente | open |
| [55] - Marco Humbel (2017). | 580 | 580 | wurde bereits der Stand von | Open | Data in Gedächtnisinstitutionen Europas und | open |
| [55] - Marco Humbel (2017). | 671 | 671 | Wie sieht die Umsetzung von | Open | Data in Wissenschaftlichen Bibliotheken der | open |
| [55] - Marco Humbel (2017). | 683 | 683 | aus ? Der Ruf nach | Open | Access im Sinne des freien | open |
| [55] - Marco Humbel (2017). | 710 | 710 | auch mit der Forderung von | Open | Research , Open Data und | open |
| [55] - Marco Humbel (2017). | 713 | 713 | Forderung von Open Research , | Open | Data und Open Science einher | open |
| [55] - Marco Humbel (2017). | 716 | 716 | Research , Open Data und | Open | Science einher . In diesem | open |
| [55] - Marco Humbel (2017). | 735 | 735 | , in diesem Zusammenhang auch | Open | Content genannt . Open Content | open |
| [55] - Marco Humbel (2017). | 739 | 739 | auch Open Content genannt . | Open | Content wird hier als Teilaspekt | open |
| [55] - Marco Humbel (2017). | 746 | 746 | wird hier als Teilaspekt der | Open | Philosophie und Open Data gesehen | open |
| [55] - Marco Humbel (2017). | 749 | 749 | Teilaspekt der Open Philosophie und | Open | Data gesehen . Ziel des | open |
| [55] - Marco Humbel (2017). | 763 | 763 | , die aktuelle Umsetzung von | Open | Data in Wissenschaftlichen Bibliotheken der | open |
| [55] - Marco Humbel (2017). | 799 | 799 | Einführung beschreibt das Konzept von | Open | Data und gibt einen Überblick | open |
| [55] - Marco Humbel (2017). | 835 | 835 | ) bietet die OKF ( | Open | Knowledge Foundation ) eine weithin | open |
| [55] - Marco Humbel (2017). | 853 | 853 | Inhalte und Daten . Die | Open | Definition präzisiert Open in den | open |
| [55] - Marco Humbel (2017). | 856 | 856 | . Die Open Definition präzisiert | Open | in den Begriffen Open Data | open |
| [55] - Marco Humbel (2017). | 860 | 860 | präzisiert Open in den Begriffen | Open | Data und Open Content zusammengefasst | open |
| [55] - Marco Humbel (2017). | 863 | 863 | den Begriffen Open Data und | Open | Content zusammengefasst wie folgt : | open |
| [55] - Marco Humbel (2017). | 870 | 870 | zusammengefasst wie folgt : “ | Open | means anyone can freely access | open |
| [55] - Marco Humbel (2017). | 902 | 902 | and openness ) ” ( | Open | Knowledge Open Definition Group 2016 | open |
| [55] - Marco Humbel (2017). | 904 | 904 | ) ” ( Open Knowledge | Open | Definition Group 2016 ) . | open |
| [55] - Marco Humbel (2017). | 916 | 916 | Matzat ( 2011 ) bezeichnet | Open | Data eine Kultur oder ein | open |
| [55] - Marco Humbel (2017). | 956 | 956 | , abrufbare Information gemeint . | Open | Data kann von der Wirtschaft | open |
| [55] - Marco Humbel (2017). | 976 | 976 | . Häufig wird der Begriff | Open | Data synonym für Open Government | open |
| [55] - Marco Humbel (2017). | 980 | 980 | Begriff Open Data synonym für | Open | Government Data verwendet , welches | open |
| [55] - Marco Humbel (2017). | 994 | 994 | der öffentlichen Verwaltung meint . | Open | Content bezeichnet Werke , welche | open |
| [55] - Marco Humbel (2017). | 1,033 | 1,033 | dem oben erläuterten Verständnis von | Open | ( Die Inhalte frei kopieren | open |
| [55] - Marco Humbel (2017). | 1,149 | 1,149 | die Nutzer im Bereich von | Open | Data ist es wichtig , | open |
| [55] - Marco Humbel (2017). | 1,223 | 1,223 | für offene Lizenzen gemäss der | Open | Definition wie folgt zusammen : | open |
| [55] - Marco Humbel (2017). | 1,289 | 1,289 | der Bachelor-Thesis wird ebenfalls die | Open | Definition als Maßstab genommen . | open |
| [55] - Marco Humbel (2017). | 1,621 | 1,621 | vor allem im Sinne von | Open | Content ) konsumieren , sondern | open |
| [55] - Marco Humbel (2017). | 1,636 | 1,636 | beizutragen und zu teilen ( | Open | Knowledge 2016 ) . Gemäss | open |
| [55] - Marco Humbel (2017). | 1,656 | 1,656 | sich OpenGLAM als Pendant zu | Open | Government im Bereich der Gedächtnisinstitutionen | open |
| [55] - Marco Humbel (2017). | 1,676 | 1,676 | den dazugehörigen Prinzipien wird unter | Open | die unter Kapitel 2 genannte | open |
| [55] - Marco Humbel (2017). | 1,720 | 1,720 | Artikels ( vgl . : | Open | Knowledge ( 2016 ) : | open |
| [55] - Marco Humbel (2017). | 1,902 | 1,902 | ebenfalls Prinzipien in Bezug auf | Open | Data . Da diese sich | open |
| [55] - Marco Humbel (2017). | 1,971 | 1,971 | , dass diese Bestände als | Open | Content auf Online Plattformen bereitstellen | open |
| [55] - Marco Humbel (2017). | 1,987 | 1,987 | einer Form auch mit der | Open | Philosophie beschäftigt haben . Die | open |
| [55] - Marco Humbel (2017). | 2,192 | 2,192 | Anforderungen aus den OpenGLAM-Prinzipien ( | Open | Knowledge 2016 ) . Die | open |
| [55] - Marco Humbel (2017). | 2,412 | 2,412 | Art bezüglich der Umsetzung von | Open | Data in Gedächtnisinstitutionen besprechen zu | open |
| [55] - Marco Humbel (2017). | 2,435 | 2,435 | OpenGLAM Pilot Survey und des | Open | Benchmark Survey zusammen und diskutierte | open |
| [55] - Marco Humbel (2017). | 2,701 | 2,701 | Survey 70 % ) . | Open | Content verbreitet sich auf jeden | open |
| [55] - Marco Humbel (2017). | 2,725 | 2,725 | einer Adaptionsrate in Bezug auf | Open | Content von 31 % , | open |
| [55] - Marco Humbel (2017). | 2,757 | 2,757 | In den genannten Ländern wird | Open | Content von Museen , mit | open |
| [55] - Marco Humbel (2017). | 2,807 | 2,807 | 5 % ihrer Bestände als | Open | Content bereitstellen werden ( Estermann | open |
| [55] - Marco Humbel (2017). | 2,831 | 2,831 | wahrscheinlich 70 % der Institutionen | Open | Content anwenden ( Estermann 2015 | open |
| [55] - Marco Humbel (2017). | 2,886 | 2,886 | wie auf den einzelnen Plattformen | Open | Data umgesetzt wird . Im | open |
| [55] - Marco Humbel (2017). | 2,972 | 2,972 | es unter Punkt 9 : | Open | Access : Digitalisate und Metadaten | open |
| [55] - Marco Humbel (2017). | 3,376 | 3,376 | auf allen Plattformen mit den | Open | Prinzipien übereinstimmen , so sind | open |
| [55] - Marco Humbel (2017). | 3,404 | 3,404 | . Mit dem Konzept von | Open | Data assoziieren die Interviewteilnehmer klar | open |
| [55] - Marco Humbel (2017). | 3,461 | 3,461 | hatten sich alle Institutionen mit | Open | Data beschäftigt und auch in | open |
| [55] - Marco Humbel (2017). | 3,485 | 3,485 | erste Schritte im Bereich von | Open | Data keine konkrete Strategie zwingend | open |
| [55] - Marco Humbel (2017). | 3,541 | 3,541 | . Der Mehrwert , den | Open | Data bietet , liegt in | open |
| [55] - Marco Humbel (2017). | 3,586 | 3,586 | Ergebnissen aus den Studien . | Open | Data ist ein Thema in | open |
| [55] - Marco Humbel (2017). | 3,663 | 3,663 | befragen Institutionen bereits Erfahrungen mit | Open | Data gesammelt haben . Dieser | open |
| [55] - Marco Humbel (2017). | 3,682 | 3,682 | , da Organisationen , welche | Open | Data für unwichtig hielten , | open |
| [55] - Marco Humbel (2017). | 3,735 | 3,735 | der Nutzung gestaltet sich bei | Open | Data schwierig . Auch sieht | open |
| [55] - Marco Humbel (2017). | 3,806 | 3,806 | oder mit Vereinen aus dem | Open | Bereich gepflegt . Auch gehörte | open |
| [55] - Marco Humbel (2017). | 3,821 | 3,821 | und das Engagement in der | Open | Data Community für fast alle | open |
| [55] - Marco Humbel (2017). | 3,831 | 3,831 | alle Experten ebenfalls zu einer | Open | Data Strategie . An Open | open |
| [55] - Marco Humbel (2017). | 3,836 | 3,836 | Open Data Strategie . An | Open | Data wird weitergearbeitet und die | open |
| [55] - Marco Humbel (2017). | 3,850 | 3,850 | Erste Schritte in Richtung Linked | Open | Data sind zu erkennen . | open |
| [55] - Marco Humbel (2017). | 3,856 | 3,856 | Data sind zu erkennen . | Open | Data wird die Wissenschaftlichen Bibliotheken | open |
| [55] - Marco Humbel (2017). | 3,897 | 3,897 | zur Verfügung stehen . Mit | Open | Data steht den Bibliotheken eine | open |
| [55] - Marco Humbel (2017). | 3,976 | 3,976 | , ob die Versprechen von | Open | Data auch eingehalten werden können | open |
| [55] - Marco Humbel (2017). | 3,989 | 3,989 | handelt es sich also bei | Open | Data um einen Trend oder | open |
| [55] - Marco Humbel (2017). | 4,093 | 4,093 | eine Handlungsempfehlung zur Umsetzung von | Open | Data in Wissenschaftlichen Bibliotheken . | open |
| [55] - Marco Humbel (2017). | 4,128 | 4,128 | , damit eine Institution eine | Open | Data Strategie umsetzen kann wie | open |
| [55] - Marco Humbel (2017). | 4,147 | 4,147 | Abbildung ihrer Überlieferungsobjekte eine konsequente | Open | Data Strategie verfolgen kann , | open |
| [55] - Marco Humbel (2017). | 4,227 | 4,227 | “ In Bezug auf eine | Open | Data Strategie ist in diesem | open |
| [55] - Marco Humbel (2017). | 4,255 | 4,255 | Digitalisierung der Bestände auch zu | Open | Data . Die Aktivitäten in | open |
| [55] - Marco Humbel (2017). | 4,321 | 4,321 | . Um erste Erfahrungen mit | Open | Data sammeln zu können , | open |
| [55] - Marco Humbel (2017). | 4,413 | 4,413 | . Eine konsequente Umsetzung von | Open | Data geht mit der potentiellen | open |
| [55] - Marco Humbel (2017). | 4,497 | 4,497 | erste Erfahrungen im Bereich von | Open | Data zu sammeln , eignet | open |
| [55] - Marco Humbel (2017). | 4,559 | 4,559 | sollte bei einer Weiterführung von | Open | Data mit anderen Institutionen und | open |
| [55] - Marco Humbel (2017). | 4,607 | 4,607 | , lassen sich Beziehungen zur | Open | Data Community aufbauen . Der | open |
| [55] - Marco Humbel (2017). | 4,659 | 4,659 | zu einer konsequenten Umsetzung von | Open | Data . Wie in den | open |
| [55] - Marco Humbel (2017). | 4,680 | 4,680 | OGD-Strategie bereits strategische Konzepte zu | Open | Data auf gesamtschweizerischen Ebene , | open |
| [55] - Marco Humbel (2017). | 4,725 | 4,725 | sich dabei , wie bei | Open | Government Data für die Schweiz | open |
| [55] - Marco Humbel (2017). | 4,942 | 4,942 | einer Pilotbefragung zu den Themenbereichen | Open | Data und Crowdsourcing . [ | open |
| [55] - Marco Humbel (2017). | 4,972 | 4,972 | 2015 ) : Diffusion of | Open | Data and Crowdsourcing among Heritage | open |
| [55] - Marco Humbel (2017). | 5,070 | 5,070 | : Measuring the Advancement of | Open | Data / Open Content in | open |
| [55] - Marco Humbel (2017). | 5,073 | 5,073 | Advancement of Open Data / | Open | Content in the Heritage Sector | open |
| [55] - Marco Humbel (2017). | 5,166 | 5,166 | Cécile ( 2011 ) : | Open | Government Data für die Schweiz | open |
| [55] - Marco Humbel (2017). | 5,325 | 5,325 | : Ein Glossar rund um | Open | Data . [ online ] | open |
| [55] - Marco Humbel (2017). | 5,424 | 5,424 | . Verfügbar unter : http://pro.europeana.eu/files/Europeana_Professional/Projects/Project_list/ENUMERATE/presentations/enumerate-report-core-survey-3-2015.pdf. | Open | Knowledge ( 2016 ) : | open |
| [55] - Marco Humbel (2017). | 5,448 | 5,448 | 2016 Verfügbar unter : http://openglam.org/principles/. | Open | Knowledge Open Definition Group ( | open |
| [55] - Marco Humbel (2017). | 5,450 | 5,450 | unter : http://openglam.org/principles/. Open Knowledge | Open | Definition Group ( 2016 ) | open |
| [55] - Marco Humbel (2017). | 5,458 | 5,458 | ( 2016 ) : The | Open | Definition . [ online ] | open |
| [55] - Marco Humbel (2017). | 5,489 | 5,489 | ( 2013 ) : Linked | Open | Data in der Bibliothekswelt : | open |
| [55] - Marco Humbel (2017). | 5,511 | 5,511 | , Hg . : ( | Open | ) linked data in Bibliotheken | open |
| [55] - Marco Humbel (2017). | 5,753 | 5,753 | the Making and Using of | Open | Digitised Cultural Content . Information | open |
| [55] - Marco Humbel (2017). | 6,052 | 6,052 | ETH-Bibliothek ( 2016 ) : | Open | Data jetzt auch bei gedruckten | open |
| [56] - Tabea Lurk, Jürgen E | 22 | 22 | der Gegenwartskunst mit Fragen zum | Open | Access ( OA ) aus | open |
| [56] - Tabea Lurk, Jürgen E | 102 | 102 | von Informationskompetenz geeignet sind . | Open | Access , Digital Curation , | open |
| [56] - Tabea Lurk, Jürgen E | 125 | 125 | in contemporary art together with | open | access ( OA ) questions | open |
| [56] - Tabea Lurk, Jürgen E | 166 | 166 | providing both : OA-publications and | open | cultural content . Benefits from | open |
| [56] - Tabea Lurk, Jürgen E | 175 | 175 | Benefits from the implementation of | Open | Science Content are mentioned and | open |
| [56] - Tabea Lurk, Jürgen E | 208 | 208 | for enabling information competence . | Open | Access , Digital Curation , | open |
| [56] - Tabea Lurk, Jürgen E | 252 | 252 | Quellen AutorInnen Die Debatte um | Open | Access in Gestaltung und Kunst | open |
| [56] - Tabea Lurk, Jürgen E | 1,167 | 1,167 | DOAJ , DOAJ-Articles , Springer | Open | , Degruyter Open ) , | open |
| [56] - Tabea Lurk, Jürgen E | 1,170 | 1,170 | , Springer Open , Degruyter | Open | ) , die Nationallizenten und | open |
| [56] - Tabea Lurk, Jürgen E | 3,798 | 3,798 | 2017 ) : Directory of | Open | Access Books [ online ] | open |
| [56] - Tabea Lurk, Jürgen E | 3,825 | 3,825 | 2017 ) : Directory of | Open | Access Journals [ online ] | open |
| [56] - Tabea Lurk, Jürgen E | 3,931 | 3,931 | Gudrun ( 2007 ) : | Open | Access in den Geisteswissenschaften . | open |
| [56] - Tabea Lurk, Jürgen E | 3,939 | 3,939 | den Geisteswissenschaften . In : | Open | Access Chancen und Herausforderungen . | open |
| [56] - Tabea Lurk, Jürgen E | 4,082 | 4,082 | 2012 ) : Harvard Library | Open | Metadata [ online ] . | open |
| [56] - Tabea Lurk, Jürgen E | 4,285 | 4,285 | Asura ( 2016 ) : | Open | Knowledge Maps . Creating a | open |
| [56] - Tabea Lurk, Jürgen E | 4,627 | 4,627 | Book ? An Introduction to | Open | Access in the Arts . | open |
| [57] - Christian Kaier (201 | 776 | 776 | , Recherche , Bibliometrie , | Open | Access und Datenmanagement , um | open |
| [57] - Christian Kaier (201 | 2,171 | 2,171 | , die eigenen Publikationen in | Open | Access zur Verfügung zu stellen | open |
| [57] - Christian Kaier (201 | 2,287 | 2,287 | fundamental , digitales Publizieren und | Open | Access werden in höchst unterschiedlichem | open |
| [57] - Christian Kaier (201 | 2,539 | 2,539 | Anforderungen etwa in den Bereichen | Open | Access und Forschungsdatenmanagement betroffen . | open |
| [57] - Christian Kaier (201 | 3,876 | 3,876 | Universitätsbibliothek Graz in den Bereichen | Open | Access und Publikationsservices tätig und | open |
| [57] - Christian Kaier (201 | 4,015 | 4,015 | Ein Beispiel dafür ist das | Open | Access Netzwerk Austria ( OANA | open |
| [57] - Christian Kaier (201 | 4,046 | 4,046 | Empfehlungen für die Umsetzung von | Open | Access in Österreich “ , | open |
| [58] - Márton Villányi (201 | 70 | 70 | Implementierung zurückblicken . Bibliothekssystem , | Open | Source , Koha , Wissenschaftliche | open |
| [58] - Márton Villányi (201 | 148 | 148 | implementation . Library System , | Open | Source , Koha , Scientific | open |
| [58] - Márton Villányi (201 | 250 | 250 | entwickelt und von einer enthusiastischen | Open | Source Community in die Welt | open |
| [58] - Márton Villányi (201 | 2,662 | 2,662 | Coral . Coral ist ein | Open | Source ERM-System ( Electonic Resource | open |
| [58] - Márton Villányi (201 | 2,711 | 2,711 | . Die Entscheidung für ein | Open | Source Bibliothekssystems war nicht selbstverständlich | open |
| [58] - Márton Villányi (201 | 2,969 | 2,969 | Villányi , Márton 2015 : | Open | Source Bibliothekssysteme als Alternative ? | open |
| [58] - Márton Villányi (201 | 3,001 | 3,001 | Meißner , Holger 2015 : | Open | Source All Inclusive - Betriebs- | open |
| [59] - Daniel Hürlimann, Al | 9 | 9 | Daniel HÜRLIMANN , Alexander GROSSMANN | Open | Access ( OA ) wurde | open |
| [59] - Daniel Hürlimann, Al | 157 | 157 | erschienenen Publikation versucht hat . | Open | Access , Verlage , Wissenschaftliches | open |
| [59] - Daniel Hürlimann, Al | 165 | 165 | Verlage , Wissenschaftliches Publizieren , | Open | Science Open Access ( OA | open |
| [59] - Daniel Hürlimann, Al | 167 | 167 | Wissenschaftliches Publizieren , Open Science | Open | Access ( OA ) has | open |
| [59] - Daniel Hürlimann, Al | 323 | 323 | in a recent publication . | Open | Access , Publishers , Academic | open |
| [59] - Daniel Hürlimann, Al | 331 | 331 | Publishers , Academic Publishing , | Open | Science Michael Hagner kritisiert in | open |
| [59] - Daniel Hürlimann, Al | 348 | 348 | Kapitalismus die Wissenschaften verändert ” | Open | Access mit Verweis auf negative | open |
| [59] - Daniel Hürlimann, Al | 361 | 361 | Bestrebungen von Verlagen , aus | Open | Access ein Geschäft zu machen1 | open |
| [59] - Daniel Hürlimann, Al | 371 | 371 | machen1 . Selbstverständlich hat auch | Open | Access , wie alles , | open |
| [59] - Daniel Hürlimann, Al | 405 | 405 | einseitig und kaum wissenschaftlich . | Open | Access ist in vielen Disziplinen | open |
| [59] - Daniel Hürlimann, Al | 428 | 428 | akademischen Kapitalismus ” . Während | Open | Access in den Natur- und | open |
| [59] - Daniel Hürlimann, Al | 517 | 517 | kein Widerspruch zum Engagement für | Open | Access . Ein wissenschaftliches Werk | open |
| [59] - Daniel Hürlimann, Al | 610 | 610 | Büchern zusätzlich zur gedrucken Version | Open | Access erscheint und welches nicht | open |
| [59] - Daniel Hürlimann, Al | 698 | 698 | heute systematisch jeglicher Annäherung an | Open | Access widersetzen . Einige von | open |
| [59] - Daniel Hürlimann, Al | 832 | 832 | Begriff überhaupt gab , war | Open | Access also gewissermassen der Standard | open |
| [59] - Daniel Hürlimann, Al | 923 | 923 | gewissen Disziplinen die Idee des | Open | Access erst jetzt durchzusetzen beginnt | open |
| [59] - Daniel Hürlimann, Al | 952 | 952 | Ein Beispiel für die durch | Open | Access befruchtete Förderung von Wissen | open |
| [59] - Daniel Hürlimann, Al | 982 | 982 | für jedermann , also als | Open | Access publiziert , hätten wir | open |
| [59] - Daniel Hürlimann, Al | 1,237 | 1,237 | von den Autoren , die | Open | Access publizieren . Bernhard Mittermaier | open |
| [59] - Daniel Hürlimann, Al | 1,296 | 1,296 | Eine der erfolgreichsten , ausschliesslich | Open | Access publizierenden Online-Fachzeitschriften ist PLOS | open |
| [59] - Daniel Hürlimann, Al | 1,411 | 1,411 | auf der Hand , dass | Open | Access ein wichtiger Schritt ist | open |
| [59] - Daniel Hürlimann, Al | 1,438 | 1,438 | Als Beispiele seien hier das | Open | Peer Review oder Post-Publication Peer | open |
| [59] - Daniel Hürlimann, Al | 1,519 | 1,519 | ist , bestehende Zeitschriften auf | Open | Access umzustellen . Die Gründe | open |
| [59] - Daniel Hürlimann, Al | 1,548 | 1,548 | Karrieren in einer Welt ohne | Open | Access durchlaufen haben . Dabei | open |
| [59] - Daniel Hürlimann, Al | 1,613 | 1,613 | von bisher kostenpflichtigen Zeitschriften auf | Open | Access14 . Tatsächlich gibt es | open |
| [59] - Daniel Hürlimann, Al | 1,668 | 1,668 | Problem und hat nichts mit | Open | Access zu tun . Gerade | open |
| [59] - Daniel Hürlimann, Al | 1,782 | 1,782 | gibt , die auch aus | Open | Access ein Geschäft machen wollen | open |
| [59] - Daniel Hürlimann, Al | 1,825 | 1,825 | den eingeschlagenen Weg in Richtung | Open | Access weitergehen und sich nicht | open |
| [59] - Daniel Hürlimann, Al | 1,949 | 1,949 | in der Statistik des Zurich | Open | Repository and Archive : Ökonomie | open |
| [59] - Daniel Hürlimann, Al | 2,011 | 2,011 | zur Einführung in die Tagung | Open | Access in den Rechtswissenschaften , | open |
| [59] - Daniel Hürlimann, Al | 2,066 | 2,066 | 20 . März 2014 : | Open | Access . Eine Bedrohung für | open |
| [59] - Daniel Hürlimann, Al | 2,088 | 2,088 | Mai 2014 : Interpellation zu | Open | Access : Der Bundesrat steht | open |
| [59] - Daniel Hürlimann, Al | 2,174 | 2,174 | : Double dipping in hybrid | open | access – chimera or reality | open |
| [59] - Daniel Hürlimann, Al | 2,200 | 2,200 | SOR-SOCSCI.AOWNTU.v1 12 Nikolaus Kriegeskorte : | Open | Evaluation : A Vision for | open |
| [60] - Fabian Gail, Mark Ve | 7,101 | 7,101 | dort wahrgenommene mangelnde Wertschätzung für | Open | Access zu nennen . Die | open |
| [61] - Christian Hauschke ( | 126 | 126 | websites were examined with the | open | source software webXray regarding their | open |
| [62] - Beat Mattmann (2016) | 411 | 411 | eJournals , Forschungsdatenmanagement und Linked | Open | Data Schritt für Schritt in | open |
| [62] - Beat Mattmann (2016) | 606 | 606 | weniger eBooks und eJournals , | Open | Access oder Forschungsdatenbanken ein Thema | open |
| [62] - Beat Mattmann (2016) | 1,363 | 1,363 | um Normdatenbanken und Linked ( | Open | ) Data bieten sich in | open |
| [64] - Daniel Beucke, Arvid | 670 | 670 | hier mittels einer EtherPad-Installation der | Open | Knowledge Foundation , wurden die | open |
| [64] - Daniel Beucke, Arvid | 2,793 | 2,793 | Denkbar wäre eine Form des | Open | Peer Review , bei dem | open |
| [64] - Daniel Beucke, Arvid | 3,238 | 3,238 | & Felix Lohmeier GbR - | Open | Culture Consulting , Lehmannstr . | open |
| [65] - Armin Talke (2016). | 818 | 818 | Ruf nach neuen Formen des | Open | Access wesentlich beigetragen . Daher | open |
| [66] - Dörte Böhner, Gabrie | 288 | 288 | indexiert durch das Directory of | Open | Access Journals , von INFODATA | open |
| [66] - Dörte Böhner, Gabrie | 344 | 344 | Beiträgen , die in das | Open | Peer Review gehen , die | open |
| [66] - Dörte Böhner, Gabrie | 493 | 493 | sich für Regalreinigung , Linked | Open | Data oder nutzerkuratierte digitale Ausstellungen | open |
| [66] - Dörte Böhner, Gabrie | 776 | 776 | : Double Dipping beim Hybrid | Open | Access – Chimäre oder Realität | open |
| [68] - Gabriele Fahrenkrog | 69 | 69 | es sich bei OER ( | Open | Educational Resources ) um Bildungsmedien | open |
| [68] - Gabriele Fahrenkrog | 152 | 152 | ; Lernort ; OER ; | Open | Educational Resources Abstract With the | open |
| [68] - Gabriele Fahrenkrog | 222 | 222 | . Even though OER ( | Open | Educational Ressources ) are educational | open |
| [68] - Gabriele Fahrenkrog | 296 | 296 | Learning Space ; OER ; | Open | Educational Resources Erklärung : Die | open |
| [68] - Gabriele Fahrenkrog | 366 | 366 | Schulung 6 Fazit Literatur Autorin | Open | Educational Resources ( OER ) | open |
| [68] - Gabriele Fahrenkrog | 816 | 816 | seit vielen Jahren erfolgreich für | Open | Access . Dabei hat sich | open |
| [68] - Gabriele Fahrenkrog | 845 | 845 | mittlerweile selbstverständlich geleistet werden . | Open | Access bezieht sich vorrangig auf | open |
| [68] - Gabriele Fahrenkrog | 866 | 866 | Bibliotheken in der Auseinandersetzung mit | Open | Access bislang für sich keinen | open |
| [68] - Gabriele Fahrenkrog | 1,166 | 1,166 | aktuelle UNESCO-Definition besagt : „ | Open | Educational Resources ( OERs ) | open |
| [68] - Gabriele Fahrenkrog | 1,188 | 1,188 | domain or introduced with an | open | license . The nature of | open |
| [68] - Gabriele Fahrenkrog | 1,195 | 1,195 | . The nature of these | open | materials means that anyone can | open |
| [68] - Gabriele Fahrenkrog | 1,266 | 1,266 | was im Detail unter ' | Open | ' , ' Educational ' | open |
| [68] - Gabriele Fahrenkrog | 1,284 | 1,284 | Forderungen an das Kriterium ' | Open | ' variieren . So wird | open |
| [68] - Gabriele Fahrenkrog | 1,333 | 1,333 | werden die Prinzipien von “ | Open | Content “ und Wileys “ | open |
| [68] - Gabriele Fahrenkrog | 1,662 | 1,662 | ' . Der Term ' | Open | Educational Resources ' kann gemäß | open |
| [68] - Gabriele Fahrenkrog | 1,934 | 1,934 | Das Jahr , in dem | Open | Educational Resources in Deutschland ankam | open |
| [68] - Gabriele Fahrenkrog | 2,105 | 2,105 | Länder und des Bundes zu | Open | Educational Resources 2015 die positiven | open |
| [68] - Gabriele Fahrenkrog | 5,300 | 5,300 | Kollegen ( vgl Cape Town | Open | Education Declaration 2007 ) . | open |
| [68] - Gabriele Fahrenkrog | 5,449 | 5,449 | 2014 : 38 ) . | Open | Access startete zunächst auch als | open |
| [68] - Gabriele Fahrenkrog | 5,482 | 5,482 | es eine breite Bewegung für | Open | Access und in Wissenschaftlichen Bibliotheken | open |
| [68] - Gabriele Fahrenkrog | 5,608 | 5,608 | 2014 : Gesellschaftliche Aspekte von | Open | Educational Resources . URL : | open |
| [68] - Gabriele Fahrenkrog | 5,637 | 5,637 | URL : http://buendnis-freie-bildung.de/positionspapier-oer/ Cape Town | Open | Education Declaration 2007 : Unlocking | open |
| [68] - Gabriele Fahrenkrog | 5,646 | 5,646 | : Unlocking the promise of | open | educational resources . ( September | open |
| [68] - Gabriele Fahrenkrog | 5,749 | 5,749 | Das Jahr , in dem | Open | Educational Ressources in Deutschland ankam | open |
| [68] - Gabriele Fahrenkrog | 5,789 | 5,789 | Flimm , Oliver 2014 : | Open | Educational Resources ( OER ) | open |
| [68] - Gabriele Fahrenkrog | 5,806 | 5,806 | Hapke , Thomas 2015 : | Open | Educational Resources und Bibliotheken . | open |
| [68] - Gabriele Fahrenkrog | 5,823 | 5,823 | : Die „ California Digital | Open | Source Library “ : Entstehung | open |
| [68] - Gabriele Fahrenkrog | 5,872 | 5,872 | Hrsg . : Whitepaper : | Open | Educational Resources . Breaking the | open |
| [68] - Gabriele Fahrenkrog | 5,914 | 5,914 | of OER . In : | Open | ED 2010 Proceedings . Barcelona | open |
| [68] - Gabriele Fahrenkrog | 5,955 | 5,955 | Länder und des Bundes zu | Open | Educational Resources ( OER ) | open |
| [68] - Gabriele Fahrenkrog | 6,000 | 6,000 | Sterchl , Silvia 2015 : | Open | Educational Resources ( OER ) | open |
| [68] - Gabriele Fahrenkrog | 6,083 | 6,083 | : Zur Definition von „ | Open | “ in „ Open Educational | open |
| [68] - Gabriele Fahrenkrog | 6,087 | 6,087 | „ Open “ in „ | Open | Educational Resources “ – die | open |
| [68] - Gabriele Fahrenkrog | 6,113 | 6,113 | Neumann , Jan 2013 : | Open | Educational Resources ( OER ) | open |
| [68] - Gabriele Fahrenkrog | 6,166 | 6,166 | Free . The Emerge of | Open | Educational Resources . http://www.oecd.org/edu/ceri/38654317.pdf Plieninger | open |
| [68] - Gabriele Fahrenkrog | 6,178 | 6,178 | Jürgen 2015 : Suche nach | Open | Educational Resources . In : | open |
| [68] - Gabriele Fahrenkrog | 6,219 | 6,219 | Jürgen 2015 / 1 : | Open | Educational Resources als Dienstleistungen von | open |
| [68] - Gabriele Fahrenkrog | 6,347 | 6,347 | Learning 2011 . Guidelines for | Open | Educational Resources ( OER ) | open |
| [68] - Gabriele Fahrenkrog | 6,364 | 6,364 | http://unesdoc.unesco.org/images/0021/002136/213605e.pdf UNESCO 2012 : Weltkongress | Open | Educational Resources ( OER ) | open |
| [68] - Gabriele Fahrenkrog | 6,390 | 6,390 | UNESCO 2015 : What are | Open | Educational Resources ( OERs ) | open |
| [68] - Gabriele Fahrenkrog | 6,410 | 6,410 | , Anita R . : | Open | and Editable : Exploring Library | open |
| [68] - Gabriele Fahrenkrog | 6,418 | 6,418 | : Exploring Library Engagement in | Open | Educational Resource Adoption , Adaption | open |
| [68] - Gabriele Fahrenkrog | 6,497 | 6,497 | , J . : Whitepaper | Open | Educational Resources ( OER ) | open |
| [72] - Martin Wollschläger- | 3,348 | 3,348 | zu Veröffentlichungsverfahren ( v.a . | Open | Access ) und Informationsressourcen sowie | open |
| [73] - Corinna Haas, Rudolf | 410 | 410 | concludes ( 4 ) with | open | questions that arise from the | open |
| [73] - Corinna Haas, Rudolf | 2,619 | 2,619 | cultural precinct encourage discovery always | open | and always on fantastic design | open |
| [73] - Corinna Haas, Rudolf | 9,233 | 9,233 | überhaupt ? Ist dieser ‚ | Open | Space ‛ ein Anliegen der | open |
| [75] - Christian Hauschke, | 100 | 100 | Google Refine beschrieben . Linked | Open | Data , Geographische Daten , | open |
| [75] - Christian Hauschke, | 210 | 210 | VIVO is described . Linked | open | data , geographical data , | open |
| [75] - Christian Hauschke, | 2,732 | 2,732 | technische Vorkenntnisse mit Google / | Open | Refine möglich . Die in | open |
| [75] - Christian Hauschke, | 3,050 | 3,050 | Per 2013 . Evaluation of | Open | Source Data Cleaning Tools : | open |
| [75] - Christian Hauschke, | 3,056 | 3,056 | Source Data Cleaning Tools : | Open | Refine and Data Wrangler . | open |
| [75] - Christian Hauschke, | 3,093 | 3,093 | OpenRefine : A free , | open | source , powerful tool for | open |
| [75] - Christian Hauschke, | 3,145 | 3,145 | Schelper , Katja 2015 . | Open | Refine , in Blümel , | open |
| [77] - Dörte Böhner, Gabrie | 304 | 304 | es zudem , mit dem | Open | Peer Review eine Alternative zu | open |
| [77] - Dörte Böhner, Gabrie | 378 | 378 | , die Informationspraxis auf ihrem | Open | Journal Systems zu hosten . | open |
| [77] - Dörte Böhner, Gabrie | 691 | 691 | dem Thema Double Dipping im | Open | Access . Dabei hat er | open |
| [78] - Rudolf Mumenthaler, | 4,121 | 4,121 | die von Beat Mattmann im | Open | Peer Review geäusserten Überlegungen : | open |
| [79] - Susanne Baudisch, El | 277 | 277 | Digitale Bibliothek , Barrierefreiheit , | Open | Access , Elektronisches Publizieren , | open |
| [79] - Susanne Baudisch, El | 634 | 634 | Digital library , Accessability , | Open | Access , Electronic publishing , | open |
| [79] - Susanne Baudisch, El | 3,455 | 3,455 | Praxis Digitaler Bibliotheken mit dem | Open | Access-Prinzip längst eine spezifische , | open |
| [79] - Susanne Baudisch, El | 3,480 | 3,480 | . Ausgehend von der Budapest | Open | Access Initiative ( BOAI 2002 | open |
| [79] - Susanne Baudisch, El | 3,488 | 3,488 | ( BOAI 2002 ) besagt | Open | Access , dass wissenschaftliche Literatur | open |
| [79] - Susanne Baudisch, El | 3,594 | 3,594 | Deutschland wird das Publizieren im | Open | Access von den großen Wissenschafts- | open |
| [79] - Susanne Baudisch, El | 3,615 | 3,615 | unterstützt , die vielfach eigene | Open | Access-Policies besitzen und bei technischer | open |
| [79] - Susanne Baudisch, El | 3,633 | 3,633 | kooperieren . In ihrer Resolution | Open | Access - Chancen für den | open |
| [79] - Susanne Baudisch, El | 3,657 | 3,657 | Hauptversammlung 2007 ihr Bekenntnis zu | Open | Access als " eine neue | open |
| [79] - Susanne Baudisch, El | 3,699 | 3,699 | der deutschen bzw . weltweiten | Open | Access-Bewegung zeigen , wird die | open |
| [79] - Susanne Baudisch, El | 3,758 | 3,758 | aufgrund weiterreichender Prioritäten im Gesamtkonzept | Open | Access den technischen Barrieren vergleichsweise | open |
| [79] - Susanne Baudisch, El | 3,966 | 3,966 | Infrastrukturen zum Elektronischen Publizieren im | Open | Access . - Und Öffentliche | open |
| [79] - Susanne Baudisch, El | 12,595 | 12,595 | Unterstützung des wissenschaftlichen Publizierens im | Open | Access . Hierbei werden , | open |
| [79] - Susanne Baudisch, El | 12,628 | 12,628 | einen handelt es sich um | Open | Access-Zeitschriften für bestimmte Wissensgebiete ; | open |
| [79] - Susanne Baudisch, El | 13,029 | 13,029 | Publizieren der goldene Weg des | Open | Access ( OA Gold ) | open |
| [79] - Susanne Baudisch, El | 13,053 | 13,053 | Medium , meist in einer | Open | Access-Zeitschrift , zunehmend aber auch | open |
| [79] - Susanne Baudisch, El | 13,083 | 13,083 | die Publikationskosten entsprechend dem gewählten | Open | Access-Geschäftsmodell auf die Autoren bzw | open |
| [79] - Susanne Baudisch, El | 13,274 | 13,274 | zahlreiche OA-Zeitschriften auf Basis von | Open | Journal Systems ( OJS ) | open |
| [79] - Susanne Baudisch, El | 13,288 | 13,288 | vom Public Knowledge Project entwickelte | Open | Source-CMS gilt als das weltweit | open |
| [79] - Susanne Baudisch, El | 13,534 | 13,534 | den weltweit agierenden Vorreitern beim | Open | Access-Publizieren sind die PLOS Journals | open |
| [79] - Susanne Baudisch, El | 13,764 | 13,764 | Herstellungsprozess einer im Sinne des | Open | Access umfassend barrierefreien Zeitschrift kann | open |
| [79] - Susanne Baudisch, El | 14,117 | 14,117 | XProc pipeline , stehen als | Open | Source-Paket zur Verfügung . Hervorzuheben | open |
| [79] - Susanne Baudisch, El | 14,712 | 14,712 | auf dem grünen Weg des | Open | Access ( OA Grün ) | open |
| [79] - Susanne Baudisch, El | 14,749 | 14,749 | auf einem institutionellen oder disziplinären | Open | Access-Dokumentenserver bzw . Repositorium . | open |
| [79] - Susanne Baudisch, El | 15,378 | 15,378 | ( meist Microsoft Word ; | Open | Office ; Adobe InDesign ; | open |
| [79] - Susanne Baudisch, El | 16,035 | 16,035 | Autoren wissenschaftlicher Texte sind etwa | Open | Book Publishers oder OpenEdition Books | open |
| [79] - Susanne Baudisch, El | 16,514 | 16,514 | von E-Books , darunter auch | Open | E-Books an Wissenschaftliche Bibliotheken stellen | open |
| [79] - Susanne Baudisch, El | 19,344 | 19,344 | , http://nbn-resolving.de/urn:nbn:de:0290-opus-14662. Berlin Declaration on | Open | Access to Knowledge in the | open |
| [79] - Susanne Baudisch, El | 19,477 | 19,477 | / . BOAI - Budapest | Open | Access Initiative . 14.02.2002 , | open |
| [79] - Susanne Baudisch, El | 19,962 | 19,962 | EPUB as Publication Format in | Open | Access Journals : Tools and | open |
| [80] - Alexandra Svantje Li | 24 | 24 | ist ein zentrales Argument für | Open | Access . In dieser Untersuchung | open |
| [80] - Alexandra Svantje Li | 104 | 104 | schlecht heraus . Hochschulschrift , | Open | Access Repositorium , Sichtbarkeit Visibility | open |
| [80] - Alexandra Svantje Li | 115 | 115 | is a main argument for | open | access . This paper looks | open |
| [80] - Alexandra Svantje Li | 190 | 190 | theses declines . Thesis , | open | access repository , visibility Inhaltsverzeichnis | open |
| [80] - Alexandra Svantje Li | 254 | 254 | wird als zentraler Vorteil des | Open | Access angeführt . Für die | open |
| [80] - Alexandra Svantje Li | 262 | 262 | . Für die Umsetzung des | Open | Access haben sich in den | open |
| [80] - Alexandra Svantje Li | 278 | 278 | . Zwar sprechen sich die | Open | Access Policies deutscher Universitäten häufig | open |
| [80] - Alexandra Svantje Li | 311 | 311 | Publizieren auf dem oft hochschuleigenen | Open | Access Publikationsserver , in Betracht | open |
| [80] - Alexandra Svantje Li | 418 | 418 | so einfach finden , wie | Open | Access es verspricht ? In | open |
| [80] - Alexandra Svantje Li | 437 | 437 | bisherigen Untersuchungen zur Sichtbarkeit von | Open | Access Publikationen gewonnen , um | open |
| [80] - Alexandra Svantje Li | 552 | 552 | ein häufig genanntes Argument für | Open | Access ist , gibt es | open |
| [80] - Alexandra Svantje Li | 600 | 600 | erster Linie gefragt , ob | Open | Access die Zitationsrate oder den | open |
| [80] - Alexandra Svantje Li | 616 | 616 | im Interesse der Autoren von | Open | Access Artikeln ist . Ein | open |
| [80] - Alexandra Svantje Li | 629 | 629 | wäre für die Befürworter des | Open | Access ein starkes Argument . | open |
| [80] - Alexandra Svantje Li | 674 | 674 | Zusammenhang zwischen einer Veröffentlichung im | Open | Access und einer erhöhten Zitationsrate | open |
| [80] - Alexandra Svantje Li | 712 | 712 | Chance auf Impact wie nicht | Open | Access Journals ( Björk / | open |
| [80] - Alexandra Svantje Li | 730 | 730 | seiner Untersuchung feststellen , dass | Open | Access Artikel zwar häufiger heruntergeladen | open |
| [80] - Alexandra Svantje Li | 754 | 754 | Er schließt daraus , dass | Open | Access es erlaubt , ein | open |
| [80] - Alexandra Svantje Li | 780 | 780 | die ihnen Zugriff auf nicht | Open | Access Veröffentlichungen bieten , ergibt | open |
| [80] - Alexandra Svantje Li | 808 | 808 | erster Linie mit Artikeln in | Open | Access Journals und nicht mit | open |
| [80] - Alexandra Svantje Li | 1,044 | 1,044 | wissenschaftlichen Dokumenten , die in | Open | Access erschienen sind , haben | open |
| [80] - Alexandra Svantje Li | 1,288 | 1,288 | , dass die Sichtbarkeit von | Open | Access Hochschulschriften auf institutionellen Repositorien | open |
| [80] - Alexandra Svantje Li | 1,402 | 1,402 | der Sichtbarkeit von Monographien im | Open | Access ( Thiessen 2013 ) | open |
| [80] - Alexandra Svantje Li | 1,564 | 1,564 | Repositorien für die Veröffentlichung von | Open | Access Publikationen ( DINI 2014a | open |
| [80] - Alexandra Svantje Li | 3,094 | 3,094 | Bei der Suche in der | Open | Access Suchmaschine BASE konnten keines | open |
| [80] - Alexandra Svantje Li | 4,501 | 4,501 | David ( 2012 ) : | Open | Access versus subscription journals : | open |
| [80] - Alexandra Svantje Li | 4,570 | 4,570 | . ( 2011 ) : | Open | access , readership , citations | open |
| [80] - Alexandra Svantje Li | 4,724 | 4,724 | : Getting cited : Does | open | access help ? In : | open |
| [80] - Alexandra Svantje Li | 4,813 | 4,813 | von wissenschaftlichen Inhalten in deutschen | Open | Access Repositorien . Vortrag auf | open |
| [80] - Alexandra Svantje Li | 4,996 | 4,996 | . Verfügbar unter : http://de.onpage.org/wiki/Sichtbarkeitsindex | Open | AIRE ( 2014 ) : | open |
| [80] - Alexandra Svantje Li | 5,181 | 5,181 | : Charts - Usage of | Open | Access Repository Software - Worldwide | open |
| [81] - Bernhard Mittermaier | 19 | 19 | : http://journals.ub.uni-heidelberg.de/index.php/ip/article/view/18274/13107 Bernhard MITTERMAIER1 Hybrid | Open | Access steht in einer heftigen | open |
| [81] - Bernhard Mittermaier | 124 | 124 | vollständig zu erstatten . Hybrid | Open | Access , Double Dipping , | open |
| [81] - Bernhard Mittermaier | 139 | 139 | pros and cons of hybrid | open | access are heavily disputed . | open |
| [81] - Bernhard Mittermaier | 202 | 202 | using hypothetical examples of hybrid | open | access publication in their journals | open |
| [81] - Bernhard Mittermaier | 228 | 228 | be fully offsetting their hybrid | open | access income , or making | open |
| [81] - Bernhard Mittermaier | 239 | 239 | no additional charge for hybrid | open | access at all , for | open |
| [81] - Bernhard Mittermaier | 276 | 276 | to some extent . Hybrid | Open | Access , Double Dipping , | open |
| [81] - Bernhard Mittermaier | 313 | 313 | Forschungszentrums Jülich , der Hybrid | Open | Access nicht finanziert . Der | open |
| [81] - Bernhard Mittermaier | 358 | 358 | . 1 Einleitung 2 Hybrid | Open | Access ( HOA 2.1 Hybrid | open |
| [81] - Bernhard Mittermaier | 364 | 364 | Access ( HOA 2.1 Hybrid | Open | Access in der Diskussion 2.2 | open |
| [81] - Bernhard Mittermaier | 412 | 412 | Hybrid-Angebot mit No-Double-Dipping-Policy Quellen Autor | Open | Access “ ( OA ) | open |
| [81] - Bernhard Mittermaier | 428 | 428 | in der Erklärung der Budapest | Open | Access Initiative , dass wissenschaftliche | open |
| [81] - Bernhard Mittermaier | 501 | 501 | sind . “ ( Budapest | Open | Access Initiative 2002 ) . | open |
| [81] - Bernhard Mittermaier | 560 | 560 | nicht im grünen Weg des | Open | Access in fachlichen oder institutionellen | open |
| [81] - Bernhard Mittermaier | 654 | 654 | dann wird ihr Artikel sofort | Open | Access zugänglich . Oder sie | open |
| [81] - Bernhard Mittermaier | 697 | 697 | Ursprung des Begriffs „ Hybrid | Open | Access “ ist . Die | open |
| [81] - Bernhard Mittermaier | 863 | 863 | selbst wenn die Begrifflichkeit „ | Open | Access “ noch nicht existierte | open |
| [81] - Bernhard Mittermaier | 1,029 | 1,029 | Teil erheblich ; das „ | Open | Access Directory “ zählt 11 | open |
| [81] - Bernhard Mittermaier | 1,038 | 1,038 | zählt 11 verschiedene Varianten ( | Open | Access Directory 2014 ) . | open |
| [81] - Bernhard Mittermaier | 1,493 | 1,493 | Healthcare offenbar fremd : „ | Open | Access is an arrangement where | open |
| [81] - Bernhard Mittermaier | 1,589 | 1,589 | hat in seinem “ SPARC | Open | Access Newsletter ” schon 2006 | open |
| [81] - Bernhard Mittermaier | 1,764 | 1,764 | HOA in ihrem Förderprogramm „ | Open | Access Publizieren “ aus : | open |
| [81] - Bernhard Mittermaier | 1,784 | 1,784 | nach dem Modell des " | Open | Choice " ist nicht förderfähig | open |
| [81] - Bernhard Mittermaier | 1,841 | 1,841 | working and viable pathway to | Open | Access . Any model for | open |
| [81] - Bernhard Mittermaier | 1,849 | 1,849 | Any model for transition to | Open | Access supported by Science Europe | open |
| [81] - Bernhard Mittermaier | 1,949 | 1,949 | veröffentlicht . Er bezeichnet Gold | Open | Access als idealen Weg zur | open |
| [81] - Bernhard Mittermaier | 2,007 | 2,007 | eigene “ RCUK Policy on | Open | Access ” entsprechend angepasst . | open |
| [81] - Bernhard Mittermaier | 2,468 | 2,468 | to its level of Gold | open | access publication with that publisher | open |
| [81] - Bernhard Mittermaier | 2,491 | 2,491 | Danny Kingsley von der Australian | Open | Access Support Group : “ | open |
| [81] - Bernhard Mittermaier | 2,694 | 2,694 | Campbell in seinem Beitrag „ | Open | Access in the UK – | open |
| [81] - Bernhard Mittermaier | 3,044 | 3,044 | und ihr Status bezüglich Hybrid | Open | Access gemäß den Angaben auf | open |
| [81] - Bernhard Mittermaier | 3,605 | 3,605 | für die APCs bei Hybrid | Open | Access wie auch bei Gold | open |
| [81] - Bernhard Mittermaier | 3,611 | 3,611 | Access wie auch bei Gold | Open | Access gewährt werde , wenn | open |
| [81] - Bernhard Mittermaier | 3,645 | 3,645 | c ) Verlage mit Hybrid | Open | Access und No-Double-Dipping-Policy Die Verlage | open |
| [81] - Bernhard Mittermaier | 3,939 | 3,939 | : „ Uptake of the | open | access option will be monitored | open |
| [81] - Bernhard Mittermaier | 3,974 | 3,974 | prices . The number of | Open | Access articles is only one | open |
| [81] - Bernhard Mittermaier | 4,419 | 4,419 | subskribieren , Gutscheine für Hybrid | Open | Access-Publikationen in gleicher Höhe zur | open |
| [81] - Bernhard Mittermaier | 4,525 | 4,525 | , RSC considers the author-pays | open | access model to be an | open |
| [81] - Bernhard Mittermaier | 4,563 | 4,563 | right to withdraw the author-pays | open | access model at any stage | open |
| [81] - Bernhard Mittermaier | 5,654 | 5,654 | , die Zeitschrift vollständig auf | Open | Access umzustellen . 40 Davon | open |
| [81] - Bernhard Mittermaier | 6,415 | 6,415 | den vom adressierten Verlag vereinnahmten | Open | Access-Gebühren geschehe , wenn die | open |
| [81] - Bernhard Mittermaier | 6,841 | 6,841 | , liberale Regelungen zum Green | Open | Access , CC-BY-Lizenz beim Gold | open |
| [81] - Bernhard Mittermaier | 6,847 | 6,847 | Access , CC-BY-Lizenz beim Gold | Open | Access , … ) kompensiert | open |
| [81] - Bernhard Mittermaier | 7,334 | 7,334 | Subskriptionsgebühren entsprechend der Zahl der | Open | Choice-Artikel reduziert . Allerdings gibt | open |
| [81] - Bernhard Mittermaier | 7,884 | 7,884 | Zusammenhang mit dem „ Online | Open | Adjustment “ , so ergeben | open |
| [81] - Bernhard Mittermaier | 7,905 | 7,905 | . Allerdings reflektiert das Online | Open | Adjustment nicht einmal annähernd den | open |
| [81] - Bernhard Mittermaier | 7,948 | 7,948 | während der Listenpreis trotz Online | Open | Adjustment um 4,5 % stieg | open |
| [81] - Bernhard Mittermaier | 8,650 | 8,650 | die Frage , ob Hybrid | Open | Access auch ohne Gebühren in | open |
| [81] - Bernhard Mittermaier | 8,669 | 8,669 | Fällen die Publikationsgebühren in Gold | Open | Access-Zeitschriften des gleichen Verlags übersteigen | open |
| [81] - Bernhard Mittermaier | 8,753 | 8,753 | alle IP-Adressen ( = Gold | Open | Access ) kann nicht größer | open |
| [81] - Bernhard Mittermaier | 8,857 | 8,857 | als die Zeitschrift auf Gold | Open | Access umzustellen . Er müsste | open |
| [81] - Bernhard Mittermaier | 8,908 | 8,908 | . Insgesamt scheitert somit Hybrid | Open | Access zu kostendeckenden Gebühren an | open |
| [81] - Bernhard Mittermaier | 8,921 | 8,921 | Haltung der Verlage und Hybrid | Open | Access zu den aktuell verlangten | open |
| [81] - Bernhard Mittermaier | 8,969 | 8,969 | ich eine Übersicht zu Hybrid | Open | Access–Angeboten verschiedener Verlage . Auf | open |
| [81] - Bernhard Mittermaier | 8,992 | 8,992 | Publikation von Zeitschriftenartikeln im Hybrid | Open | Access anbieten . Sollte dies | open |
| [81] - Bernhard Mittermaier | 9,022 | 9,022 | ich eine Übersicht zu Hybrid | Open | Access-Angeboten verschiedener Verlage unter Einschluss | open |
| [81] - Bernhard Mittermaier | 9,055 | 9,055 | abhängt , wie viele Hybrid | Open | Access-Artikel publiziert wurden . Bei | open |
| [81] - Bernhard Mittermaier | 9,117 | 9,117 | der zufolge Sie für Hybrid | Open | Access-Artikel nicht zweimal kassieren ( | open |
| [81] - Bernhard Mittermaier | 9,214 | 9,214 | und der Helmholtz-Gemeinschaft gegenüber Hybrid | Open | Access im Allgemeinen sowie bezüglich | open |
| [81] - Bernhard Mittermaier | 9,626 | 9,626 | mit den von Ihnen vereinnahmten | Open | Access-Gebühren , wenn Sie die | open |
| [81] - Bernhard Mittermaier | 9,897 | 9,897 | 2013 ) : Proportion of | Open | Access Peer-Reviewed Papers at the | open |
| [81] - Bernhard Mittermaier | 9,933 | 9,933 | ) : Continued adventures in | open | access : 2009 perspective . | open |
| [81] - Bernhard Mittermaier | 9,967 | 9,967 | : The hybrid model for | open | access publication of scholarly articles | open |
| [81] - Bernhard Mittermaier | 10,004 | 10,004 | am 17.01.2015 ) . Budapest | Open | Access Initiative ( 2002 ) | open |
| [81] - Bernhard Mittermaier | 10,037 | 10,037 | ' toolkit for managing hybrid | open | access . Insights 26 ( | open |
| [81] - Bernhard Mittermaier | 10,185 | 10,185 | the Academic Journal Publisher and | Open | Access Publishing Models . International | open |
| [81] - Bernhard Mittermaier | 10,221 | 10,221 | 2014 ) : The Hybrid | Open | Access Citation Advantage : How | open |
| [81] - Bernhard Mittermaier | 10,253 | 10,253 | Zugriff am 17.01.2015 ) . | Open | Access Directory ( 2014 ) | open |
| [81] - Bernhard Mittermaier | 10,281 | 10,281 | 2010 ) : Paying for | open | access ? Institutional funding streams | open |
| [81] - Bernhard Mittermaier | 10,332 | 10,332 | transforming journals from closed to | open | access . Learned Publishing 16 | open |
| [81] - Bernhard Mittermaier | 10,393 | 10,393 | ) : Licensing Revisited : | Open | Access Clauses in Practice . | open |
| [81] - Bernhard Mittermaier | 10,428 | 10,428 | Publishers with Paid Options for | Open | Access . http://www.sherpa.ac.uk/romeo/PaidOA.php ( Zugriff | open |
| [81] - Bernhard Mittermaier | 10,454 | 10,454 | ) : A study of | open | access journals using article processing | open |
| [81] - Bernhard Mittermaier | 10,497 | 10,497 | ) : Bethesda Statement on | Open | Access Publishing , edited by | open |
| [81] - Bernhard Mittermaier | 10,521 | 10,521 | Peter ( 2012 ) : | Open | Access : MIT Press essential | open |
| [81] - Bernhard Mittermaier | 10,543 | 10,543 | ( 2010 ) : The | Open | Access citation advantage : Studies | open |
| [81] - Bernhard Mittermaier | 10,652 | 10,652 | zu Stand und Entwicklung von | Open | Access vgl . ( Suber | open |
| [81] - Bernhard Mittermaier | 10,668 | 10,668 | laufend aktualisierte Bibliographie zu Hybrid | Open | Access wird innerhalb des Open | open |
| [81] - Bernhard Mittermaier | 10,673 | 10,673 | Open Access wird innerhalb des | Open | Access Tracking Project erstellt und | open |
| [81] - Bernhard Mittermaier | 10,710 | 10,710 | welcher mit einem Icon „ | Open | Access “ gekennzeichnet ist . | open |
| [81] - Bernhard Mittermaier | 11,013 | 11,013 | Ritt , Executive Vice President | Open | Access & Marketing Services , | open |
| [81] - Bernhard Mittermaier | 11,121 | 11,121 | 36 Marianne Haska , Institutional | Open | Access Consultant Royal Society , | open |
| [81] - Bernhard Mittermaier | 11,226 | 11,226 | kein besonders überzeugendes Bekenntnis zu | Open | Access ! 41 http://royalsocietypublishing.org/librarians/transparent-pricing ( | open |
| [81] - Bernhard Mittermaier | 11,272 | 11,272 | Waivers oder die bereits erwähnten | Open | Choice-Projekte des Springer-Verlags mit verschiedenen | open |
| [81] - Bernhard Mittermaier | 11,372 | 11,372 | Angaben zu den „ Online | Open | Adjustments 2014 “ ist im | open |
| [81] - Bernhard Mittermaier | 11,780 | 11,780 | be fully offsetting their hybrid | open | access income , or making | open |
| [81] - Bernhard Mittermaier | 11,791 | 11,791 | no additional charge for hybrid | open | access at all , for | open |
| [82] - Ute Engelkenmeier (2 | 1,515 | 1,515 | Vortrag über MOOCs ( massive | open | online courses ) neue Wege | open |
| docname | from | to | pre | keyword | post | pattern |
|---|---|---|---|---|---|---|
| [1] - Karsten Schuldt (202 | 5,861 | 5,861 | Raum . Bibliothek Forschung und | Praxis | 45 , 1 , 125–134 | praxis* |
| [4] - Anette Cordts, Elias | 2,689 | 2,689 | ) Entwicklung von bedarfsorientierten und | praxisnahen | Handreichungen in Zusammenarbeit mit Expert | praxis* |
| [4] - Anette Cordts, Elias | 3,076 | 3,076 | von den Projekten in die | Praxis | zu befördern . Dass mehrere | praxis* |
| [6] - Nicolas Bach (2022). | 345 | 345 | im deutschsprachigen Raum kein ausreichend | praxisorientiertes | als auch offenes Handbuch für | praxis* |
| [7] - Tina Grahl (2021). S | 267 | 267 | nicht überall vollständig in der | Praxis | umgesetzt . ” ( Neschke | praxis* |
| [7] - Tina Grahl (2021). S | 2,457 | 2,457 | Themen Urheberrecht ; gute wissenschaftliche | Praxis | , Zitieren und Plagiatsprüfung und | praxis* |
| [7] - Tina Grahl (2021). S | 4,262 | 4,262 | Themen Urheberrecht ; gute wissenschaftliche | Praxis | , Zitieren und Plagiatsprüfung sowie | praxis* |
| [7] - Tina Grahl (2021). S | 4,294 | 4,294 | Themen Urheberrecht , gute wissenschaftliche | Praxis | , Zitieren und Plagiat einordnet | praxis* |
| [7] - Tina Grahl (2021). S | 4,329 | 4,329 | Plagiatsprüfung , das in der | Praxis | bereits mehrfach durch Promovierende nachgefragt | praxis* |
| [7] - Tina Grahl (2021). S | 5,315 | 5,315 | De Gruyter Saur . ( | Praxiswissen | ) . Hobohm , Hans-Christoph | praxis* |
| [8] - Sarah Dellmann, Arvi | 6,389 | 6,389 | Chance ? ! : Ein | Praxisbericht | aus der Universitätsbibliothek Kassel . | praxis* |
| [9] - Berfu Erdogan, Chris | 2,081 | 2,081 | eher wird dies in der | Praxis | wahrscheinlich sein . Als „ | praxis* |
| [10] - Grischa Fraumann, Ch | 2,012 | 2,012 | ) . Usability-Tests in der | Praxis | – ein Werkstattbericht des Projekts | praxis* |
| [12] - Jana Madlen Schütte | 915 | 915 | „ Schnittstelle von Wissenschaft und | Praxis | " definiert , eignet sie | praxis* |
| [12] - Jana Madlen Schütte | 948 | 948 | * innen berichten aus der | Praxis | und geben eine Bestandsaufnahme ihrer | praxis* |
| [12] - Jana Madlen Schütte | 1,330 | 1,330 | ein . Das Besondere dieses | Praxisbeispiels | ist die Organisation und Verantwortung | praxis* |
| [13] - Thomas Mutschler (20 | 4,801 | 4,801 | und Zugänglichkeit in der wissenschaftlichen | Praxis | . KIT Scientific Publishing , | praxis* |
| [15] - Wolf Christoph Seife | 7,449 | 7,449 | Publikationswesens . Bibliothek Forschung und | Praxis | 42 ( 1 ) , | praxis* |
| [15] - Wolf Christoph Seife | 7,598 | 7,598 | Vergangenheit . Bibliothek Forschung und | Praxis | 37 ( 1 ) , | praxis* |
| [16] - Martin Munke, Daniel | 7,866 | 7,866 | . Bibliotheken als Orte kuratorischer | Praxis | ( Bibliotheks- und Informationspraxis , | praxis* |
| [16] - Martin Munke, Daniel | 8,442 | 8,442 | Erbes in Sachsen . Ein | Praxisbericht | . In Bibliothek . Forschung | praxis* |
| [16] - Martin Munke, Daniel | 8,449 | 8,449 | In Bibliothek . Forschung & | Praxis | 44 , 3 , 339–347 | praxis* |
| [16] - Martin Munke, Daniel | 8,487 | 8,487 | In Bibliothek . Forschung & | Praxis | 38 , 1 , 83–92 | praxis* |
| [16] - Martin Munke, Daniel | 8,716 | 8,716 | ( Hg . ) . | Praxishandbuch | Open Access . Berlin / | praxis* |
| [16] - Martin Munke, Daniel | 9,647 | 9,647 | ( Hg . ) . | Praxishandbuch | Open Access . Berlin / | praxis* |
| [17] - Colette Knight, Tama | 2,798 | 2,798 | wie sie dies in der | Praxis | umsetzen können . Eine der | praxis* |
| [18] - Markus Putnings (202 | 685 | 685 | Ideen kann z.B . das | Praxishandbuch | Informationsmarketing ( Schade & Georgy | praxis* |
| [18] - Markus Putnings (202 | 1,121 | 1,121 | Hg . ) 2019 . | Praxishandbuch | Informationsmarketing : Konvergente Strategien , | praxis* |
| [20] - Stefanie Hanneken, A | 4,494 | 4,494 | nur schwer mit der verlegerischen | Praxis | der Frontlistproduktion vereinbaren lässt , | praxis* |
| [21] - Claudia Frick (2020) | 319 | 319 | wissenschaftliche Arbeiten und die wissenschaftliche | Praxis | angeht . Nicht zuletzt dank | praxis* |
| [21] - Claudia Frick (2020) | 3,290 | 3,290 | , durchaus der gängigen wissenschaftlichen | Praxis | des Peer-Reviews folgte , 6 | praxis* |
| [23] - Franziska Altemeier, | 251 | 251 | ersten Tages fanden Fortbildungsveranstaltungen und | Praxisworkshops | statt . Neben der jährlich | praxis* |
| [25] - Jens Bemme (2020). # | 3,230 | 3,230 | Gelegenheiten Publikationen gezielt als performative | Praxis | in der Wissenschaftskommunikation zu nutzen | praxis* |
| [26] - Stefanie Spiegelberg | 145 | 145 | 4 Fluide Bibliothek in der | Praxis | – Voraussetzungen und Auswirkungen 4.1 | praxis* |
| [26] - Stefanie Spiegelberg | 732 | 732 | Fluide Bibliothekskonzepte sind in der | Praxis | noch selten und auch in | praxis* |
| [26] - Stefanie Spiegelberg | 2,063 | 2,063 | Basis von bereits in der | Praxis | erprobten Umsetzungen fluider Bestandskonzepte - | praxis* |
| [26] - Stefanie Spiegelberg | 2,080 | 2,080 | Es gibt jedoch in der | Praxis | auch Bedenken gegenüber fluiden Aufstellungskonzepten | praxis* |
| [31] - Karsten Schuldt (202 | 3,537 | 3,537 | Aufgabe . Teilweise wird die | Praxisnähe | des jeweiligen Buches gelobt , | praxis* |
| [31] - Karsten Schuldt (202 | 10,769 | 10,769 | sichern . Bibliothek Forschung und | Praxis | 43 , 2 , 332–347 | praxis* |
| [33] - Christian Hauschke ( | 4,846 | 4,846 | all diesen Forderungen in der | Praxis | nachgekommen wird , bleibt abzuwarten | praxis* |
| [34] - Alessandro Blasetti, | 260 | 260 | Grundlagen 3 Zweitveröffentlichung in der | Praxis | 3.1 Projekt- und Metadatenakquise 3.1.1 | praxis* |
| [34] - Alessandro Blasetti, | 586 | 586 | . 2011 ) . Die | Praxis | zeigt , dass Open Access | praxis* |
| [34] - Alessandro Blasetti, | 1,113 | 1,113 | scheint es einen Mangel an | praxisnahen | Handreichungen oder gar Arbeitsanleitungen zu | praxis* |
| [34] - Alessandro Blasetti, | 2,245 | 2,245 | Lab organisierenden Einrichtungen in der | Praxis | herangezogen werden ; ergänzend sind | praxis* |
| [34] - Alessandro Blasetti, | 3,047 | 3,047 | Rahmenbedingungen . Erfahrungen aus der | Praxis | zeigen , dass Autor * | praxis* |
| [34] - Alessandro Blasetti, | 3,309 | 3,309 | Haftung liegt . In der | Praxis | hat sich gezeigt , dass | praxis* |
| [34] - Alessandro Blasetti, | 3,552 | 3,552 | Weise statt . In der | Praxis | werden u . a . | praxis* |
| [34] - Alessandro Blasetti, | 4,435 | 4,435 | einem flächendeckenden Zweitveröffentlichungsservice in der | Praxis | umsetzbar ist . Wurde keinerlei | praxis* |
| [34] - Alessandro Blasetti, | 4,866 | 4,866 | ist , dass in der | Praxis | nicht immer einfach zu entscheiden | praxis* |
| [34] - Alessandro Blasetti, | 4,971 | 4,971 | Verlagen verhandeln . In der | Praxis | sind derartige Verhandlungen jedoch eher | praxis* |
| [34] - Alessandro Blasetti, | 6,182 | 6,182 | zweitveröffentlicht wurde . In der | Praxis | kann die Dokumentation unterschiedlich umgesetzt | praxis* |
| [34] - Alessandro Blasetti, | 6,410 | 6,410 | 69 ) . In der | Praxis | nutzen einige Repositorienbetreiber als Grundlage | praxis* |
| [34] - Alessandro Blasetti, | 9,034 | 9,034 | sein , sind in der | Praxis | von Zweitveröffentlichungsservices aber eher überfordernd | praxis* |
| [34] - Alessandro Blasetti, | 9,436 | 9,436 | Bibliotheksurheberrecht : ein Lehrbuch für | Praxis | und Ausbildung . Bock + | praxis* |
| [34] - Alessandro Blasetti, | 10,132 | 10,132 | ( 2017 ) . „ | Praxishandbuch | Open Access ” . Berlin | praxis* |
| [34] - Alessandro Blasetti, | 10,334 | 10,334 | Winfried ( 2014 ) . | Praxiskommentar | zum Urheberrecht . 4 . | praxis* |
| [34] - Alessandro Blasetti, | 13,326 | 13,326 | . Dies wird in der | Praxis | bereits angewendet , siehe etwa | praxis* |
| [36] - Nicole Eichenberger | 3,294 | 3,294 | in größerem Maßstab in der | Praxis | umgesetzt werden , müssten daher | praxis* |
| [36] - Nicole Eichenberger | 3,402 | 3,402 | Bei einer Überführung in die | Praxis | müssten außerdem Fragen der ( | praxis* |
| [36] - Nicole Eichenberger | 4,109 | 4,109 | “ Information – Wissenschaft & | Praxis | 64 , 2-3 : 149-165 | praxis* |
| [38] - Christian Erlinger ( | 697 | 697 | aber dort Anleihe in technologischer | Praxis | bzw . hinsichtlich der Usabililty | praxis* |
| [40] - Christian Hauschke, | 2,699 | 2,699 | : Wissensorganisation für Theorie und | Praxis | . http://doi.org/10.5281/zenodo.1464145 Grundler , Mathias | praxis* |
| [41] - Joanna Einbock, Chri | 483 | 483 | wird vielfältig und in der | Praxis | oft unscharf verwendet . Es | praxis* |
| [41] - Joanna Einbock, Chri | 3,295 | 3,295 | 16 ) . In der | Praxis | stellt sich oft jedoch heraus | praxis* |
| [41] - Joanna Einbock, Chri | 4,537 | 4,537 | für die Forschung und die | Praxis | in diesem Feld an , | praxis* |
| [41] - Joanna Einbock, Chri | 4,734 | 4,734 | im akademischen Sektor in der | Praxis | auswirkt . Auch veränderte Ansprüche | praxis* |
| [42] - Adrian Pohl, Fabian | 2,222 | 2,222 | Autoren oder Schlagwörter , in | praxistauglicher | Art umzusetzen ( ohne URIs | praxis* |
| [44] - Christian Hauschke, | 154 | 154 | Architektur 4 Vitro in der | Praxis | 4.1 Vitro als Fundament für | praxis* |
| [45] - Karsten Schuldt, Azr | 4,357 | 4,357 | zu wenig genau für die | Praxis | formulieren , sodass beispielsweise beim | praxis* |
| [45] - Karsten Schuldt, Azr | 4,456 | 4,456 | , diese aber in der | Praxis | nicht wirklich zur Barrierefreiheit verhelfen | praxis* |
| [45] - Karsten Schuldt, Azr | 5,866 | 5,866 | und Beschäftigten im Spiegel der | Praxis | ‟ . Weinheim ; Basel | praxis* |
| [45] - Karsten Schuldt, Azr | 5,918 | 5,918 | . „ Forschungsmethoden in die | Praxisausbildung | einbinden ? Ansätze an der | praxis* |
| [46] - Karsten Schuldt, Rud | 1,014 | 1,014 | Projekt , welches Fachliteratur und | Praxis | miteinander verband . Der Text | praxis* |
| [46] - Karsten Schuldt, Rud | 1,742 | 1,742 | Makerspaces geäussert , in der | Praxis | schien jedoch oft das Interesse | praxis* |
| [46] - Karsten Schuldt, Rud | 8,212 | 8,212 | begreifen – in der bibliothekarischen | Praxis | das Lesen und Nutzen von | praxis* |
| [47] - Jakob Voß, Laura Bod | 509 | 509 | Methoden des Projektmanagements in die | Praxis | umzusetzen . Für das Sommersemester | praxis* |
| [49] - Jana Mersmann, Chris | 467 | 467 | Motto „ Forschungsinformationen in der | Praxis | “ , wobei die Förderung | praxis* |
| [50] - Christian Wilke, Reg | 1,214 | 1,214 | noch evaluiert werden . In | Praxissessions | hatten die Teilnehmer des Workshops | praxis* |
| [51] - Gabriele Fahrenkrog, | 779 | 779 | und Autoren berichten aus der | Praxis | und setzen sich in ihren | praxis* |
| [51] - Gabriele Fahrenkrog, | 995 | 995 | positives Fazit . In ihrem | Praxisbericht | zu Openness in den Künsten | praxis* |
| [51] - Gabriele Fahrenkrog, | 1,315 | 1,315 | in den Künsten - Ein | Praxisbericht | der Mediathek HGK FHNW Basel | praxis* |
| [52] - Eckhart Arnold, Stef | 116 | 116 | Einsatz von Permalinks in der | Praxis | : Erst Permalinks machen Internetquellen | praxis* |
| [52] - Eckhart Arnold, Stef | 218 | 218 | Wir schließen mit einem konkreten | Praxisbeispiel | , dem Aufbau des Publikationsservers | praxis* |
| [52] - Eckhart Arnold, Stef | 712 | 712 | ? 4 Permalinks in der | Praxis | : Worauf zu achten ist | praxis* |
| [52] - Eckhart Arnold, Stef | 761 | 761 | Maschinenlesbarkeit von Permalinks 6 Ein | Praxis-Beispiel | : Warum BV-Nummern nicht für | praxis* |
| [52] - Eckhart Arnold, Stef | 969 | 969 | einer Argumentation in der wissenschaftlichen | Praxis | erheblich vereinfachen und beschleunigen . | praxis* |
| [52] - Eckhart Arnold, Stef | 997 | 997 | digitale Publikation ? Und welchen | Praxis-Regeln | sollten Informationsdienste wie Bibliotheken , | praxis* |
| [52] - Eckhart Arnold, Stef | 1,658 | 1,658 | Inhalt verweist . In der | Praxis | existieren dabei Grauzonen , weil | praxis* |
| [52] - Eckhart Arnold, Stef | 4,383 | 4,383 | gilt es aber als gute | Praxis | DOIs als URL , d.h | praxis* |
| [52] - Eckhart Arnold, Stef | 6,053 | 6,053 | demgegenüber die noch weithin anzutreffende | Praxis | , beim Verweis auf Netzseiten | praxis* |
| [52] - Eckhart Arnold, Stef | 7,446 | 7,446 | eines elektronischen Dokuments . Die | Praxis | muss zeigen , ob das | praxis* |
| [52] - Eckhart Arnold, Stef | 8,931 | 8,931 | – auch durchaus in der | Praxis | auswirken können . Dieser Unsicherheiten | praxis* |
| [53] - Salome Zehnder (2017 | 3,405 | 3,405 | : Die Fotobefragung in der | Praxis | . Verfügbar unter : http://www.univie.ac.at/visuellesoziologie/Publikation2008/VisSozKolb.pdf | praxis* |
| [56] - Tabea Lurk, Jürgen E | 900 | 900 | Hinzu kommen Theorieinstitute zur Ästhetischen | Praxis | und Theorie sowie zu Experimentellen | praxis* |
| [57] - Christian Kaier (201 | 3,460 | 3,460 | . Bibliothek - Forschung und | Praxis | , 39 : 2 , | praxis* |
| [59] - Daniel Hürlimann, Al | 1,246 | 1,246 | Bernhard Mittermaier hat diese merkwürdige | Praxis | der “ Hybrid-Zeitschriften ” , | praxis* |
| [60] - Fabian Gail, Mark Ve | 11 | 11 | , Mark VETTER Der vorliegende | Praxisbericht | beschreibt die Methode des „ | praxis* |
| [60] - Fabian Gail, Mark Ve | 108 | 108 | ausgewertet . Abschließend werden im | Praxisbericht | zentrale Ergebnisse dieser Interviews vorgestellt | praxis* |
| [60] - Fabian Gail, Mark Ve | 441 | 441 | von Forschung und guter wissenschaftlicher | Praxis | sind daher Anstrengungen notwendig , | praxis* |
| [60] - Fabian Gail, Mark Ve | 5,814 | 5,814 | Bereich Medizin , die wenig | Praxis | im Verfassen wissenschaftlicher Veröffentlichungen hätten | praxis* |
| [60] - Fabian Gail, Mark Ve | 7,196 | 7,196 | zur Datensicherung hinausgehen ; die | Praxis | würde von den jeweiligen Arbeitsgruppen | praxis* |
| [62] - Beat Mattmann (2016) | 73 | 73 | immer unproblematisch . In der | Praxis | zeigt sich jedoch ein kreativer | praxis* |
| [62] - Beat Mattmann (2016) | 684 | 684 | auf die Hürden der alltäglichen | Praxis | eröffnen und durchaus auch Wege | praxis* |
| [62] - Beat Mattmann (2016) | 2,361 | 2,361 | gibt es jedoch in der | Praxis | regelmässig Unsicherheiten und damit auch | praxis* |
| [63] - Karsten Schuldt (201 | 6,985 | 6,985 | Volksschulgesetz keine Bedeutung für die | Praxis | in den Schulen hat . | praxis* |
| [64] - Daniel Beucke, Arvid | 87 | 87 | ergänzen kann . In diesem | Praxisbeitrag | soll über Entstehung und Ablauf | praxis* |
| [64] - Daniel Beucke, Arvid | 244 | 244 | eingereichten Abstracts auf Innovation , | Praxisrelevanz | , Vernetzung und Interdisziplinarität sowie | praxis* |
| [65] - Armin Talke (2016). | 1,063 | 1,063 | Versand auszuschließen , in der | Praxis | nicht angewandt wird , weil | praxis* |
| [65] - Armin Talke (2016). | 1,198 | 1,198 | , dass Schrankenregeln in der | Praxis | auch genutzt werden können . | praxis* |
| [65] - Armin Talke (2016). | 1,777 | 1,777 | Verwaisten Werken als in der | Praxis | zu aufwendig herausgestellt hat , | praxis* |
| [66] - Dörte Böhner, Gabrie | 419 | 419 | , die in ihrem Arbeitsalltag | praxisrelevante | Erfahrungen gesammelt haben , die | praxis* |
| [66] - Dörte Böhner, Gabrie | 653 | 653 | Barrierefreiheit zur Routine machen – | Praxisfall | : Digitale Bibliothek . In | praxis* |
| [66] - Dörte Böhner, Gabrie | 752 | 752 | : Stand der Dinge aus | Praxissicht | . In : Informationspraxis 2 | praxis* |
| [67] - Tim Schumann (2016). | 228 | 228 | Bibliothek , Makerspace Garten 5 | Praxisprojekt | „ Urban Gardening und Öffentliche | praxis* |
| [67] - Tim Schumann (2016). | 7,043 | 7,043 | an der TH Köln als | Praxisprojekt | im Rahmen des Studiums des | praxis* |
| [68] - Gabriele Fahrenkrog | 1,985 | 1,985 | sich mit einem Blog der | Praxis | digital-offener Bildungsmedien8 und mit Hilfe | praxis* |
| [68] - Gabriele Fahrenkrog | 3,565 | 3,565 | aus und für die bibliothekarische | Praxis | künftig auf einer Plattform17 erschlossen | praxis* |
| [68] - Gabriele Fahrenkrog | 6,008 | 6,008 | ( OER ) – ein | Praxisbeispiel | . In : Bibliotheksdienst . | praxis* |
| [68] - Gabriele Fahrenkrog | 6,459 | 6,459 | ( OER ) in der | Praxis | . Berlin : mabb . | praxis* |
| [69] - Simon Schultze (2016 | 3,468 | 3,468 | : Gaming und Bibliotheken . | Praxiswissen | . Berlin : De Gruyter | praxis* |
| [72] - Martin Wollschläger- | 2,433 | 2,433 | einem fachlichen Kontext wird ein | Praxisbezug | hergestellt . Dieser Praxisbezug konstruiert | praxis* |
| [72] - Martin Wollschläger- | 2,437 | 2,437 | ein Praxisbezug hergestellt . Dieser | Praxisbezug | konstruiert die Sinnhaftigkeit der Thematik | praxis* |
| [72] - Martin Wollschläger- | 6,897 | 6,897 | : Monographien zu Forschung und | Praxis | , 1 ) . Taylor | praxis* |
| [73] - Corinna Haas, Rudolf | 1,142 | 1,142 | möglichst eigenständig und kritisch ein | praxisrelevantes | Thema zu bearbeiten . Ein | praxis* |
| [73] - Corinna Haas, Rudolf | 10,679 | 10,679 | an die jeweils moderne und | praxisorientierte | Lehre . Das Thema „ | praxis* |
| [73] - Corinna Haas, Rudolf | 10,752 | 10,752 | intellektuell als Herausforderung als auch | praxisorientiert | für Entscheidungen über die zukünftige | praxis* |
| [73] - Corinna Haas, Rudolf | 12,306 | 12,306 | Bibliothekscafé als dritter Ort : | Praxis-Untersuchungen | über den Zusammenhang und die | praxis* |
| [73] - Corinna Haas, Rudolf | 12,763 | 12,763 | In : Bibliothek Forschung und | Praxis | 38 ( 2014 ) 2 | praxis* |
| [73] - Corinna Haas, Rudolf | 13,393 | 13,393 | ) . Forschungsmethoden in die | Praxisausbildung | einbinden ? : Ansätze an | praxis* |
| [74] - Rudolf Mumenthaler, | 282 | 282 | diesem wird eine zeitgemässe und | praxisrelevante | Ausbildung umgesetzt . Aufgrund sich | praxis* |
| [74] - Rudolf Mumenthaler, | 291 | 291 | Aufgrund sich ändernder Anforderungen der | Praxis | sollte das Curriculum also gerade | praxis* |
| [75] - Christian Hauschke, | 27 | 27 | Quellen wiederzuverwenden . In der | Praxis | kann man dabei auf Konvertierungsprobleme | praxis* |
| [76] - Jens Ambacher, Gabri | 2,595 | 2,595 | möchten . Es wurde die | Praxis | genannt , bei dem sich | praxis* |
| [77] - Dörte Böhner, Gabrie | 789 | 789 | Tagungs- und Werkstattberichte aus der | Praxis | , um die fachliche Diskussion | praxis* |
| [78] - Rudolf Mumenthaler, | 3,973 | 3,973 | : Bibliothek . Forschung und | Praxis | 36 ( 2012 ) 1 | praxis* |
| [79] - Susanne Baudisch, El | 1,690 | 1,690 | erstellt auf der Grundlage von | Praxistests | und im Austausch mit den | praxis* |
| [79] - Susanne Baudisch, El | 3,450 | 3,450 | Webdesigns hat sich in der | Praxis | Digitaler Bibliotheken mit dem Open | praxis* |
| [79] - Susanne Baudisch, El | 4,949 | 4,949 | breitgefächerte Einblicke in Theorie und | Praxis | barrierefreier Gestaltung öffentlicher Kultur- und | praxis* |
| [79] - Susanne Baudisch, El | 5,372 | 5,372 | Und dennoch werden in der | Praxis | einige Bibliotheken unterschiedlichster Träger selbst | praxis* |
| [79] - Susanne Baudisch, El | 5,682 | 5,682 | . Anhand von Testergebnissen und | Praxisbeispielen | sollen der aktuelle Stand der | praxis* |
| [79] - Susanne Baudisch, El | 7,949 | 7,949 | und zumindest anteilig in der | Praxis | angekommen ist . Zunehmend kommen | praxis* |
| [79] - Susanne Baudisch, El | 9,193 | 9,193 | Design für Alle in der | Praxis | . ( Online- ) Kataloge | praxis* |
| [79] - Susanne Baudisch, El | 12,484 | 12,484 | im Netz . In der | Praxis | präsentieren Digitale Bibliotheken deutlich häufiger | praxis* |
| [79] - Susanne Baudisch, El | 12,560 | 12,560 | können lediglich Impulse aufgrund von | Praxistests | und Erfahrungswerten vermittelt werden , | praxis* |
| [79] - Susanne Baudisch, El | 13,647 | 13,647 | von Multimedia ; in der | Praxis | finden sich für EPUB 3 | praxis* |
| [79] - Susanne Baudisch, El | 13,679 | 13,679 | zum gegenwärtigen Zeitpunkt in der | Praxis | am ehesten in der zweiten | praxis* |
| [79] - Susanne Baudisch, El | 13,980 | 13,980 | ein solcher Herstellungsprozess in der | Praxis | einer OA-Zeitschrift umgesetzt werden kann | praxis* |
| [79] - Susanne Baudisch, El | 14,605 | 14,605 | in ihrer PDF-Werkstatt ) neben | Praxistipps | und Angeboten zum Erstellen barrierefreier | praxis* |
| [79] - Susanne Baudisch, El | 15,412 | 15,412 | . Ein Blick in die | Praxis | wissenschaftlichen Arbeitens zeigt aber auch | praxis* |
| [79] - Susanne Baudisch, El | 16,962 | 16,962 | hervorzubringen vermag . In der | Praxis | setzt sich EPUB 3 indes | praxis* |
| [79] - Susanne Baudisch, El | 17,516 | 17,516 | Erstellen barrierefreier E-Books in der | Praxis | umzusetzen , ist beispielsweise das | praxis* |
| [79] - Susanne Baudisch, El | 18,255 | 18,255 | inzwischen umfangreiche Projekterfahrungen vor , | Praxisberichte | anhand ausgewählter Bestände hierzu bietet | praxis* |
| [79] - Susanne Baudisch, El | 18,358 | 18,358 | zu generieren . In der | Praxis | jedoch stellt das Textarchiv ein | praxis* |
| [79] - Susanne Baudisch, El | 18,532 | 18,532 | und -produktion . Ausgehend von | Praxistests | und empirischen Erfahrungswerten wurde für | praxis* |
| [79] - Susanne Baudisch, El | 18,687 | 18,687 | werden . Dies bestätigen die | Praxistests | an den digitalen Angeboten im | praxis* |
| [79] - Susanne Baudisch, El | 19,125 | 19,125 | Durchführung bzw . Begleitung verschiedenster | Praxistests | ( Testpaket 1 ; Tests | praxis* |
| [79] - Susanne Baudisch, El | 21,484 | 21,484 | in XML . Grundlagen , | Praxis | , Referenz . 7 . | praxis* |
| [79] - Susanne Baudisch, El | 21,976 | 21,976 | und Verbandsklagen in Theorie und | Praxis | thematisiert ein Tagungsband ( Weltli | praxis* |
| [80] - Alexandra Svantje Li | 5,054 | 5,054 | . Nutzerorientierung in Wissenschaft und | Praxis | . Heidelberg : Akademische Verlagsgesellschaft | praxis* |
| [81] - Bernhard Mittermaier | 9,166 | 9,166 | Umsetzung der No-Double-Dipping-Policy in der | Praxis | aussieht . Sie können Ihre | praxis* |
| [81] - Bernhard Mittermaier | 10,111 | 10,111 | ? Bibliothek , Forschung und | Praxis | 37 ( 1 ) , | praxis* |
| [82] - Ute Engelkenmeier (2 | 403 | 403 | in unterhaltsamer Weise aus der | Praxis | was bei einem so großen | praxis* |
| [82] - Ute Engelkenmeier (2 | 1,322 | 1,322 | . Ein Beispiel aus der | Praxis | veranschaulichte die Anwendbarkeit : 3D | praxis* |
| [82] - Ute Engelkenmeier (2 | 2,451 | 2,451 | , guten Konzepten aus der | Praxis | , Erkenntnisse aus externer Sicht | praxis* |
Weiterhin lassen sich die Ergebnisse in Plots darstellen. Ich überspringe hier die Wordclouds, weil ich sie für wirklich schlimme Visualisierungen halte. Die gleichen Ergebnisse, die wir in einer Wordcloud sehen würden – nämlich, welche Worte im Korpus vorkommen und wie oft – sind schon weiter oben in einer Tabelle dargestellt und dort viel besser nachzuvollziehen. (Aber wer selber welche erstellen möchte, kann dies mit dem Code im Anhang. Ich habe die betreffende Zeile drin gelassen.)
Sinnvoller scheinen mir «xray»-Plots. In diesen wird, wieder für ausgewählte Tokens, dargestellt, in welchen Dokumenten im Korpus sie verwendet werden und an welcher Position. Damit kann man zum Beispiel sehen, ob bestimmte Begriffe immer am Anfang oder Ende von Texten stehen – in den Einführungen ins Textmining wird auch das gerne anhand von politischen Rede gezeigt, wo sich je nach politischer Richtung der Politiker*innen oft eine verschiedene Verteilung zeigt. Die Rechten erwähnen «Immigration» oft und früh in den Reden, die Linken dagegen «Solidarität» – es ist oft erstaunlich stereotyp.
Aber wie sieht es bei der Informationspraxis aus? Hier drei dieser Plots, wieder für die drei Tokens «bibliothek», «information» und «open».
Was zeigen uns diese Darstellungen? Mir scheint vor allem, dass sich keine eindeutigen Trends beobachten lassen. Es ist nicht so, dass die Begriffe in einem überwiegenden Teil der Texte an bestimmten Stellen vorkommen oder das sich Gruppen von ähnlichen Texten zeigen. Eventuell bräuchte es dazu Texte, die sich besser miteinander vergleichen lassen oder auch viel mehr Texte, die untersucht werden.
Ausserdem: Am folgenden Beispiel wird vielleicht auch klar, dass durch die «geringe» Zahl an Texten in unserem Experiment ein falscher Eindruck entstehen kann. Hier wird die Verteilung des Begriffes «Daten» gezeigt. Man hätte den Eindruck haben können, dass der Begriff recht oft in den Beiträgen in der Informationspraxis vorkommt, was man dahingehend interpretieren könnte, dass sich das Bibliothekswesen auch oft mit «Daten» – wir würden vielleicht an die Forschungsdaten denken – beschäftigt.
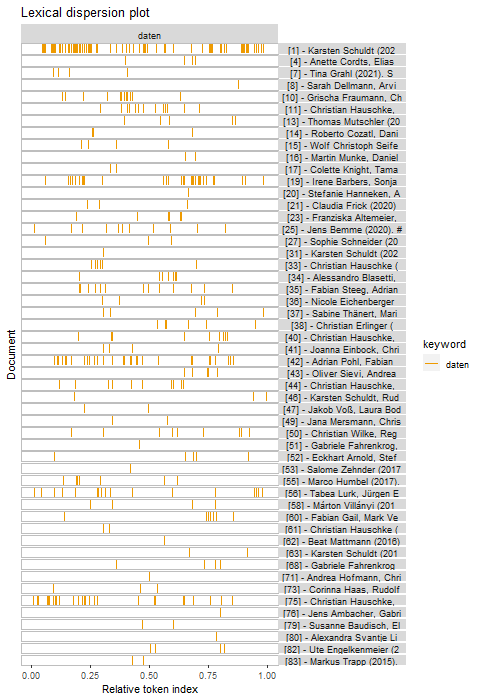
Die graphische Darstellung zeigt aber, dass es ein Text sehr oft «Daten» erwähnt und damit sehr zur «Gesamtzahl» für dieses Wort beigetragen – ein Text, den ich geschrieben habe. Insoweit weiss ich, was in ihm steht und kann sagen, dass es sich dabei immer um Daten aus den Bibliotheksstatistiken des DACH-Raums handelte, nicht um Forschungsdaten. Solche «Ausreisser» kommen wohl in allen Korpussen vor – aber je kleiner der Korpus ist, umso mehr verzerren sie die Ergebnisse.
5. Einige schliessende Anmerkungen
Was sagen uns diese Daten nun? War das Experiment erfolgreich? Mir scheint, es zeigt erstmal, was auch im Bereich Textmining in bibliothekarischen Fachzeitschriften mit einfachen Mittel möglich wäre. Wie gesagt, wurde hier nur etwas Zeit aufgewendet – es wäre also noch viel mehr möglich. Einerseits liesse sich der Korpus noch mehr «reinigen», beispielsweise mit eigenen «Lexika» von Stoppwörtern und definierten Token. Andererseits wären tiefergehende Analysen möglich. So lassen sich mit quanteda auch relativ einfach Untergruppen von Dokumenten bilden und sich dann nach Unterschieden zwischen ihnen fragen. (Ich habe das versucht für die Beiträge, die jeweils in einem Jahr erschienen sind, aber die waren dann jeweils recht wenige, insoweit war das nicht sehr aussagekräftig.) Gleichzeitig lassen sich Textmodelle erstellen, beispielsweise eine «Latent Semantic Analysis», bei der versucht wird, anhand statistisch erfassbarer Merkmale die Dokumente zu gruppieren und herauszuholen, mit welchen Begriffen / Token die jeweiligen Gruppen gekennzeichnet sind. (Wieder wird da in den Einführungen zum Textmining oft anhand von politischen Reden vorgeführt, wo sich dann oft zeigt, dass die politischen Richtungen sich in den statistisch gebildeten Gruppen zeigen, dass sich also der Inhalt auch auf die Struktur der Texte durchschlägt.)
Dies liesse sich mit mehr Zeit und einem grösseren Datensatz erreichen. Das wären auch zwei mögliche Richtungen, in die dieser Versuch hier weitergeführt werden könnte. Eine ganze Anzahl von Zeitschriften aus dem Bibliothekswesen werden auf OJS gehostet (ich denke nur an die Perspektive Bibliothek, die jetzt auch eingestellt ist, oder die o-bib, die noch immer munter weiter erscheint). Diese lassen sich schnell zum Korpus hinzufügen (es bedarf tatsächlich nur des «Eintragen» ihrer Haupt-URLs in eine Funktion, die schon im Code steht. Aber es ist keine Voraussetzung: Auch von anderen Zeitschriften lassen sich Metadaten und Inhalte erheben – vielleicht automatisiert (vor allem, wenn sie eh elektronisch auf einer Plattform erscheinen, die wohl strukturierte Metadaten liefert, wie die libreas mit pandoc und Octopress oder die 0.277 auf pubpub) oder halt per Hand. Man müsste sich auch nicht auf Zeitschriften aus dem Bibliothekswesen beschränken. Es wäre auch interessant, in so einem Korpus Beiträge aus verschiedenen Bereichen zu vergleichen. Ich denke nur an einen möglichen Korpus mit Zeitschriften aus dem Archiv-, Museums-, Kultur- und Bibliotheksbereich. Hier wäre dann schon die Frage interessant, ob, wie oft und wie die jeweils «anderen» Einrichtungen erwähnt werden.
Aber damit sind wir schon bei der Haupterkenntnis dieses Experiments. Während es zeigte, was technisch / softwareseitig einfach möglich ist, fehlte eine klare Fragestellung. Es ist einfach, die Daten, die hier berichtete wurden, zu erstellen. Aber wenn nicht klar ist, was die Daten zeigen / widerlegen / untersuchen sollen, bleiben es «interessante» Daten und Darstellungen. Einige Dinge konnte man einfach aus ihnen ziehen. Aber es wäre sinnvoller, wenn es etwas zum Vergleichen oder Untersuchen gegeben hätte. So wissen wir zum Beispiel nur, wie sich die Themen in der Informationspraxis verteilt haben. Aber wir wissen nicht, ob die Zeitschrift damit herausstach aus den anderen bibliothekarischen Publikationen. War sie anders als andere – und wenn ja, wie? Das liesse sich mit Textmining zumindest zum Teil untersuchen, wenn man mehr Daten versammelt hätte.
So bleibt es ein Einblick in die Zeitschrift; aber immer mit dem Gefühl, dass mehr möglich wäre.
6. Nachwort
Das kleine Experiment hier habe ich auch unternommen, weil ich die Informationspraxis in gewisser Weise die ganze Zeit über «miterlebt» habe. Nie war ich Teil der Redaktion – «aber man kennt sich» (in der «Bibliotheksszene», aber auch bei uns, in der Schweiz), besonders, weil einer der Redakteur*innen und ich eine lange Zeit im gleichen Büro zusammengearbeitet haben. Gleichzeitig habe ich in dieser Zeitschrift ja auch selber publiziert – viel mehr sogar, als mir selber bewusst war. Ich fand es einigermassen unbefriedigend, wie die Zeitschrift einfach sang- und klanglos eingestellt wurde. Nicht, weil ich denke, die ehemalige Redaktion würden uns (der Welt, der Bibliotheksszene) eine Entschuldigung oder Reflexion oder so schulden. Aber… ich hätte mir gewünscht, dass man mehr erfahren würde, wieso es so gekommen ist.
Ich erinnere mich noch, wie die Zeitschrift in der Hoffnung gegründet wurde, eine anderen, neuen, innovativen Publikationsort zu schaffen. Beim ersten Treffen war es offenbar eine grosse Gruppe. Und jetzt? Was ist aus dieser Community geworden?
Was in den Daten hier sichtbar wurde, war, dass Kolleg*innen im Bibliotheksbereich zwar schon publizieren, aber selten. Eher einmal, zweimal, als mehrfach. Das führt aber dazu, dass nur eine kleine Zahl an Autor*innen «den Diskurs» prägen und gleichzeitig vieles, was interessant wäre, nicht gesagt wird. Dabei – darauf deuteten die Daten auch hin – gibt es vieles Unterschiedliche zu sagen. Kurzum: Auch die Analyse hier zeigte, meiner Meinung nach, dass im Bibliothekswesen eine bessere Publikationskultur entstehen muss; eine, die mehr Kolleg*innen dazu bringt, mehr zu veröffentlichen, mehr am Diskurs teilzunehmen. Die Informationspraxis war einst dazu angetreten, dafür einen Ort zu bieten. Das geht jetzt nicht mehr – doch es ist mit einigem, aber auch nicht unendlich viel Aufwand möglich, dies immer wieder neu zu versuchen. Das hat die Informationspraxis auch gezeigt.
Anhang
| index | artic_num | full_arc |
|---|---|---|
| 1 | [1] - Karsten Schuldt (202 | Karsten Schuldt (2022). Waren Öffentliche Bibliotheken im DACH-Raum 2020 in einer Krise? Ein Blick auf die Bibliotheksstatistiken - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/89240/87779 |
| 2 | [2] - Stefan Schmeja, Ulri | Stefan Schmeja, Ulrike Kändler (2022). Seriös oder nicht? Die individuelle Prüfung der Qualität von Zeitschriften an der TIB - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/92475/88599 |
| 3 | [3] - Frank Waldschmidt-Di | Frank Waldschmidt-Dietz (2022). Die #vBIB21 – Weiterbildung auf dem nächsten Level? - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/88845/84471 |
| 4 | [4] - Anette Cordts, Elias | Anette Cordts, Elias Entrup, Anita Eppelin, Christian Hauschke, Daniel Nüst, Katharina Schulz, Niels Taubert, Marcel Wrzesinski (2022). Workshop-Bericht "Journals in der Open-Access-Transformation" - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/89493/85258 |
| 5 | [5] - Maxi Kindling, Dorot | Maxi Kindling, Dorothea Strecker, Lea Maria Ferguson, Hervé L’Hours, Cristina Magder, Rouven Schabinger, Seta Štuhec, Paul Vierkant, Nina Weisweiler (2022). Report on re3data COREF / CoreTrustSeal Workshop on Quality Management at Research Data Repositories - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/93173/88596 |
| 6 | [6] - Nicolas Bach (2022). | Nicolas Bach (2022). Das Handbuch IT in Bibliotheken: Einblicke in den ersten bibliothekarischen Book Sprint Deutschlands - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/94475/89833 |
| 7 | [7] - Tina Grahl (2021). S | Tina Grahl (2021). Schulungs- und Beratungsbedarf von Promovierenden der Ingenieurwissenschaften an Hochschulen für angewandte Wissenschaften - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/81017/77808 |
| 8 | [8] - Sarah Dellmann, Arvi | Sarah Dellmann, Arvid Deppe (2021). Von der Aktion zum Regelbetrieb: Entwicklung eines Zweitveröffentlichungsservices an der UB/LMB Kassel - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/84125/79977 |
| 9 | [9] - Berfu Erdogan, Chris | Berfu Erdogan, Christoph Hornung, Nele Leiner, Markus Trapp, Robert Zepf (2021). Aufbau eines FID-Community-Wikis. : Gemeinsame Kartierung von Services und technischen Infrastrukturen im System der Fachinformationsdienste. - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/82306/78221 |
| 10 | [10] - Grischa Fraumann, Ch | Grischa Fraumann, Christian Hauschke, Svantje Lilienthal, Lambert Heller (2021). Empfehlungen zum Umgang mit szientometrischen Daten und Visualisierungen - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/75717/77513 |
| 11 | [11] - Christian Hauschke, | Christian Hauschke, Petra Kohorst, Steffi Schulz, Sonja Schulze, Daniel Schunk (2021). Bericht vom 5. VIVO-Workshop 2021 - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/83542/78308 |
| 12 | [12] - Jana Madlen Schütte | Jana Madlen Schütte (2021). Editorial - Regionalbibliotheken und die Open-Access-Transformation - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/82191/77543 |
| 13 | [13] - Thomas Mutschler (20 | Thomas Mutschler (2021). Vom Hochschulschriftenserver zum Publikationsfonds – Die Open Access-Transformation an der Thüringer Universitäts- und Landesbibliothek Jena - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/79850/77216 |
| 14 | [14] - Roberto Cozatl, Dani | Roberto Cozatl, Daniel Brenn, Susann Özüyaman (2021). Unterstützung der Open-Access-Transformation in Regionalbibliotheken in Sachsen-Anhalt: die Perspektive der ULB Sachsen-Anhalt - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/80300/77546 |
| 15 | [15] - Wolf Christoph Seife | Wolf Christoph Seifert (2021). Regionalbibliotheken und die Open-Access-Transformation: Ergebnisse einer Umfrage - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/80331/77552 |
| 16 | [16] - Martin Munke, Daniel | Martin Munke, Daniel Fischer (2021). Vom Retrodigitalisat zu Open Access: Landeshistorische Literatur zu Sachsen online unter besonderer Berücksichtigung der Zeitschriftenliteratur - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/80547/77549 |
| 17 | [17] - Colette Knight, Tama | Colette Knight, Tamara Mansaray, Heribert Nacken, Aloys Krieg (2021). Offene Bildungsressourcen an der RWTH Aachen:: Innovationen in der Lehre mit anderen teilen - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/77327/75091 |
| 18 | [18] - Markus Putnings (202 | Markus Putnings (2021). Die eigenständige Fortbildung im Lockdown: Mögliche Themen und Aufträge - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/77808/73444 |
| 19 | [19] - Irene Barbers, Sonja | Irene Barbers, Sonja Rosenberger, Bernhard Mittermaier (2020). Auf dem Weg zur Open Access Transformation: Eine datenbasierte Analyse des DFG-Förderprogramms „Open Access Publizieren“ - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/73240/67953 |
| 20 | [20] - Stefanie Hanneken, A | Stefanie Hanneken, Alexandra Jobmann, Nina Schönfelder (2020). Die transcript OPEN Library Politikwissenschaften: Ein Modell für Open-Access-eBooks in den Geistes- & Sozialwissenschaften - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/66637/65869 |
| 21 | [21] - Claudia Frick (2020) | Claudia Frick (2020). Peer-Review im Rampenlicht: Ein prominentes Fallbeispiel - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/74406/69560 |
| 22 | [22] - Christina Riesenwebe | Christina Riesenweber (2020). Moderationsleitfaden: Tipps zur Gestaltung von Vortragsmoderationen - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/68129/65173 |
| 23 | [23] - Franziska Altemeier, | Franziska Altemeier, Christian Hauschke, Grischa Fraumann, Petra Schön, Daniel Schunk, Graham Triggs, Tatiana Walther (2020). Bericht vom 4. VIVO-Workshop 2019 - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/73938/67683 |
| 24 | [24] - Jana Hentschke, Sylv | Jana Hentschke, Sylvia Hulin, Philipp Zumstein (2020). Erfahrungen bei der Organisation und Durchführung des KIM Workshops 2020 als Online-Veranstaltung - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/73889/67657 |
| 25 | [25] - Jens Bemme (2020). # | Jens Bemme (2020). #Nearby. Landeskunde und Citizen Science mit Pandemie im Frühjahr 2020 - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/73402/69541 |
| 26 | [26] - Stefanie Spiegelberg | Stefanie Spiegelberg (2020). Dynamisch, flexibel, fluid: Neue Aufstellungskonzepte und die Bedeutung virtueller Wissensräume - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/69770/65654 |
| 27 | [27] - Sophie Schneider (20 | Sophie Schneider (2020). Bibliotheks- und InformationswissenschaftlerInnen in der Twittersphäre: Gekürzte und überarbeitete Fassung einer Bachelorarbeit - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/63052/65783 |
| 28 | [28] - Heinz-Jürgen Bove, J | Heinz-Jürgen Bove, Jochen Haug, Barbara Heindl, Indra Heinrich, Belinda Jopp, Christian Mathieu, Heidi Meyer, Gudrun Nelson-Busch, Angela Oehler, Christina Schmitz, Ralf Stockmann, Armin Talke (2020). Krise als Herausforderung und Entwicklungschance: Reaktionen der Staatsbibliothek zu Berlin auf die COVID-19-Pandemie - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/72363/65866 |
| 29 | [29] - Heinz-Jürgen Bove, J | Heinz-Jürgen Bove, Jochen Haug, Barbara Heindl, Indra Heinrich, Belinda Jopp, Christian Mathieu, Heidi Meyer, Gudrun Nelson-Busch, Angela Oehler, Christina Schmitz, Ralf Stockmann, Armin Talke (2020). Krise als Herausforderung und Entwicklungschance: Reaktionen der Staatsbibliothek zu Berlin auf die COVID-19-Pandemie - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/72363/68591 |
| 30 | [30] - Barbara Knorn, Erich | Barbara Knorn, Erich Grevelding (2020). Bibliothek im reduzierten Basisbetrieb - jetzt das Mögliche möglich machen - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/73136/67406 |
| 31 | [31] - Karsten Schuldt (202 | Karsten Schuldt (2020). Die nächste Pandemie kommt bestimmt: Literaturbericht zu Möglichkeiten der Katastrophenplanung für Öffentliche Bibliotheken - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/72410/65954 |
| 32 | [32] - Christian Mathieu (2 | Christian Mathieu (2019). Die Sichtbarmachung des Sichtbaren: Digitalisierung und textuelle Materialitätsforschung - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/63479/59116 |
| 33 | [33] - Christian Hauschke ( | Christian Hauschke (2019). Problematische Aspekte bibliometrie-basierter Forschungsevaluierung - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/49609/49367 |
| 34 | [34] - Alessandro Blasetti, | Alessandro Blasetti, Sandra Golda, Dominic Göhring, Steffi Grimm, Nadin Kroll, Denise Sievers, Michaela Voigt (2019). Smash the Paywalls: Workflows und Werkzeuge für den grünen Weg des Open Access - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/52671/50793 |
| 35 | [35] - Fabian Steeg, Adrian | Fabian Steeg, Adrian Pohl, Pascal Christoph (2019). lobid-gnd – Eine Schnittstelle zur Gemeinsamen Normdatei für Mensch und Maschine - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/52673/51904 |
| 36 | [36] - Nicole Eichenberger | Nicole Eichenberger (2019). Ein Ontologie-Entwurf für die Klassifikation von historischen Wasserzeichen - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/56833/54157 |
| 37 | [37] - Sabine Thänert, Mari | Sabine Thänert, Marina Unger (2019). Linked Data in der iDAI.world: Am Beispiel des Projekts „Gelehrte, Ausgräber und Kunsthändler: Die Korrespondenz des Instituto di Corrispondenza Archeologica als Wissensquelle und Netzwerkindikator“ am Deutschen Archäologischen Institut - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/54291/55655 |
| 38 | [38] - Christian Erlinger ( | Christian Erlinger (2019). Instant-Messenger Bots als alternative Suchoberfläche - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/57941/51609 |
| 39 | [39] - Gabriele Fahrenkrog, | Gabriele Fahrenkrog, Dagmar Schnittker (2019). Austauschen. Kooperieren. Vernetzen. – Der Fachtag Medienkompetenzrahmen NRW in der Stadtbücherei Ibbenbüren - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/58867/52190 |
| 40 | [40] - Christian Hauschke, | Christian Hauschke, Tatiana Walther, Grischa Fraumann, Ina Blümel, Dominik Feldschnieders, Graham Triggs, Qazi Asim Ijaz Ahmad (2019). Bericht vom 3. VIVO-Workshop 2018 - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/61729/54316 |
| 41 | [41] - Joanna Einbock, Chri | Joanna Einbock, Christian Hauschke (2018). Anforderungen an Forschungsinformationssysteme in Deutschland durch Forschende und Forschungsadministration – Zusammenfassung zweier Studien - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/46819/42938 |
| 42 | [42] - Adrian Pohl, Fabian | Adrian Pohl, Fabian Steeg, Pascal Christoph (2018). lobid – Dateninfrastruktur für Bibliotheken - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/52445/49282 |
| 43 | [43] - Oliver Sievi, Andrea | Oliver Sievi, Andreas Ledl, Jonas Wäber (2018). Semantische Technologien für lokale Erschliessungssysteme der Schweiz: Ein Pilotprojekt der Sportmediathek Magglingen und des Basel Register of Thesauri, Ontologies & Classifications (BARTOC.org) - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/48800/47457 |
| 44 | [44] - Christian Hauschke, | Christian Hauschke, Tatiana Walther, Graham Triggs (2018). Vitro - ein universell einsetzbarer Editor für Ontologien und Instanzen - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/49357/49150 |
| 45 | [45] - Karsten Schuldt, Azr | Karsten Schuldt, Azra Bekiri, Jin Chei, Meltem Dincer, Sigrid Freudl, Johannes Hafner, Sinan Meral, Ronnie Vogt, Vrushali Wyssmann, Sabrina Zaugg (2018). Inklusion in Gedächtniseinrichtungen in der Schweiz: Ein Seminarbericht - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/52494/47544 |
| 46 | [46] - Karsten Schuldt, Rud | Karsten Schuldt, Rudolf Mumenthaler (2017). Mobile Makerspaces für kleinere Gemeindebibliotheken: Ein Projektbericht - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/37751/35049 |
| 47 | [47] - Jakob Voß, Laura Bod | Jakob Voß, Laura Bode, Diana Hamasur, Laura Isbanner, Jan Jäger, Ebru Kurtar, Kim Peters, Melis Rufaioglu, Christian Schneevogt, Romy Stelter, Jennifer Wiegand, Ann Christin Wild, Remziye Yildirimer (2017). Erfassung von Wissensorganisationssystemen in BARTOC - Ergebnis eines Projektseminars an der Hochschule Hannover - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/40335/36559 |
| 48 | [48] - Nicole Eichenberger, | Nicole Eichenberger, Christopher Hanna Johnson, Leander Seige (2017). A week of manuscript studies with the digital workspace “mirador@ubleipzig” - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/43293/37629 |
| 49 | [49] - Jana Mersmann, Chris | Jana Mersmann, Christian Hauschke (2017). Tagungsbericht VIVO-Workshop 2017 - “Forschungsinformationen in der Praxis” - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/41926/36809 |
| 50 | [50] - Christian Wilke, Reg | Christian Wilke, Regina Retter (2017). Zitationsdaten extrahieren: halbautomatisch, offen, vernetzt. Ein Workshopbericht - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/43235/37360 |
| 51 | [51] - Gabriele Fahrenkrog, | Gabriele Fahrenkrog, Felix Lohmeier, Sebastian Meyer (2017). Editorial Schwerpunkt “Openness” - Warum Openness in Kultur und Wissenschaft? - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/39826/33838 |
| 52 | [52] - Eckhart Arnold, Stef | Eckhart Arnold, Stefan Müller (2017). Wie permanent sind Permalinks? - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/33483/28258 |
| 53 | [53] - Salome Zehnder (2017 | Salome Zehnder (2017). Fotobefragung in Bibliotheken – Methode zur Erhebung schwer operationalisierbarer Nutzerbedürfnisse wie „Gemütlichkeit“ - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/33575/28849 |
| 54 | [54] - Christian Koller (20 | Christian Koller (2017). Openness oder „nordkoreanische Verhältnisse“? Top-down implementierter Open Access im britischen Hochschulsystem - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/34568/29896 |
| 55 | [55] - Marco Humbel (2017). | Marco Humbel (2017). Open Data an Wissenschaftlichen Bibliotheken der Schweiz - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/34621/30906 |
| 56 | [56] - Tabea Lurk, Jürgen E | Tabea Lurk, Jürgen Enge (2017). Openness in den Künsten – Ein Praxisbericht der Mediathek HGK FHNW Basel - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/35058/32993 |
| 57 | [57] - Christian Kaier (201 | Christian Kaier (2017). Publikationsunterstützung: Die Bibliothek ist nicht genug - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/35225/32987 |
| 58 | [58] - Márton Villányi (201 | Márton Villányi (2017). Ein freies Bibliothekssystem für wissenschaftliche Bibliotheken –Werkstattbericht der IST Austria Library - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/35227/29620 |
| 59 | [59] - Daniel Hürlimann, Al | Daniel Hürlimann, Alexander Grossmann (2017). Open Access als Utopie? - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/33687/28386 |
| 60 | [60] - Fabian Gail, Mark Ve | Fabian Gail, Mark Vetter (2016). Systematische Zielgruppenbefragung - Methode und Ergebnisse von Fokusgruppen-Interviews durch ZB MED - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/30984/27854 |
| 61 | [61] - Christian Hauschke ( | Christian Hauschke (2016). Third-Party-Elemente in deutschen Bibliothekswebseiten - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/32678/27068 |
| 62 | [62] - Beat Mattmann (2016) | Beat Mattmann (2016). Die digitale Zugänglichkeit von Archivalien: Stand der Dinge aus Praxissicht - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/29123/25483 |
| 63 | [63] - Karsten Schuldt (201 | Karsten Schuldt (2016). Erklären, warum Bibliotheken so sind, wie sie sind: Zur Nutzung von Archivmaterialien zur Erklärung des Status Quo von Bibliotheken - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/32472/27030 |
| 64 | [64] - Daniel Beucke, Arvid | Daniel Beucke, Arvid Deppe, Tracy Hoffmann, Felix Lohmeier, Christof Rodejohann, Pascal Ngoc Phu Tu (2016). Anleitung zur Organisation von Webkonferenzen am Beispiel der “Bibcast”-Aktion zum Bibliothekskongress 2016 - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/31976/26301 |
| 65 | [65] - Armin Talke (2016). | Armin Talke (2016). EU-Urheberrechtsreform: Eine Problembeschreibung aus Sicht der Bibliotheken - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/32267/27033 |
| 66 | [66] - Dörte Böhner, Gabrie | Dörte Böhner, Gabriele Fahrenkrog, Christian Hauschke, Lambert Heller, Rudolf Mumenthaler (2016). Editorial – Rückblick und Call for Call for Papers - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/31963/25680 |
| 67 | [67] - Tim Schumann (2016). | Tim Schumann (2016). Urban Gardening und Öffentliche Bibliotheken: Konzeption einer Veranstaltungsreihe in der Stadtbibliothek Bad Oldesloe - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/23822/20621 |
| 68 | [68] - Gabriele Fahrenkrog | Gabriele Fahrenkrog (2016). Lernort Öffentliche Bibliothek und Open Educational Resources (OER) – Zusammenbringen, was zusammen gehört - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/26628/22185 |
| 69 | [69] - Simon Schultze (2016 | Simon Schultze (2016). Videospielturniere in öffentlichen Schweizer Bibliotheken - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/27337/23073 |
| 70 | [70] - Gary Seitz, Barbara | Gary Seitz, Barbara Grossmann (2016). Einfluss von Informationskompetenz-Veranstaltungen auf die Qualität von Masterarbeiten - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/23295/21583 |
| 71 | [71] - Andrea Hofmann, Chri | Andrea Hofmann, Christian Hauschke (2016). Roving Librarians in der Zentralbibliothek der Hochschule Hannover: ein Experiment - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/28559/23968 |
| 72 | [72] - Martin Wollschläger- | Martin Wollschläger-Tigges (2015). Informationssuchverhalten als Grundlage für die Gestaltung von Veranstaltungen zum Erwerb von Informationskompetenz - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/19391/17227 |
| 73 | [73] - Corinna Haas, Rudolf | Corinna Haas, Rudolf Mumenthaler, Karsten Schuldt (2015). Ist die Bibliothek ein Dritter Ort? Ein Seminarbericht - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/23763/19504 |
| 74 | [74] - Rudolf Mumenthaler, | Rudolf Mumenthaler, Bernard Bekavac (2015). Curriculumsreform des Bachelor-Studiengangs Information Science an der HTW Chur - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/20175/16010 |
| 75 | [75] - Christian Hauschke, | Christian Hauschke, Elena Liventsova (2015). Erstellung wiederverwendbarer RDF-Geodaten mit Google Refine - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/23784/18989 |
| 76 | [76] - Jens Ambacher, Gabri | Jens Ambacher, Gabriele Fahrenkrog, Rudolf Mumenthaler, Ruth Schaffer Wüthrich, Karsten Schuldt, Bruno Wüthrich (2015). Workshopbericht: Armut und Bibliotheken (Nürnberg 2015) - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/24186/18660 |
| 77 | [77] - Dörte Böhner, Gabrie | Dörte Böhner, Gabriele Fahrenkrog, Christian Hauschke, Lambert Heller, Rudolf Mumenthaler (2015). Editorial - Willkommen zur ersten Ausgabe der Informationspraxis! - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/18489/12357 |
| 78 | [78] - Rudolf Mumenthaler, | Rudolf Mumenthaler, Karsten Schuldt (2015). Was macht erfolgreiche Bibliothekspolitik aus? Ein Seminarbericht - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/16488/13110 |
| 79 | [79] - Susanne Baudisch, El | Susanne Baudisch, Elke Dittmer, Thomas Kahlisch (2015). Barrierefreiheit zur Routine machen – Praxisfall: Digitale Bibliothek - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/16888/13570 |
| 80 | [80] - Alexandra Svantje Li | Alexandra Svantje Linhart (2015). Eine Untersuchung der Sichtbarkeit von Open-Access Abschlussarbeiten auf deutschen institutionellen Repositorien - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/18627/14107 |
| 81 | [81] - Bernhard Mittermaier | Bernhard Mittermaier (2015). Double Dipping beim Hybrid Open Access – Chimäre oder Realität? - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/18274/13108 |
| 82 | [82] - Ute Engelkenmeier (2 | Ute Engelkenmeier (2015). 7. Wildauer Bibliothekssymposium – RFID und wirklich noch viel mehr … - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/16490/12355 |
| 83 | [83] - Markus Trapp (2015). | Markus Trapp (2015). Die App „Weltbrand 1914“ der SUB Hamburg – Ein Werkstattbericht - https://journals.ub.uni-heidelberg.de/index.php/ip/article/view/17685/12356 |
Klare Vorgaben zur Artikellänge gab es nicht, aber doch Empfehlungen (bis etwa 12.000 Zeichen für Kurzbeiträge und bis etwa 40.000 Zeichen für Fachbeiträge, https://journals.ub.uni-heidelberg.de/index.php/ip/about/submissions). Interessant, dass sich nur 2 von 20 Kurzbeiträgen und 15 von 38 Fachbeiträgen daran gehalten haben…
Hi Karsten,
danke für den sehr ausführlichen Beitrag zu Informationspraxis. Ich habe die Statistiken nur kurz überflogen und werde noch einen genaueren Blick darauf werfen.
@Stefan Schmeja: Die Redaktion hatte damals entschieden, da kein Papier geschwärzt wird, sind die angegebenen Artikellängen nur Richtwerte.
Auf Bibliotheksbubble hatte ich nur kurz etwas zum Abschied von Informationspraxis geschrieben: https://bibliotheksbubble.de/2023/07/17/ein-community-projekt-endet/ – Es sollte noch einen abschließenden Beitrag geben, aber auch ich habe diesbezüglich nichts mehr gehört.
Moin Karsten! Vielen Dank für Deine spannende Analyse. Ich habe alles bisher nur überflogen, werde es mir aber nochmal genauer anschauen.
Zu folgendem Punkt:
„Ich fand es einigermassen unbefriedigend, wie die Zeitschrift einfach sang- und klanglos eingestellt wurde.“
Ja, wir auch. Und geplant ist auch, sowohl noch einen letzten Artikel aus unserer Pipeline zu veröffentlichen, als auch einen finalen Artikel mit einer Rückschau zu veröffentlichen. Dass es so lange dauert und auch die Kommunikation nicht optimal ist, lässt schon Schlüsse darauf zu, warum wir nicht weitermachen konnten. Wir haben es mit einem kleinen Kernteam einfach nicht mehr geschafft.